










MyCat简介
- Mycat是Mycat社区开发的一款分布式关系型数据库(中间件)。它支持分布式SQL查询,兼容MySQL通信协议,以Java生态支持多种后端数据库,通过数据分片提高数据查询处理能力。
MyCat特性
- 支持前端作为MySQL通用代理
- 后端JDBC方式支持Oracle,DB2,SQL Server,mongodb,巨杉
- 基于心跳的自动故障切换,支持读写分离
- 支持MySQL Cluster,Galera,Percona,cluster集群
- 支持数据的多片自动路由与聚合
- 支持sum,count,max等常用的聚合函数,支持跨库分页
- 支持库内分表,支持单库内部任意join全局表,支持跨库2表join
- 基于caltlet的多表join
- 支持通过全局表,ER关系的分片策略,实现了高效的多表join查询
- 2.0支持多语句 ->如:select * from user1 ; select * from user2;
- Blob支持(Binary Large Object),用于存储二进制文件的容器
MyCat核心概念
-
逻辑库
对数据进行分片处理后,从原有的一个库,被切分为多个分片数据库,所有的分片数据库群构成了整个完整的数据库存储。MyCat在操作时,使用逻辑库来代表这个完整的数据库集群,便于对整个集群操作。 -
逻辑表
逻辑表在分布式数据库中,对应用来说,读写数据的表就是逻辑表。 -
分片表
是指哪些原有的很大数据的表,需要切分到多个数据库的表,每个分片都拥有一部分数据,所有分片构成完整的数据。例如在MyCat配置中的t_node就属于分片表,数据按照规则被分到dn1、dn2两个分片节点上。<table name="t_node" primaryKey="vid" autoIncrement="true" dataNode="dn1,dn2" rule="rule1"/> -
非分片表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片来说的,就是那些不需要进行数据切分的表。如下配置中t_node,只存在于分片节点dn1上。<table name="t_node" primaryKey="vid" autoIncrement="true" dataNode="dn1"/> -
ER表
MyCat提出了基于E-R关系的数据分片策略,子表的数据与所关联的父表数据存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据join不会跨库操作。表分组(Table Group)是解决分片数据join的一种很好思路,也是数据切分规划的一条重要规则。 -
全局表(字典表)
在业务系统中,往往存在大量的字典表,这些表基本不会动,字典表具有一下特征:- 变动不频繁;
- 数据量总体变化不大;
- 数据规模不大,很少有超过数十万条记录。
-
分片节点
也就是将一个大表切分到多个数据库上,这个库就被称为分片节点->dataNode。 -
节点主机
同一台机器上可以有多个分片数据库,这样一个或多个分片节点所在的机器就是节点主机,为了避免单节点主机并发数限制,尽量将读写压力高的节点均衡的放在不同的节点主机上->dotaHost。 -
分片规则
一个大表被拆分成多个分片表,就需要有一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,能极大的避免后续数据处理的难度。
- server.xml配置
- user标签
<user name="user"> <!--用户名--> <property name="password">user</property> <!-- 密码--> <property name="schemas">edu_order</property> <!--可以访问的库名--> <property name="readOnly">true</property> <!--是否只读--> <property name="defaultSchema">edu_order</property> <!--默认访问的库名,逻辑苦命--> </user>- firewall标签
