






当我企图使用pyspark的随机森林为120万条数据训练模型的时候,会出现java heap space 的报错,也就是java 堆空间不足,但是我用的是python的pyspark,我尝试过很多方法去修改java堆空间,把修改方式放在这里最后是解决办法
屠龙刀(最终解决办法):
spark = SparkSession.builder \
.master('local[*]') \
.config("spark.driver.memory", "15g") \
.appName('my-cool-app') \
.getOrCreate()
sc = spark.sparkContext
sqlContext = SQLContext(sc)
原来最终起作用的是spark.driver.memory参数,调高就行了,这是我的spark的配置,仅作参考。
我是在这篇文章中找到的答案,链接放到这里了:apache spark – PySpark: java.lang.OutofMemoryError: Java heap space – Stack Overflow
以下是我尝试过的方法但是没有解决我的问题,还是分享在这里
第一种方法:
修改jdk下面的文件jdk\jre\lib\amd64\jvm.cfg,增加下面的内容,但是一点用没有,反而引发了警告。
-Xms1024m
-Xmx2048m
-XX:PermSize=1024M
-XX:MaxPermSize=2048M
上面方法的警告,并且暗示问题没有解决
第二种办法
根据pycharm自带的内存设置以及vm类型设置
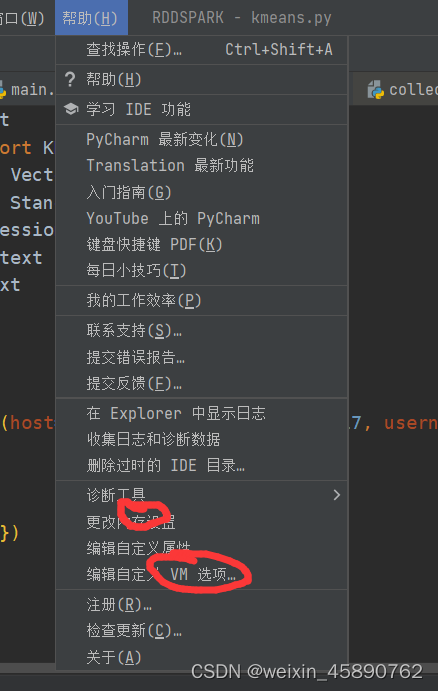
这两个选项修改内存大小
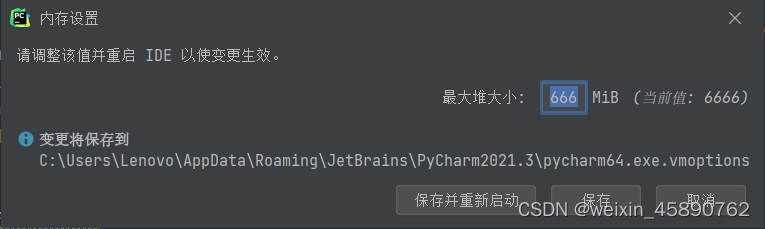
修改内存设置
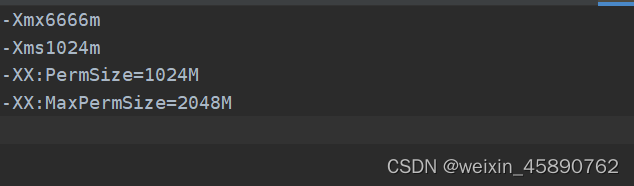
vm选项
但是还是没有啥用,最后通过stackoverflow找到了答案















 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









