






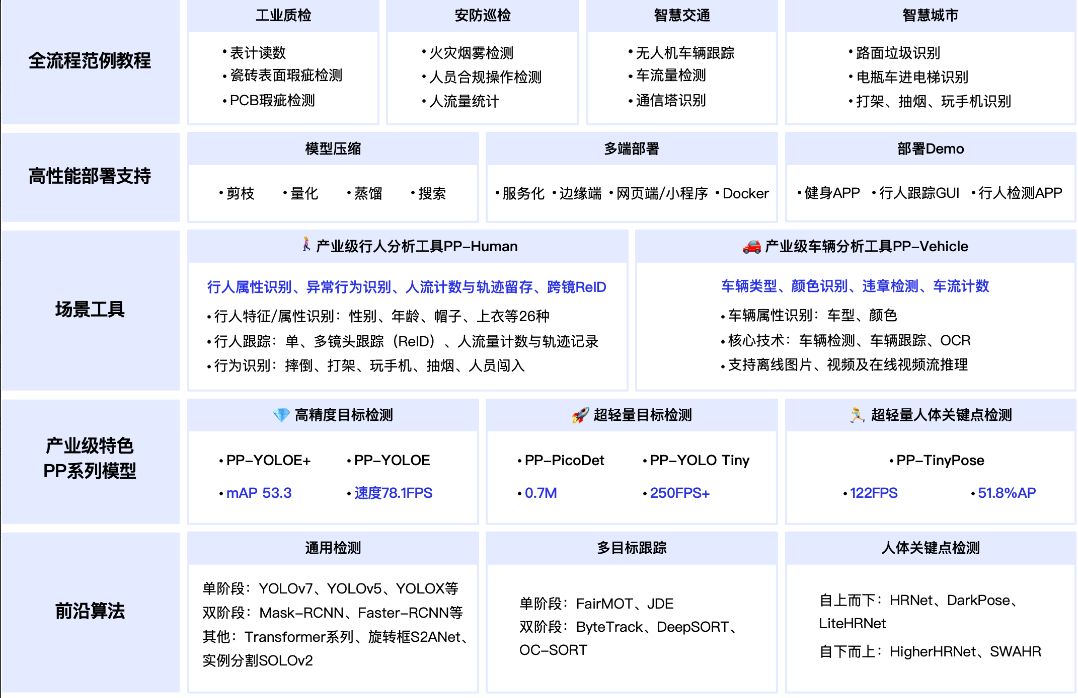
- 最新发布
- PP-YOLOE+,最高精度提升2.4% mAP,达到54.9% mAP,模型训练收敛速度提升3.75倍,端到端预测速度最高提升2.3倍;多个下游任务泛化性提升。
- PicoDet-NPU模型,支持模型全量化部署;新增PicoDet版面分析模型。超轻量目标检测算法。
- PP-TinyPose增强版,在健身、舞蹈等场景精度提升9.1% AP,支持侧身、卧躺、跳跃、高抬腿等非常规动作。超轻量关键点检测算法。
- 新增能力
- 发布行人分析工具PP-Humanv2,新增打架、打电话、抽烟、闯入四大行为识别,底层算法性能升级,覆盖行人检测、跟踪、属性三类核心算法能力,提供全流程开发及模型优化策略,支持在线视频流输入。
- 首次发布PP-Vehicle,提供车牌识别、车辆属性分析(颜色、车型)、车流量统计以及违章检测四大功能,兼容图片、在线视频流、视频输入,提供完善的二次开发文档教程。
- 应用场景
- 智能健身
智能化的对健身动作进行识别、矫正、计数
2. 打架识别
3. 来客分析
通过对来店客人的属性识别、行为预警、时长和轨迹记录等数据进行统计分析, 可以应用于 相关场所的客流通统计、用户画像、客户留存分析等功能, 进而提升 相关场所的经营和服务水平
4. 车辆结构化识别
车牌识别、车辆属性分析、违章检测、车流量计数
- 论文介绍
4.1 PP-YOLOE
论文地址:PP-YOLOE+
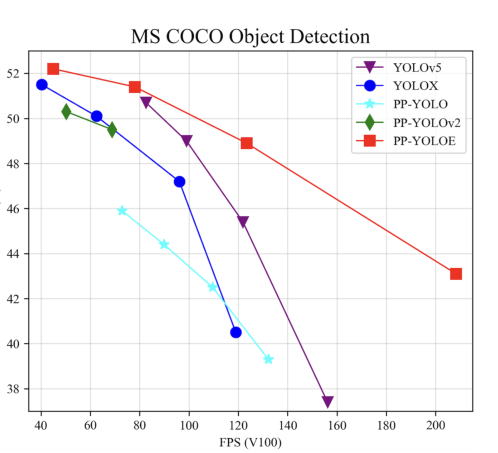
主要创新点:
- Anchor free无锚盒机制
- 可扩展的backbone和neck,由CSPRepResStage(CSPNet+RMNet)构成
- 使用Varifocal Loss(VFL)和Distribution focal loss(DFL)的头部机制ET-head
- 动态标签分配算法Task Alignment Learning(TAL)
| YOLOV5 | YOLOX | PPYOLOE | YOLOV6 | |
| 数据增广 | mosaic、mixup等 | mosaic、mixup等 | 只有最基本的 | 同yolov5 |
