







在 SequoiaDB 集群环境中,可以通过将一个集合中的数据划分成若干不相交的子集,再将这些子集映射到另外的集合上,这种数据切分的方法称为表分区。这些不相交的子集称为分区,被数据划分的集合称为主集合,分区映射的集合称为子集合。
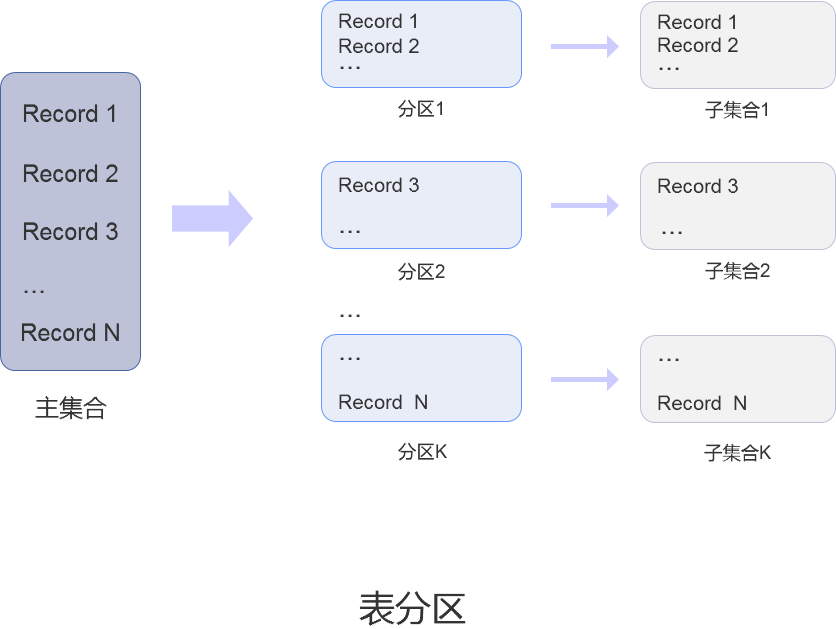
- 分区内的所有数据记录都是完整的记录
- 一个分区只能映射到一个子集合中
- 通过集合挂载操作,可以将分区从一个子集合中映射到另外一个子集合中
- 当需要访问某个特定范围内的记录时,只会访问所属分区的子集合,避免访问所有分区数据,从而减少了数据访问量
分区方式
分区方式是指将集合中的数据划分为不同分区的算法。分区方式包括范围分区(Range)和散列分区(Hash)。
范围分区方式
范围分区方式是指根据集合数据的取值范围,对集合中的数据进行切分的分区方式。
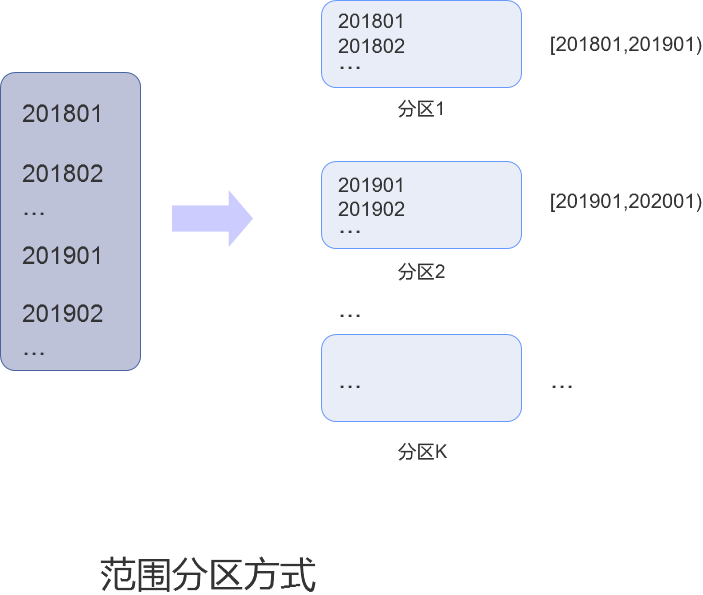
通过范围分区方式,可以直观的了解到集合数据的分区情况。如上图所示,在201801到201901之间的数据落在分区1中,在201901到202001之间的数据落在分区2中。
范围分区方式较为典型的场景是访问一定范围内数据的场景。例如,当访问某一时间的段的记录时,数据库只会访问对应时间段的分区数据,而不会访问其他时间段的分区数据,从而大大减少了系统访问的数据量,并提高系统性能。
