







导言
从现场出差到远程支持,从面对面交流到云端会议……疫情改变了我们的生活和工作模式,加快了数字化进程,也为无线网络的运维带来了新的难题,如何实现免人工干预的网络自愈,为网络提升“抵抗力”?
后疫情时代的网络运维挑战
疫情催化下,数字化进程驶入快车道。“无接触”、“云化”、“远程”先是成为热点,而后被人们习以为常,在线业务呈现爆发式增长,各行各业进入“All On Line”模式。作为承载业务的底盘,无线网的压力不断增加,随之而来的是一系列运维挑战:
- 看见难:无线看不见摸不着,如何清晰掌握?
- 分析难:海量数据,眼花缭乱,如何定位分析?
- 优化难:技术复杂,门槛高,如何着手优化?
依赖人工的运维,无论是效率还是效果,都已不能满足当下的业务要求。
数字化转型需要怎样的网络运维
如果将依赖人力的运维比作 “农耕时代”,网络运维方式也像人类社会一样在不断进化,目前行业在“智能运维”方向快速推进。
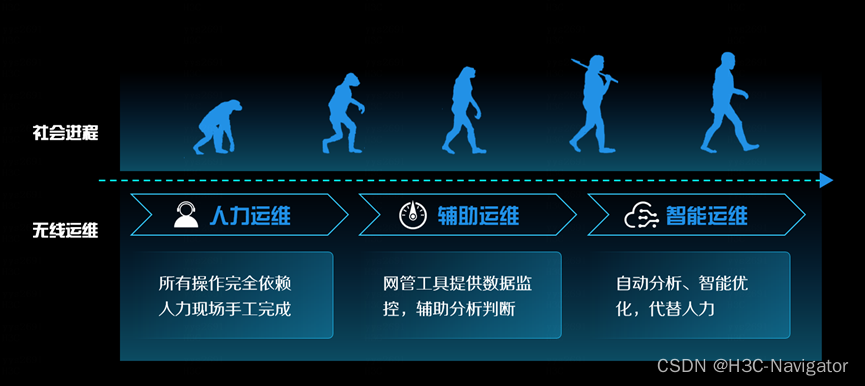
图 1无线运维演进方向
对于网络运维系统来说,想要攀登“智能运维”这座巅峰,需要具备三大能力:
- 看见的能力:运维金字塔的底层,代表最基础的监控类功能,如设备和终端的数据采集、数据呈现。
- 思考的能力:利用采集到的数据做进一步的分析,得出结论或作出判断,如辅助故障定位、根因分析、优化指导,目前行业普遍处于该水平。
- 执行的能力:在看见和思考的基础之上,根据现象作出决策并自动执行,如基于根因分析下发优化配置,实现问题自动闭环。
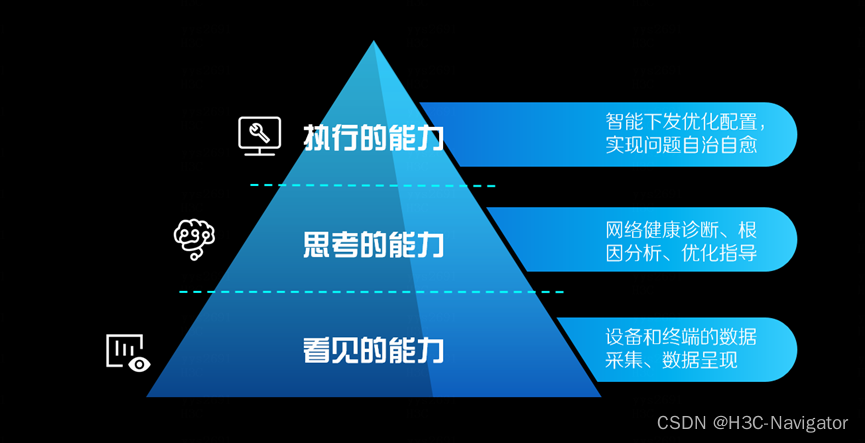
图 2智能运维能力金字塔
1.分毫毕现
通常,一个完整的无线网络需要外网、网关、无线控制器(AC)、无线接入点(AP)以及无线终端,流量传输不仅要经过有线链路,还有无线链路,任何一个环节出现问题都会影响业务的正常进行。
目前,行业内普遍可做到有线链路的可视化,比如远程查看端口在线情况、设备流量、AP的CPU信息等。但有线链路的可视化并不足够,这就导致了运维死角。比如遇到信号干扰、认证失败、漫游粘滞问题,仅仅检查设备是不能支撑定位的,以往遇到上述终端体验类问题都需要亲临现场分析问题,而疫情影响下,现场定位的难度增大,对远程运维提出了更高的要求——要能看见AP和终端之间的无线链路,收集全量数据并且最好可以完整“回放”终端的连网历史,比如:
基本信息——哪个终端?