| backbone | cspdarknet | cspdarknet | CSPRepResNet | EfficientRep |
| neck | PAN | PAN | PAN | Rep-PAN |
| Head | 耦合 | 解耦 | ET-Head | 解耦+加速 |
| label assignment | max-iou-assign | simOTA | TAL | simOTA |
| Anchor-free | anchor-based | Anchor-free | Anchor-free | Anchor-free |
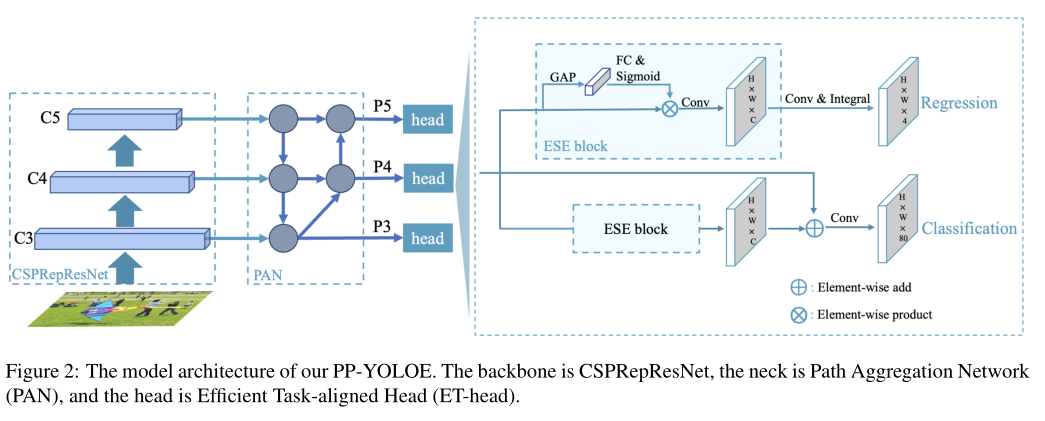
网络结构:
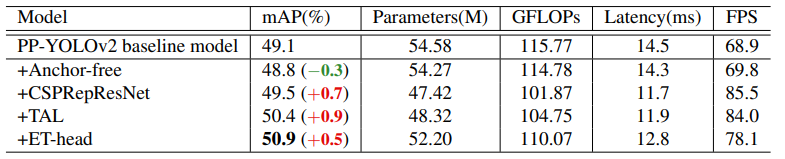
消融实验各改进部分效果
- Anchor free无锚盒机制
Anchor引入的缺点:
(1) 检测器的性能一般和anchor(框)的比例和尺寸有关。
(2) 一般anchor的尺寸和大小固定,很难处理形状变化大的目标,当进行迁移学习时,可能需要重新设计anchor。
(3) anchor的引入使得训练任务非常繁琐。
(4) 为了得到较高的召回率,通常需要在图片中生成非常密集的anchor,而大部分anchor为负样本,导致正负样本极度不均匀,负样本对检测器没有任何作用。
Anchor-free的引入:
针对预测点,直接预测这个点相对于目标的左侧、上侧、右侧、下侧的距离(l、t、r、b)

xmin = Cx-l*s ymin = Cy-t*s
xmax = Cx+r*s ymax = Cy+b*s
其中,l、t、r、b为回归任务预测得到的,且在特征图尺度上的,需乘s映射到原图。s为预测的特征特相对于原图的步距,(xmin,ymin),(xmax,ymin),(xmax,ymax),(xmin,ymax)分别为顶点坐标。
- 可扩展的backbone和neck,由CSPRepResStage(CSPNet+RMNet)构成
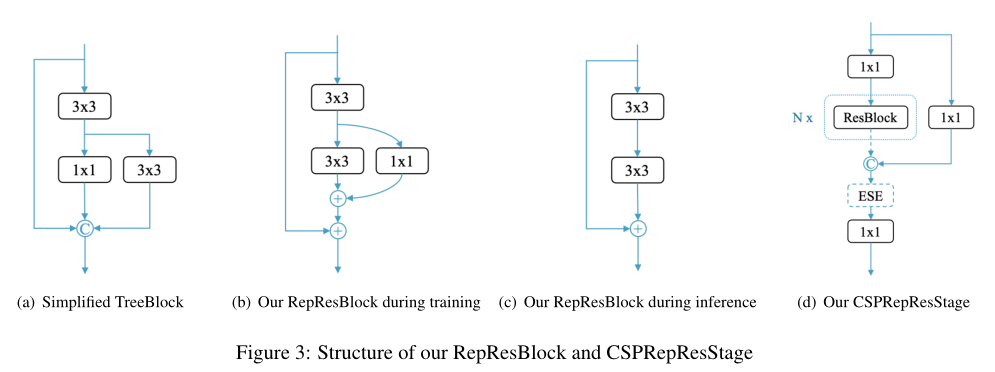
在backbone部分集成了残差结构和密集连接结构,且推理过程较训练过程少了1x1的残差连接,最后以ESE(注意力模块)连接。
