







one-hot编码
-
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
-
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
假设我们有一群学生,他们可以通过四个特征来形容,分别是:
- 性别:[“男”,“女”]
- 年级:[“初一”,“初二”,“初三”]
- 学校:[“一中”,“二中”,“三中”,“四中”]
这时候就可以用one-hot编码的形式来表示了,采用N位状态寄存器来对N个状态进行编码
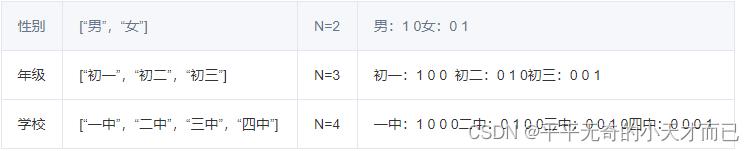
例如:小明->[男,初二,三中] 转化成数字表示为[0 1 2]—>one-hot编码表示为 [1 0 0 1 0 0 0 1 0]
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
# 这里一共有4个数据,3种特征
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
# 这里使用一个新的数据来测试
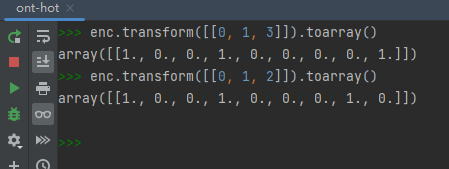
array = enc.transform([[0, 1, 3]]).toarray()
# [[ 1 0 0 1 0 0 0 0 1]]
print(array)
列出矩阵,可以表示为4个数据,3种特征
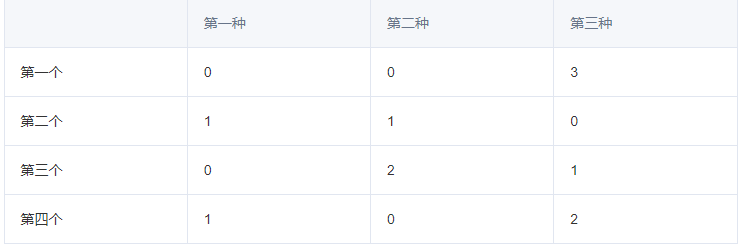
竖着看,可以看出第一种特征中只有0、1两类,第二组有0,、1、2三类,第三种有0、1、2、3四类,因此分别可以用2、3、4个状态类来表示。
| N=2 | 10, 01 |
|---|---|
| N=3 | 100, 010, 001 |
| N=4 | 1000, 0100, 0010, 0001 |
# enc.transform() 就是将[0,1,3]这组特征转换成one hot编码
# toarray()则是转成数组形式
第一个数为0,对应第一种特征则为 1 0;
第二个数为1,对应第二种特征则为 0 1 0;
第三个数为3,对应第三种特征则为 0 0 0 1。
所以最后的输出为 [[1 0 0 1 0 0 0 0 1]]:
拿小明的例子[0, 1, 2]测试结果为:[[1 0 0 1 0 0 0 1 0]]
缺陷:不考虑词与词之间的顺序,且得到的特征是离散稀疏的。one-hot编码向量是垂直的,在向量空间中无法表示近似关系。
例如将世界上所有的城市名作为语料库:
吉林 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
辽宁 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
黑龙江 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
需要把词向量的维度变小,获得一个词的低维稠密的词向量















 7787
7787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