散列分区方式(Hash)
散列分区方式是指先对集合数据做一次散列运算,再按照散列运算结果的 hash 值对数据进行切分的分区方式。
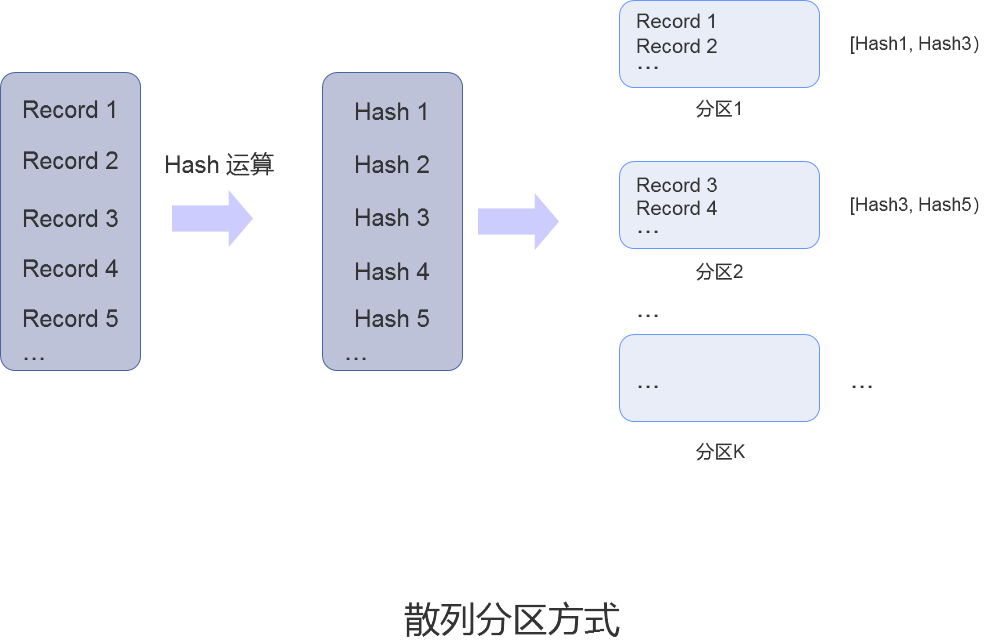
在字段取值相对离散的情况下(如集合中的唯一键),通过散列分区方式,每个 hash 值对应的数据量基本相同。而在范围分区方式中,相同范围内的数据量不一定是相同的。
散列分区方式较为典型的场景是访问集合中所有数据的场景。例如,当遍历集合数据时,数据库就会访问所有分区的数据,可以发挥所有分区上各个节点的并行计算的能力。因为每个分区中的数据量基本相同,所以分区所在节点的 I/O 负载情况基本相同,不容易出现数据热点问题。
分区键
在不同的分区方式中,作为数据划分依据的字段称为分区键。在范围分区方式中,分区键是用于划分数据范围的字段;在散列分区中,分区键是用于计算 hash 值的字段。每个分区键可以包含一个或多个字段。
分区类型与分区方式的关系
不同的分区类型可以选择使用不同的分区方式去划分数据。数据库分区既可以使用范围分区方式,也可以使用散列分区方式,而表分区只能使用范围分区方式。
相关阅读














 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