PAN(Path Aggregation Network)结构其实就是在FPN(从顶到底信息融合)的基础上加上了从底到顶的信息融合。
- 使用Varifocal Loss(VFL)和Distribution focal loss(DFL)的头部机制ET-head
结构:
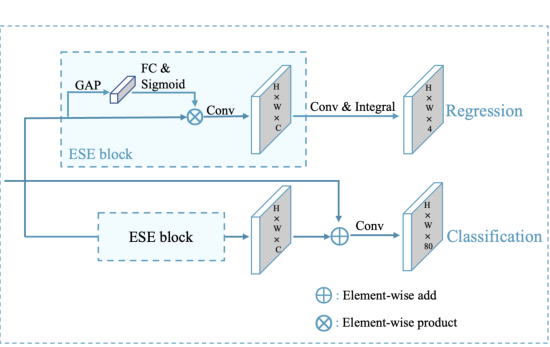
- 在精度无损的条件下,将通道注意力模块简化成了更加高效的 ESE block,ESE block相比于SE block少用一个全连接层,避免通道信息的丢失。
- 将分类任务对齐模块简化成了 shortcut,进一步提升了速度。
损失函数:
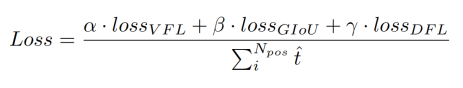
- 采用 VFL(varifocal loss)作为分类损失(交叉熵),它对于正负样本的权重分配不同,这种实现使得具有高IoU的阳性样本对损失的贡献相对较大。这也使得模型在训练时更关注高质量的样本,而不是那些低质量的样本。
- 在之前,目标检测任务中做回归一般是直接预测某个回归值,或者预测相较于anchor的比例,为了解决边界框表示不灵活的问题,DFL提出利用一般分布来预测bounding box,将回归看作是一个分布预测任务。
- GIOU损失来表示检测框的质量评估。
- 两者都使用IoU感知分类得分(IACS)作为预测目标。这可以有效地学习分类分数和定位质量估计的联合表示,这使得训练和推断之间具有高度一致性。
详细参考:
- 动态标签分配算法Task Alignment Learning(TAL)
TAL是由论文TOOD提出,目的是把两个任务的最优anchor拉近,通过设计一个样本分配策略和一个任务对齐的损失来执行。样本分配通过计算每个anchors的任务对齐程度来收集训练样本(即正样本或负样本),而任务对齐损失可以逐步将分类和定位最佳的anchor统一起来,以在训练期间预测分类和定位。因此,在推理时,可以保留具有最高分类分数并共同具有最精确定位的边界框。
anchor对齐度量
通过分类得分和预测框和gt的IoU的高阶组合来表示这个度量:

其中 s 和 u 分别表示分类 Score 和 IoU 值。 α 和 β 用于控制2个任务在anchor对齐度量中的影响。 值得注意的是,t 在2个任务的联合优化中起着关键作用,以实现任务对齐的目标。 它鼓励网络从联合优化的角度动态关注高质量(即任务对齐)Anchor。
