






目录
前言
前面已经实现了Mysql数据库的主从复制功能,光有数据库主从复制还不够,还需要实现对数据库的读写分离操作。
Mysql主从复制![]() https://mp.csdn.net/mp_blog/creation/editor/128456196
https://mp.csdn.net/mp_blog/creation/editor/128456196
Sharding-JDBC官方文档![]() https://shardingsphere.apache.org/document/4.1.1/cn/overview/#sharding-jdbc
https://shardingsphere.apache.org/document/4.1.1/cn/overview/#sharding-jdbc
1.为什么要做读写分离
Sharding-JDBC官方说法:
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
Sharding-JDBC读写分离是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。
2.主从复制存在的问题
在主从复制中数据在主节点写入从节点读出,主从节点数据同步可能存在一定的延时,这导致主节点和从节点的数据不一致。对于时效性比较高的查询,一般都会强制走主节点查询。
3.读写分离实现效果
配置一个主节点,两个从节点。增/删/改操作交由主节点完成(对于时效性高的查询也可强制路由到主节点),查询操作交由从节点完成。这样就将数据库的查询压力分担出去了。
4.读写分离配置
4.1:Maven依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.6.RELEASE</version>
</parent>
<dependencies>
<!-- Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- AOP -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- sharding-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-api</artifactId>
<version>4.0.0-RC2</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC2</version>
</dependency>
<!-- Mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- Mybatis plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
<exclusions>
<!-- 排除默认的 HikariCP 数据源,使用druid的数据源 -->
<exclusion>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.9</version>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>4.2:application.yml
spring:
# sharding-jdbc配置
shardingsphere:
# 是否开启SQL显示
props:
sql:
show: true
# 数据源配置
datasource:
names: ds-master,ds-slave1,ds-slave2 # 主从节点名称
# 主节点配置
ds-master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3307/student?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: 123456
# 从节点一配置
ds-slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3308/student?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: 123456
# 从节点二配置
ds-slave2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3309/student?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: 123456
# 读写分离配置
sharding:
master-slave-rules:
ds-master:
# 主库
masterDataSourceName: ds-master
# 从库
slaveDataSourceNames:
- ds-slave1
- ds-slave2
# 从库查询数据的负载均衡算法 目前有2种算法 round_robin(轮询)和 random(随机)
loadBalanceAlgorithmType: round_robin
# Mybatis Plus 配置
mybatis-plus:
configuration:
# 控制台打印完整带参数SQL语句
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 设置当查询结果值为null时,同样映射该查询字段给实体(Mybatis-Plus默认会忽略查询为空的实体字段返回)。
call-setters-on-nulls: true
4.3:Controller
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/stu")
public class StudentController {
@Autowired
private IStudentService stuService;
/** 查询入口 */
@GetMapping("/loadStu")
public Object loadOneStu(){
return stuService.loadOneStu();
}
/** 新增入口 */
@PostMapping("/saveStu")
public void saveStu(){
stuService.saveOneStu();
}
}4.4:Service
4.4.1: Service:
import java.util.Map;
public interface IStudentService {
/** 查询 */
Map loadOneStu();
/** 新增 */
void saveOneStu();
}4.4.2:ServiceImpl:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Map;
@Service
public class StudentServiceImpl implements IStudentService {
@Autowired
private StudentMapper stuMapper;
/** 查询 */
@Override
public Map loadOneStu() {
return stuMapper.loadOneStu();
}
/** 新增 */
@Override
public void saveOneStu() {
stuMapper.saveOneStu();
}
}4.5:Mapper
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.Map;
@Mapper
public interface StudentMapper {
/** 查询 */
@Select("SELECT * FROM stu LIMIT 1")
Map loadOneStu();
/** 新增 */
@Insert("INSERT INTO stu(id,name) VALUES (2,'zs')")
void saveOneStu();
}4.6:启动类
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("cn.cdjs.mapper")
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class);
}
}4.7:启动成功示例图(控制台输出)