<firewall> <!--ip白名单,支持通配符--> <whitehost> <host host="127.0.0.*" user="root"/> <host host="127.0.*" user="root"/> <host host="127.*" user="root"/> <host host="1*7.*" user="root"/> </whitehost> <!--白名单以外的,针对黑名单更低的颗粒度--> <blacklist check="true"> <property name="selectAllow">false</property> <property name="selectIntoAllow">false</property> <property name="updateAllow">false</property> <property name="insertAllow">false</property> ...... </blacklist>-
全局序列号
分库分表后数据库的自增id无法保证全局唯一。MyCat提供了全局sequence。<system> <property name="sequnceHandlerType">0</property> </system>0:表示使用本地文件方式生成; 1:表示使用数据库方式生成; 2:表示使用本地时间戳方式生成; 3:表示基于zookeeper与本地配置的分布式ID生成器方式生成; 4:表示使用zookeeper递增方式生成;- 0:本地文件方式:
此方式MyCat将sequence配置到文件中,当使用到sequence中的配置后,MyCat会更下classpath中的sequence_conf.properties文件中的sequence当前值。
#default global sequence 全局 GLOBAL.HISIDS= #历史使用的自增id,一般不配置 GLOBAL.MINID=10001 #最小id值 GLOBAL.MAXID=20000 #最大id值 GLOBAL.CURID=15000 #当前id值 #针对某一个表 COMPANY.HISIDS= #历史使用的自增id,一般不配置 COMPANY.MINID=1001 #最小id值 COMPANY.MAXID=2000 #最大id值 COMPANY.CURID=1500 #当前id值 #针对某一个表 ORDER.HISIDS= #历史使用的自增id,一般不配置 ORDER.MINID=1001 #最小id值 ORDER.MAXID=2000 #最大id值 ORDER.CURID=1500 #当前id值- 1:数据库方式生成
在数据库中创建一张表,存放sequence名称(name),sequence当前值(current_value),递增量(increment)等信息。
create table mycat_sequence ( name varchar(64) not null, current_value bigint(20) not null, increment int not null default 1, primary key (name) ) engine=InnoDB;- 2:基于时间戳方式生成
ID为64位二进制,42(毫秒)+5(机器ID)+5(业务编码)+12(重复累加)
再换成十进制为18位的long类型,每毫秒可以并发12位二进制的累加。
在MyCat下配置sequence_time_conf.properties文件
注意:每个MyCat配置的WORKID和DATAACENTERID只能组合唯一标识,总共支持32*32=1024种组合
WORKID=1 #0~31 范围内任意数字 DATAACENTERID=5 #0~31范围内任意数字- 3:基于zookeeper与本地配置的分布式ID生成器方式生成
zk的连接信息统一在myid.properties的zkURL属性中配置。基于zk与本地配置的分布式id生成器,InstanceID可以通过zk自动获取,也可以通过配置文件配置。在sequence_distributed_conf.properties,只要配置INSTANCEID=zk就表示从zk上获取InstanceID。
ID最大为63bit(二进制),可以承受单机房单机器单线程1000*(2^6)=640000的并发。结构如下- current time mills(微秒时间戳38位,可以使用17年)
- clusterId(机房或者zkId,通过配置文件配置,5位)
- instanceId(实例Id,可以通过zk或者配置文件获取,5位)
- threadId(线程Id,9位)
- increment(自增,6位)
- 4:zk递增方式生成
zk的连接信息统一在myid.properties的zkURL属性中配置。需要配置sequence_conf.properties文件- TABLE.MINID 某线程当前区间内最小值
- TABLE.MAXID 某线程当前区间内最大值
