






fcm聚类算法易陷入局部最优中,gfcm算法有效改进了这个问题,具体算法流程如下图所示。
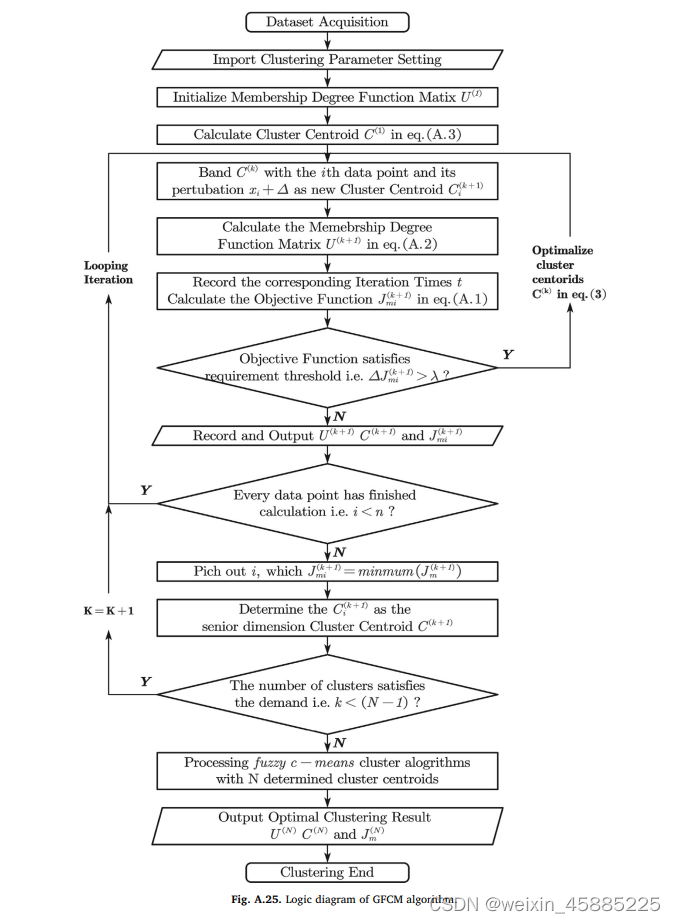

该算法首先计算只有一类的聚类中心,然后依次增加中心点个数,并为每次的中心点计算目标函数值,最后去最小目标函数值的中心点作为整个数据集的中心点。
对其做了以下改进
1、对其算法进行了改进,在中心点选择上更加准确,误差更小,并且在多中心点时不会报错;
2、对其进行了加速,在数据为150,中心点为150的情况下,计算速度从几十分钟下降到1分钟左右,在多个中心点和数据时效果更加明显;
3、添加了自动画图代码,倘若要变换中心点个数,无需改动作图部分,可以自动把数据点的分类情况描绘在图中,比较直观。
在使用过程中仅需改动C的个数(中心点个数),以及数据集(data)即可
注:此程序仅限matlab2023使用,若为2023版本以下(本人亲测2020和2021版本是这样的) ,则可能需要自己定义stepfcm和dispfcm函数,其中stepfcm函数与网上版本不同,增加了一小段,防止中心点过多运行后期报错,dispfcm为网上版本,附在页面下方。
clc
clear
tic
C=80;
filename = 'iris(1).xlsx';
data = xlsread(filename,'Sheet1','B2:C101');
center1=sum(data)./size(data,1);
center_per = cell(size(data,1),1);
center_per{1}=center1;
objective = zeros(size(data,1),1);
expo=2;
max_iter=1000;
min_impro=1e-5;
temp=[];
center2=[]; %save the center of cluster
U_t=[]; %save the U_relationship of the data and the center
display=0;
for cluster_n=2:C %iteration to search the C cluster center
cluster_n
temp=[];
U_t=zeros(C*cluster_n, size(data,1));
center2=zeros(C*cluster_n, size(data,2));
for j=1:size(data,1)
center=[center1;data(j,:)];
dist = distfcm(center, data); % fill the distance matrix
tmp = dist.^(-2/(expo-1)); % calculate new U, suppose expo != 1
U= tmp./(ones(cluster_n, 1)*sum(tmp));
U(isnan(U)) = 1;
for i=1:max_iter
[U, center, obj_fcn(i)] = stepfcm(data, U, cluster_n, expo);
if i > 1
if abs(obj_fcn(i) - obj_fcn(i-1)) < min_impro
break;
end
elseif abs(obj_fcn(i)) < 0.001
break
end
iter_n = i; % Actual number of iterations
end
center2(j*cluster_n-cluster_n+1:j*cluster_n, 1:size(data,2)) = center;
U_t(j*cluster_n-cluster_n+1:j*cluster_n, 1:size(data,1))=U;
temp=[temp;obj_fcn(i)];
obj_fcn=[];
end
N=min(temp);
[count,c]=find(N==temp,1);
center1=zeros(cluster_n,size(data,2));
for k=1:cluster_n
center1(k, :)=center2((cluster_n*count-k+1),:);
end
center_per{cluster_n}=center1;
objective(cluster_n)=N;
end
toc
Max_fcn=min(temp);
fprintf('obj_gfcm = %f\n',Max_fcn);
[count1,r]=find(temp==Max_fcn,1);
plot(data(:,1), data(:,2),'o');
hold on;
maxU = max(U_t((cluster_n*count1-cluster_n+1):(cluster_n*count1),:));
plot(center2((C*count1-C+1):(C*count1),1),center2((C*count1-C+1):(C*count1),2),'k*'); %plot the center of cluster
index=cell(cluster_n,1);
color = ['r','g','b','c','m','y','k'];
for i = 1:cluster_n
i
index(i)={find(U_t((cluster_n*count1-i+1),:) == maxU)}
line(data(index{i,1}(:),1),data(index{i,1}(:),2),'marker','*','color',color(mod(i,size(color,2))+1)); %line the data in the same cluster
end
hold off;
function [U_new, center, obj_fcn] = stepfcm(data, U, cluster_n, expo)
mf = U.^expo; % MF matrix after exponential modification
ss = sum(mf,2);
for i = 1:size(ss,1)
if ss(i) == 0
ss(i) = 1;
end
end
center = mf*data./(ss*ones(1,size(data,2))); %new center
dist = distfcm(center, data); % fill the distance matrix
obj_fcn = sum(sum((dist.^2).*mf)); % objective function
tmp = dist.^(-2/(expo-1)); % calculate new U, suppose expo != 1
U_new = tmp./(ones(cluster_n, 1)*sum(tmp));
endfunction out = distfcm(center, data)
out = zeros(size(center, 1), size(data, 1));
for k = 1:size(center, 1)
out(k, :) = sqrt(sum(((data-ones(size(data,1),1)*center(k,:)).^2)',1));
end
end


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