5.读写分离测试
5.1:写入测试
POST请求调用:http://localhost:8080/stu/saveStu

5.2:查询测试
GET请求调用:http://localhost:8080/stu/loadStu
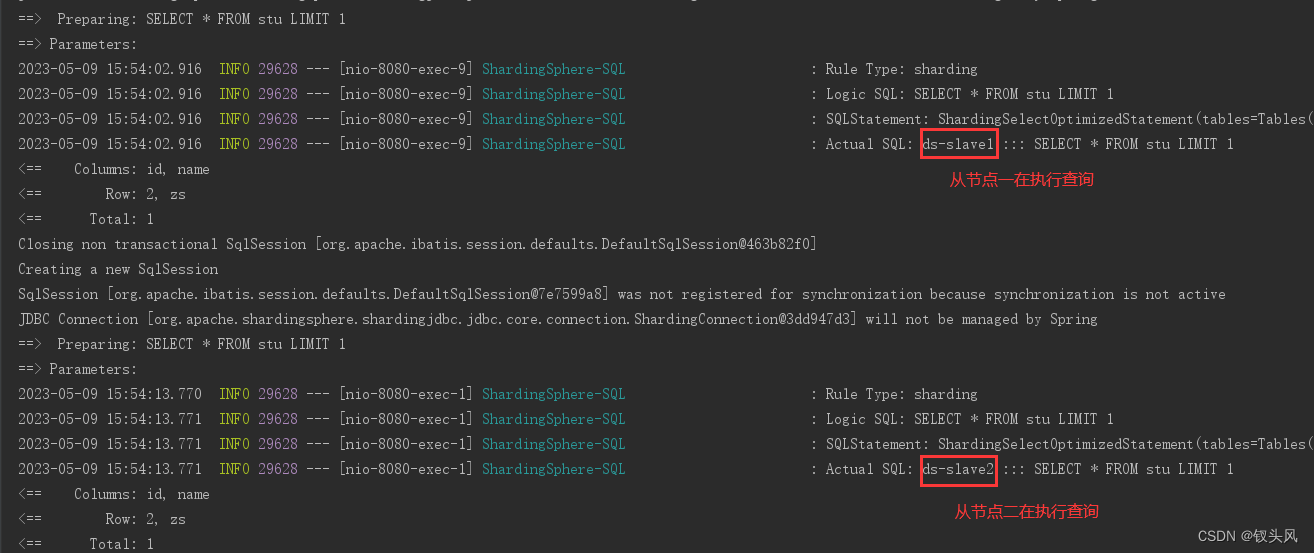
多次调用GET请求查询数据,发现从节点在轮询交替执行查询。
6.读操作强制路由到主节点原因
主从复制,主节点写入从节点读取,由于主节点写入从节点复制有一定延迟。对于一些时效性要求很高的查询,比如我写入了立马就要去查,假如此时从库还未复制主库这条数据从库就不会查询到。而解决此类问题一般都是对时效性比较高的查询强制路由到主节点进行查询(主节点写入当然主节点也能立马查询出来)。当然Sharding-JDBC也支持“强制路由”这个功能。
6.1:强制路由原理
强制路由 - 基于暗示数据分片![]() https://shardingsphere.apache.org/document/4.1.1/cn/manual/sharding-jdbc/usage/hint/
https://shardingsphere.apache.org/document/4.1.1/cn/manual/sharding-jdbc/usage/hint/
基于暗示的数据分片,ShardingSphere在进行Routing时,如果发现LogicTable的TableRule采用了 Hint的分片算法,将会从HintManager中获取分片值进行路由操作。
7.实现读操作强制走主节点
7.1:代码层面实现
Controller
/** 强制路由主节点查询入口 */
@GetMapping("/coerceRouteMasterNodeSelect")
public Object coerceRouteMasterNodeSelect(){
return stuService.coerceRouteMasterNodeSelect();
}ServiceImpl
/** 强制路由主节点查询入口 */
@Override
public Map coerceRouteMasterNodeSelect() {
HintManager.clear();
try(HintManager hintManager = HintManager.getInstance()){
// 设置走主库
hintManager.setMasterRouteOnly();
return stuMapper.loadOneStu();
}
}测试:

7.2:使用AOP定义注解实现
每次强制路由到主节点都需要写上面的代码这是很繁琐的,通过AOP + 注解 我们可以轻松实现强制路由到主节点功能。
7.2.1:定义注解
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 定义注解
*/
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DataSourceMaster {
}7.2.2:定义AOP切面
import org.apache.shardingsphere.api.hint.HintManager;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.util.Objects;
@Component
@Aspect
public class DataSourceMasterAop {
/** 作用范围 */
@Around("execution(* cn.cdjs.service.impl.*.*(..))")
public Object master(ProceedingJoinPoint joinPoint){
// 获取执行方法参数
Object[] args = joinPoint.getArgs();
Object ret = null;
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
// 获取执行方法
Method method = methodSignature.getMethod();
// 获取方法上自定义的“DataSourceMaster”注解
DataSourceMaster shardingJdbcMaster = method.getAnnotation(DataSourceMaster.class);
HintManager hintManager = null;
try {
if (Objects.nonNull(shardingJdbcMaster)) { // 当前方法上有自定义的DataSourceMaster注解
HintManager.clear();
hintManager = HintManager.getInstance();
// 强制路由到主节点
hintManager.setMasterRouteOnly();
}
ret = joinPoint.proceed(args); // 执行目标方法并获取响应对象
}catch (Throwable ex){
System.out.println("Exception Err " + ex);
}finally {
if (Objects.nonNull(shardingJdbcMaster) && Objects.nonNull(hintManager)) {
// 关闭
hintManager.close();
}
}
return ret;
}
}7.2.3:Controller
/** AOP + 注解方式 强制路由主节点查询入口 */
@GetMapping("/coerceRouteMasterNodeSelectByAop")
public Object coerceRouteMasterNodeSelectByAop(){
return stuService.coerceRouteMasterNodeSelectByAop();
}7.2.4:ServiceImpl
/** AOP + 注解方式 强制路由主节点查询入口 */
@DataSourceMaster // 自定义的注解
@Override
public Object coerceRouteMasterNodeSelectByAop() {
return stuMapper.loadOneStu();
}7.2.5:测试

8.模拟测试
8.1:一主两从模拟某个从节点挂掉系统运行情况
8.1.1:关闭其中一个从节点模拟从节点故障宕机
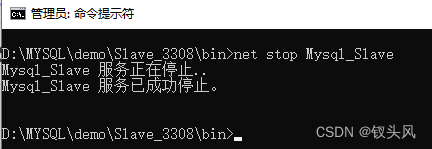
8.1.2:多次请求查询接口(http://localhost:8080/stu/loadStu)
从节点采用的是轮询的方式进行负载均衡,原正常情况下从节点是交替执行,但现在有一个从节点故障了,多次调用发现当轮询到故障的那台从节点上时程序一直拿取不到结果(即不会自动跳过宕机从节点)。

其它说明:
多个从节点负载均衡策略为“轮询”时,不要在Junit单元测试中执行查询方法,这样测试出来的结果一直都是只有一个从节点在执行查询。















 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









