







在 SequoiaDB 巨杉数据库中,通过将集合数据拆分成若干小的数据集进行管理,从而达到并行计算和减小数据访问量的目的。根据管理方式的不同,可以分为以下两种分区类型:
- 数据库分区:用于描述数据在集合与复制组之间的关系
- 表分区:用于描述数据在集合与集合之间的关系
数据库分区
在 SequoiaDB 集群环境中,可以通过将一个集合中的数据划分成若干不相交的子集,再将这些子集切分到复制组中,以达到并行计算的目的,这种数据切分的方法称为数据库分区。而这些不相交的子集称为分区。
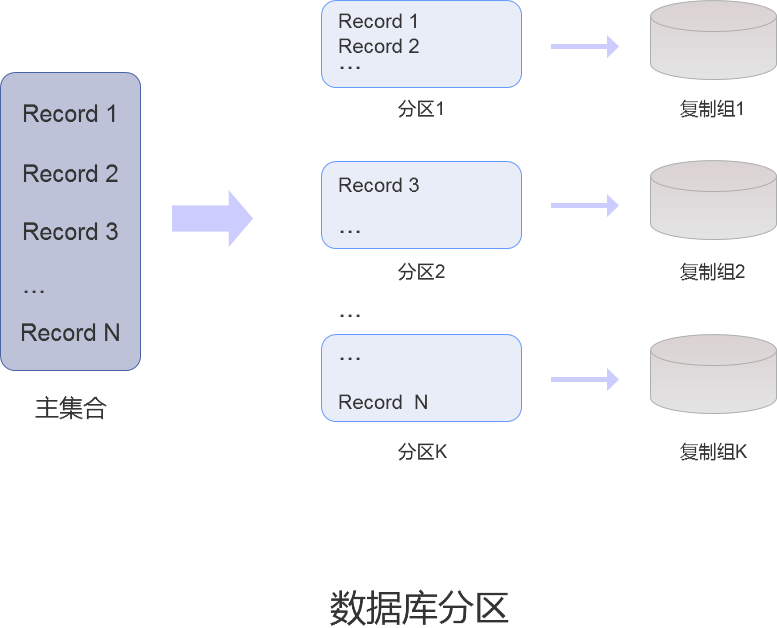
- 分区内的所有数据记录都是完整的记录
- 一个分区只能存在于集群中的某一个复制组中,但一个复制组却可以承载多个分区
- 通过切分操作,可以将分区从一个复制组中移动到另一个复制组中
- 当同时访问多个分区的数据时,可以同时在分区所在的不同复制组中进行并行计算,从而提高处理速度和性能
相关阅读















 4678
4678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









