







flume第七讲:hdfs sink(多用于离线)
工作机制
数据最终被发往hdfs;
可以生成text文件或者sequence 文件,而且支持压缩;
支持生成文件的周期,roll file机制:基于size,或者时间间隔,或者event数量;
目标路径,可以使用动态通配符替代,比如用%D代表当前的日期;
当然也能从event的header中,取到一些标记来作作为通配符替换,
例如
header:{type=abc}
/weblog/%D/ 就会被替换成: /weblog/abc/19-06-09/
1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /logs22/a.log
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
#设置一个拦截器
a1.sources.r1.interceptors.i1.type = timestamp
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000000
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
#通过上面的拦截器设置的时间戳,我们将它转换为年,月,日,时,分作为路径和表名
a1.sinks.k1.hdfs.path = hdfs://doit01:9000/doit13/%Y-%m-%d/%H-%M
#给下沉到hdfs中的文件名加一个后缀
a1.sinks.k1.hdfs.filePrefix = doit13_
#设置文件的压缩格式
a1.sinks.k1.hdfs.fileSuffix = .log.gz
#设置文件滚动的大小
a1.sinks.k1.hdfs.rollInterval = 0
#当文件达到100M就会生成一个文件夹来装数据
a1.sinks.k1.hdfs.rollSize = 102400000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#设置写入hdfs中的文件格式
a1.sinks.k1.hdfs.writeFormat = Text
flume执行配置文件
[root@doit02 flume-1.9.0-bin]# bin/flume-ng agent -n a1 -c conf -f \
agent/hdfs-sink.conf -Dflume.root.logger=INFO,console
我们写一个连续写入数据的脚本写入这个路径/logs22/a.log
用来模仿数据的写入
i=1 ;
while true ;
do
echo "$i -----$((i++))------">>/logs22/a.log ;
sleep 0.01;
done
检验结果
这是路径
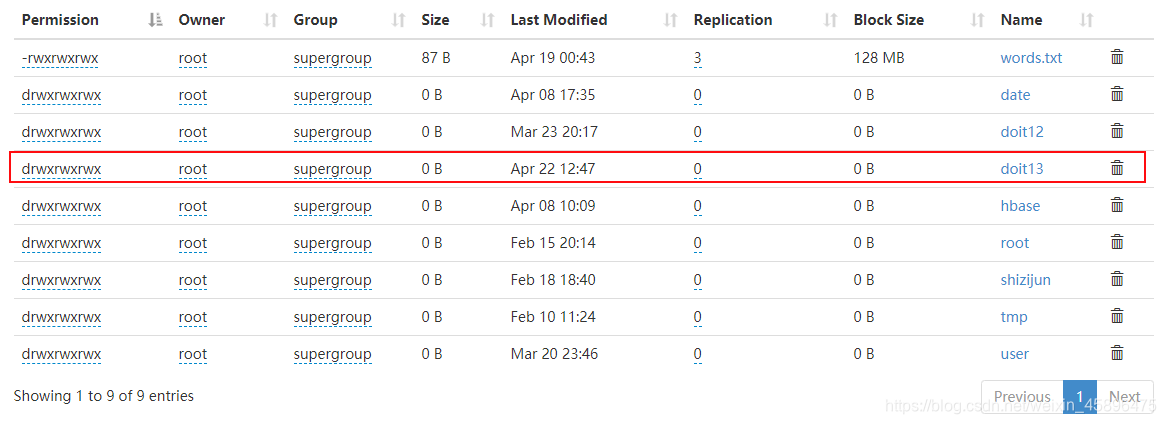
文件夹名
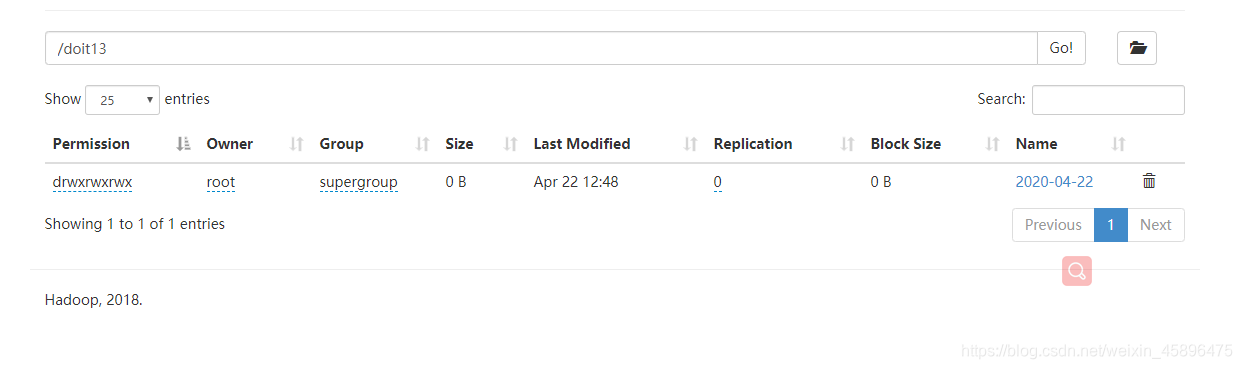
这是自动根据机器的时间创建的表名
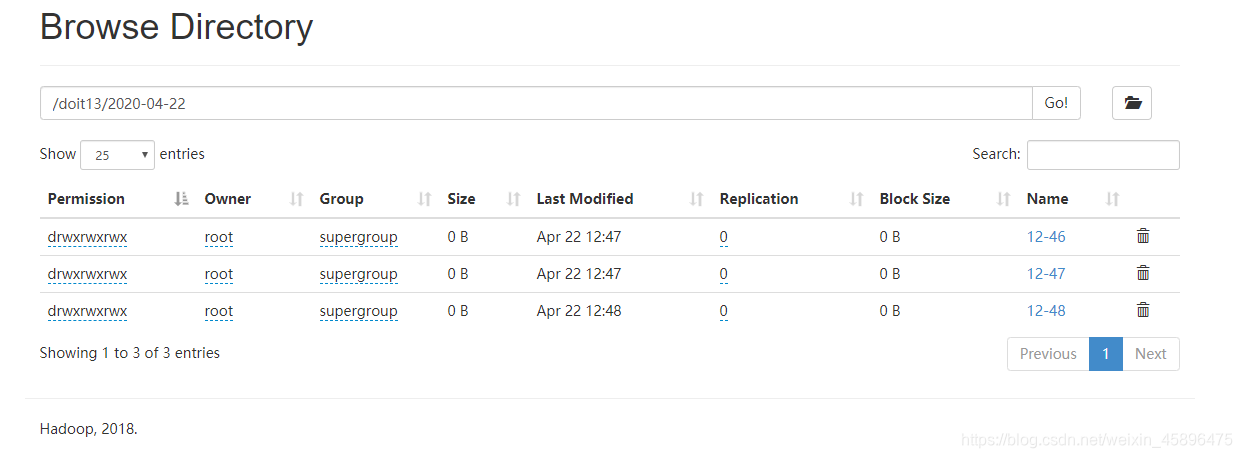














 4846
4846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