连接信息——连接的哪个无线服务?涉及哪些设备?
指标情况——各指标的是否正常?如信号强度、时延、选速、丢包……
事件日志——在什么时间?发生了什么事件?是否出现异常?
事件过程——终端某事件的详细交互报文及耗时,如认证、DHCP、ARP、DNS事件……
参考对比——同一射频下其他邻居终端体验如何?
2.健康感知
分毫毕现对于定位问题十分重要,但面对海量的数据,仅将目光停留在网元层级往往容易管中窥豹,如何看到真实的网络质量?在数据采集的基础上,运维系统需要站在更高的层次“俯视”网络。
无线网中存在大量的实时和历史数据,空口看不见摸不着且业务也在时刻变化,要理清这些数据进而找到有效信息,是一个巨大的工作量。智能的运维系统需将这些看见的、看不见的、当下的、历史的数据汇聚整理,而后根据时间、数量、对象等维度,通过趋势图、比例图、GIS地图等图表方式呈现出来,帮助运维人员清晰有效地掌握趋势、规律和重点。
比如,通过DPI(深度报文检测)技术,分析应用层数据,在业务层面对应用做可视化的分析,综合丢包、时延、抖动等利用算法模型进行健康质量分析和量化打分,进而对视频会议、语音等重要业务做网络质量保障和精细化的流量调度。
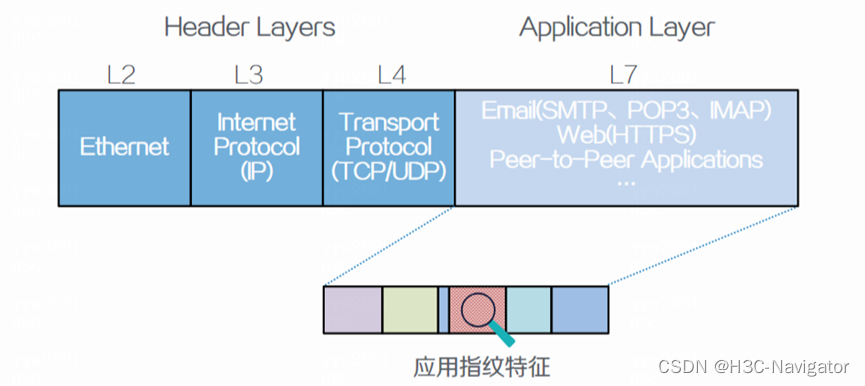
图 3深度报文检测技术
3.问题分析
海量数据赋予了运维系统“看见”的能力,之后,智能运维迈向第二个台阶——“思考”的能力,它的出现将打破传统的运维流程:
以前的“抢险式运维”是十分被动的,一个问题的发现始于报障、投诉或告警,往往这时已经造成了不良的影响。智能化的运维,要求运维系统会“思考”,可以在问题被用户感知到之前,挖掘出问题隐患,给出优化方案,化被动为主动。
运维系统需要多维度的“思考”,比如:
哪些数据是有价值的?
数据之间的关联?
数据与现象之间的关联?
哪些现象是异常/正常的?
发现异常现象后,需要将经验总结为知识图谱将问题分类并给出原因和对应的解决方案。
下面拿漫游粘滞这个问题来举例。首先来了解一下什么是漫游粘滞?
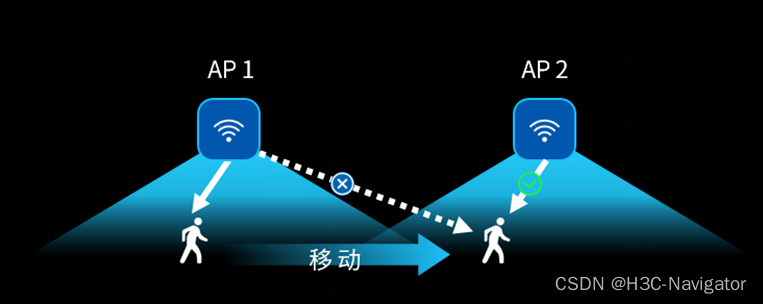
图 4终端漫游过程示例
如图4所示,当终端画面从左侧移动到右侧后,距离AP2更近,在其他条件一致的情况下,终端漫游到AP2的信号强度最高、网速更快、信号更稳定。但问题终端偏偏“赖”在远端的AP1上,导致信号弱体验差,这种情况我们称之为“漫游粘滞”。而导致漫游粘滞的发生,可能是由于网络侧的射频功率规划不合理,也可能出于用户侧的终端自身漫游机制和算法不合理等原因。
那么运维系统如何发现这个问题?
