









此处以centos01、02、03为例
A-配置各节点无密钥登录
1、查看ssh版本号,如若没有ssh,将其安装
ssh -V
2、在centos01中配置ssh免秘钥登录,生成秘钥文件

3、在centos01中将秘钥信息加入到授权文件中

4、在centos02、03中执行1、2步骤,然后将秘钥文件远程拷贝到centos01中(记得要重命名)
centos02(作参考)


centos03(作参考)


在centos01中查看一下,确定拷贝完成

5、验证三台机器的免秘钥登录配置成功
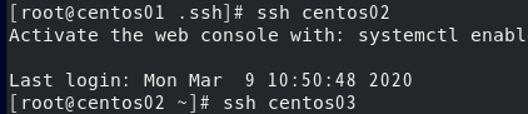

成功
B-搭建
1、上传Hadoop压缩包,解压,(用xftp)
上传Hadoop至/opt/softwares

解压至/opt/modules

查看一下,有了

C-配置Hadoop环境变量
1、Hadoop所有的配置文件都在/etc/hadoop中,在hadoop-env.sh文件,mapred-env.sh文件,yarn-env.sh文件中加入环境变量
export JAVA_HOME=/opt/modules/jdk1.8.0_144
D-配置HDFS
1、修改配置文件core-site.xml


2、修改配置文件hdfs-site.xml
replication:文件在HDFS中的副本数
name:HDFS名称节点在本地文件系统的存放位置
data:HDFS数据节点在本地文件系统的存放位置


3、修改slaves文件,添加三个节点

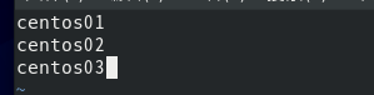
E-配置Yarn
1、复制mapred-site.xml.template文件为mapred-site.xml

2、修改mapred-site.xml文件

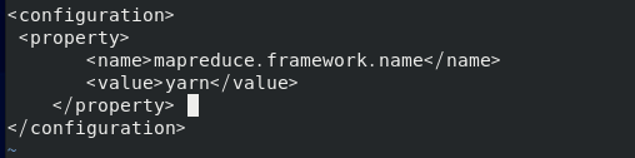
3、修改yarn-site.xml文件,添加以下内容

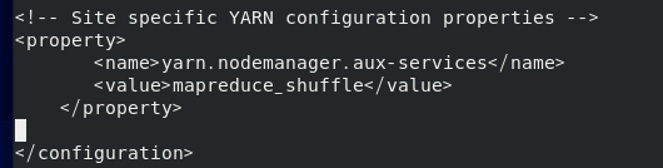
4、拷贝Hadoop安装文件到其他主机



F-配置Hadoop环境变量(为了能在任何目录下执行Hadoop命令)



G-启动Hadoop
1、格式化NameNode,初始HDFS系统目录和文件


2、启动


H-查看各节点进程
jps
I-测试HDFS
1、在centos01节点的HDFS根目录创建文件夹,名为input,并将/opt/data目录下的一个名为自己学号.txt文件(文件中输入两行话:第一行:Hello, Hadoop!,第二行:My name is pinyin)上传到新建的input文件夹中


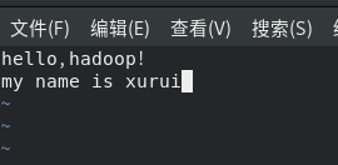
2、在网页中查看HDFS的NameNode信息

G-测试MapReduce
在网页中查看并打开之前上传的txt文件,然后运行Hadoop自带的MapReduce单词的计数程序,统计数量



测试结束,没有问题,Hadoop集群搭建成功















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