- TABLE.CURID 某线程当前区间内的当前值
- 0:本地文件方式:
- schema.xml配置
schema.xml是MyCat中重要的配置文件之一,管理者MyCat的逻辑库、表、分片节点等信息。-
schema标签
schema标签用于定义MyCat实例中的逻辑库,MyCat可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用schema标签来划分这些不同的逻辑库。<!--逻辑库--> <schema name="edu_order" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1"> </schema>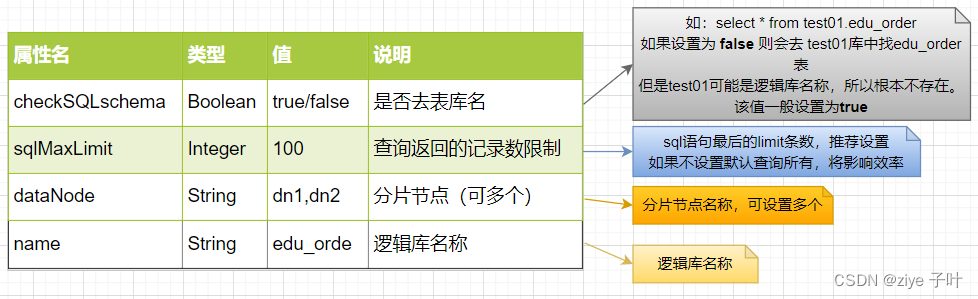
-
- table标签
table标签定义了MyCat中的逻辑表,所有需要拆分的表都需要在这个标签中定义。<table name="b_order" dataNode="dn1,dn2" rule="b_order_rule" primaryKey="id" autoIncrement="true"/>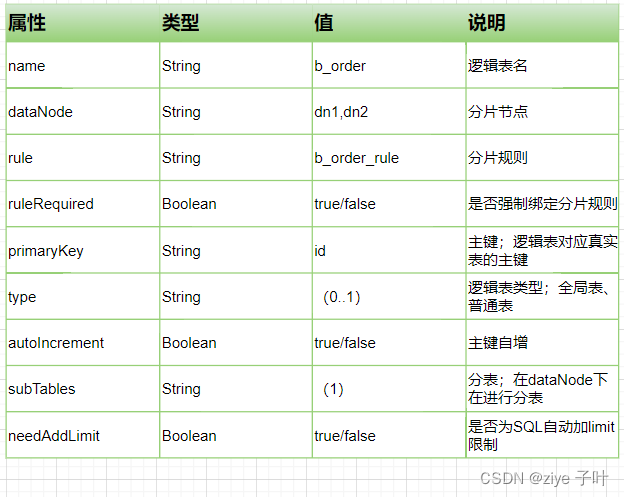
- dataNode标签
dataNode标签定义了MyCat中的分片节点,也就是数据分片。<!--数据节点--> <dataNode name="dn1" dataHost="edu_order_1" database="edu_order_1"/>- name:数据节点名称,需唯一,将要在table标签上应用这个名字,来建立表与分片对应的关系。
- dataHost:指定该分片属于哪个主机,属性值引用的是dataHost标签上的name属性。
- database:指定该分片节点属于该主机上的哪个库。
- dataHost标签
dataHost标签在MyCat逻辑库中属于最底层的标签,直接定义了具体的数据库实例、读写分离配置和心跳语句<dataHost name="edu_order_1" maxCon="100" mixCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> </dataHost>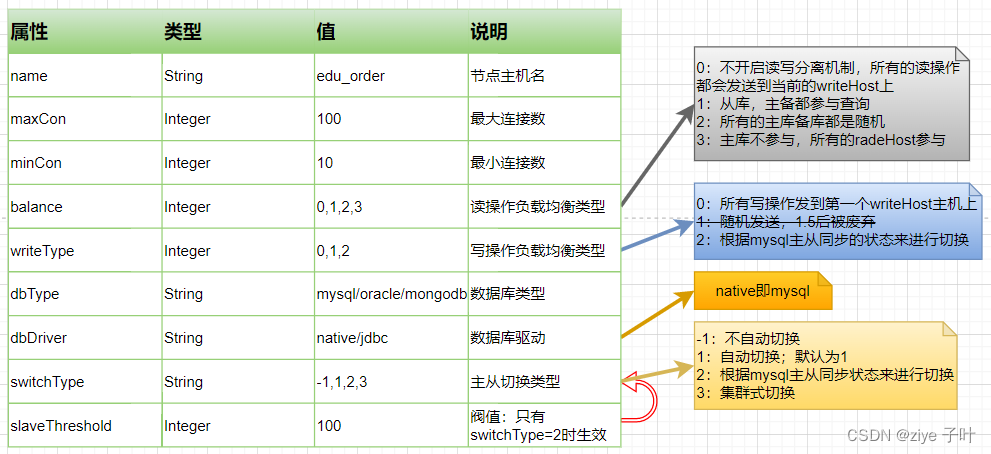
- heartbeat标签
heartbeat标签内指明用于和后端进行心跳检测的语句。如果返回则正常<dataHost> <heartbeat>select user()</heartbeat> </dataHost> - writeHost和readHost标签
<dataHost name="edu_order_1" maxCon="100" mixCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="M1" url="192.168.23.155:3306" user="root" password="ziye123"> </writeHost> </dataHost>
- rule.xml配置
rule.xml用于定义MyCat的分片规则。- tableRule标签
<tableRule name="c_order_rule"> <rule> <columns>user_id</columns> <algorithm>partitionByOrderFunc</algorithm> </rule> </tableRule>- name:指定唯一的名字,用于识别不同的表规则。 -> 对应table标签中的 rule 的值。
- columns:指定要拆分的列名字 -> 如:指定“user_id”为分片键
- algorithm:连接表规则和具体路由算法 -> 对应下面 function 标签中 name 的值
- function标签
<function name="partitonByOrderFunc" class="io.mycat.route.function.PartitionByMod"> <property name="count">2</property> </function>- name:指定算法的名字。
- class:指定路由算法局的类路径。
- property:为具体算法需要用的一些属性。
- tableRule标签
其他章节 -> 跳转
end...

















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