1.采集海量数据,如前文介绍,云端可采集有线和无线链路的海量数据;
2.建模分析,基于大数据,分析终端的信号强度、关联AP的数量、弱信号持续的时间、终端流量以及Probe报文等数据;
3.问题判定,比如发现某终端自身信号强度低(如低于60db)、体验差(如丢包率高)且持续一定时间,但所关联射频运行正常,同一射频下其他终端正常,可判定其出现漫游粘滞问题。
4.自治自愈
完成了数据采集和问题分析,下一步就是在没有人工干预的条件下自动解决问题,实现流程闭环。
无线网十分灵活,问题随时发生稍纵即逝,接入终端、环境条件、业务负载时刻都在变换,想要在“开药治病”时不引起“副作用”,不仅要求运维系统不仅要有敏捷强壮的“肌肉”去下发配置,还需要有见机行事的“大脑”,针对每射频、每终端、每问题,分情况精准定制优化策略,以适配复杂的无线环境。
继续拿漫游粘滞来举例。
显而易见,要解决漫游粘滞需要让终端切换到最佳的AP2上。第一步“开药”,运维系统需根据终端条件和无线环境计算出最佳的漫游射频;第二步“治病”,系统下发配置到AP,通过各种手段将终端切换到AP2的射频。
但不得不面对的难题是,漫游可能会引起短暂的网络中断,影响用户体验,贸然强硬执行,用户可能会认为网络不稳定,这就是引起了副作用,那如何解决这个问题呢?
系统根据终端流量判断用户的状态,比如当流量下降到10Kb/s时可认为用户处于“业务闲时”,对网络的依赖不高,此时切换用户无感知。在“业务闲时”的前提下,系统将对AP1下发弱信号拒接、不回应probe等配置,让终端“认为”AP1无法提供正常的网络服务,触发终端的漫游机制,强制终端切换到AP2的射频。
如果终端还有流量,系统会判断用户处于“业务忙时”,此时不会执行切换射频、拒接、重新关联等硬性策略,而是会采取更加温和的诱导策略,比如向终端发送通知报文,通知终端漫游。或者通过调整信号功率诱导终端接入信号强的AP。如果经过上述流程后问题仍存在,系统将继续观察记录终端关联行为,在下个周期寻找适合的漫游机会。
逐级柔性优化:
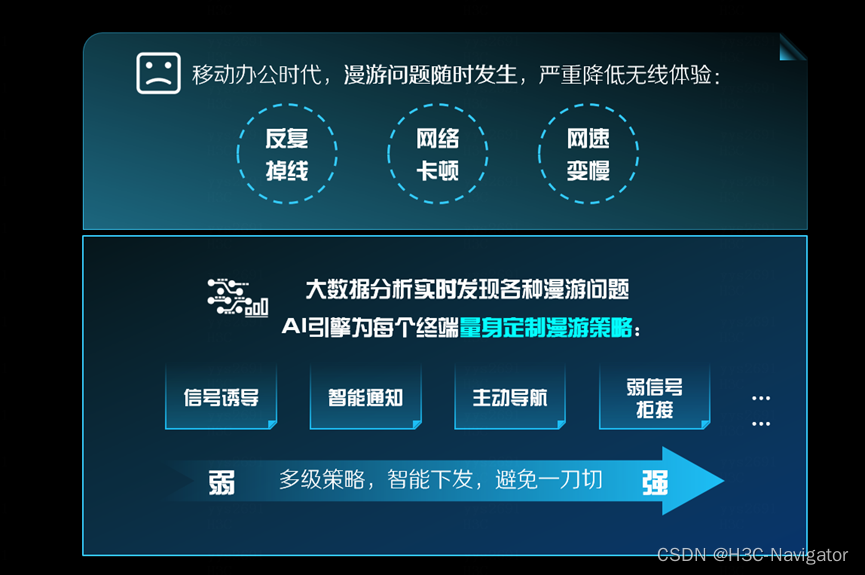
图 5逐级柔性优化漫游策略
总结
在“无线优先”的趋势下,人们对无线网络品质的要求会不断提高,势必会带来网络运维难度的增大。对于运维人员来说,智能化的运维是一位得力助手,将工程师从繁重复杂的工作量中解放出来,缩短90%以上的无线运维时间;对于网络使用者来说,智能化的运维是体验保镖,提供7×24H的全天候服务,及时响应需求,打造优质的无线体验。















 1430
1430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