训练样本分配
对于每个gt,选择m个具有最大t值的anchor作为正样本点,其余的为负样本。
任务对齐损失
为了显式的增加对齐的anchor的得分,减少不对齐的anchor的得分,用t来代替正样本anchor的标签。
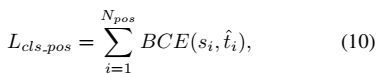
同时,借鉴了focal loss的思想,最后的损失函数如下
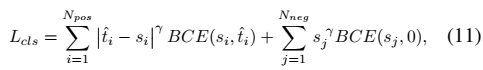
其中 j 表示 Nneg 个负anchors中的第 j 个anchors,γ 是focus参数。
定位损失函数和分类类似,使用归一化的t来对GIoU loss进行了加权:
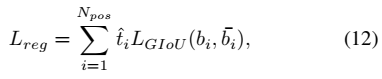
总的loss就是把这两个损失加起来。
- 实践应用
5.1 行为分析 🚶♂️
5.1.1 背景
行为识别在智慧社区,安防监控等方向具有广泛应用,根据行为的不同,PP-Human v2中集成了基于视频分类、基于检测、基于图像分类,基于行人轨迹以及基于骨骼点的行为识别模块,方便用户根据需求进行选择。
5.1.2 研究过程
基于骨骼点的行为识别,目前仅支持视频输入
应用案例:摔倒识别,智能健身

所用算法:
- 行人检测/跟踪 PP-YOLOE
- 关键点检测 HRNet
- 摔倒行为识别 ST-GCN
基于图像分类的行为识别,目前仅支持视频输入
应用案例:打电话识别
所用算法:
- 行人检测/跟踪 PP-YOLOE
- 打电话识别 PP-HGNet
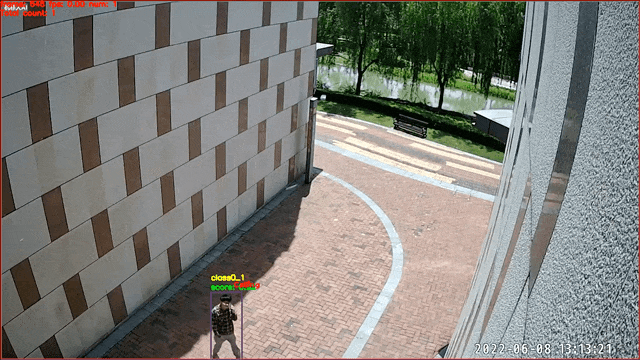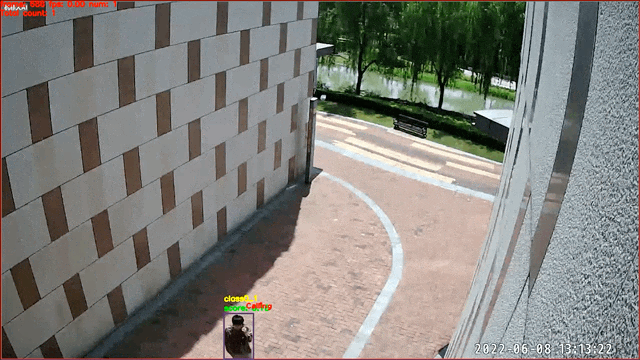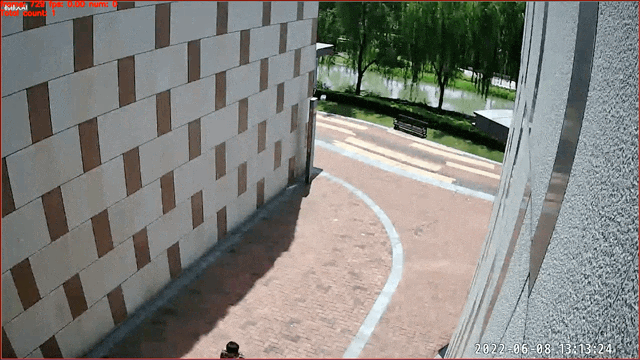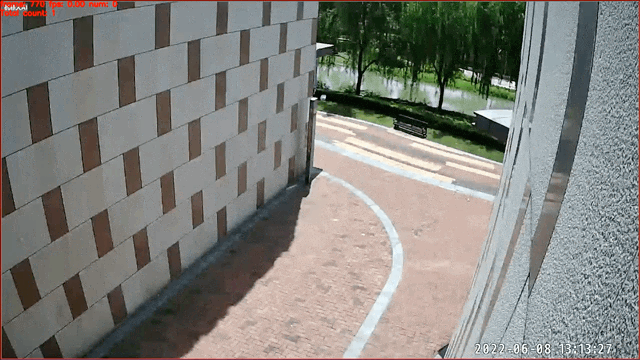
基于检测的行为识别,目前仅支持视频输入
所用算法:
- 行人检测/跟踪 PP-YOLOE
- 吸烟行为识别 PP-YOLOE
应用案例:抽烟识别

基于行人轨迹的行为识别,目前仅支持视频输入
所用算法:
行人检测/跟踪 PP-YOLOE
应用案例:闯入识别

基于视频分类的的行为识别,目前仅支持视频输入
所用算法:
视频分类:PP-TSM
应用案例:打架识别
5.1.3 结论
- 基于骨骼关键点的行为识别
采用关键点+序列预测,能够检测单个人体及人体关键点,并基于关键点序列变化识别行为。
优势
- 可以识别出每个人的行为
- 聚焦动作本身、鲁棒性和泛化性好
劣势
- 对关键点检测依赖较强、遮挡等情况效果不佳
- 无法准确识别多人交互动作
- 难以处理需要外观及场景信息的动作
应用场景
智能健身、摔倒行为识别
2. 基于图像分类的行为识别
采用检测+图像分类,对时序信息无依赖,动作可通过人+人或人+物的方式判断
优势
- 排除无关的背景干扰
- 简单、易于训练
- 数据采集和标注成本低
劣势
- 无法识别连续性动作
应用场景
打电话
3. 基于检测的行为识别
采用检测单个人体+判断动作,适用于行为与某特定场景强相关的场景,目标较小
优势
- 简单、易于训练
- 可解释性强
- 数据采集和标注成本低
劣势
- 无法识别连续性动作
- 对分辨率敏感
- 密集场景容易发生动作误匹配
应用场景
吸烟
4. 基于行人轨迹的行为识别
采用检测单个人体+跟踪人体、判断行为,适用于人体轨迹,与位置相关的场景
优势
- 简单、易于训练
- 数据采集和标注成本低
- 对密集遮挡鲁棒性较好
劣势
- 无法识别人体自身动作
应用场景
闯入
5. 基于视频的行为识别
直接基于视频进行动作分类,涉及多人目标场景,对背景依赖较强
优势
- 利用背景和时序信息
- 不依赖检测及跟踪模型
- 可处理多人协同动作
劣势
- 场景泛化能力较弱
- 无法定位到具体某个人的行为
应用场景
打架
5.2 车辆分析 🚗
5.2.1 背景
交通是兴国之要、强国之基。随着城市的快速发展、车辆和行人数量的日益增多,强依赖人力管控的传统交通治理模式在交通拥堵治理、信号调控、秩序改善等典型场景上,都遇到效率低下、人员监管成本高、错误率高的种种挑战。
针对城市轨道交通、道路交通及高速公路,提供围绕车、路、环境的智能感知与分析能力工具,助力用户快速实现车流监控、车辆跟踪定位、异常停留/违停检测、车牌识别、车辆颜色与型号识别等10余种任务,从而缓解交通拥堵、改善交通状况,发挥城市交通最大效能。
5.2.2 研究过程
整体方案:
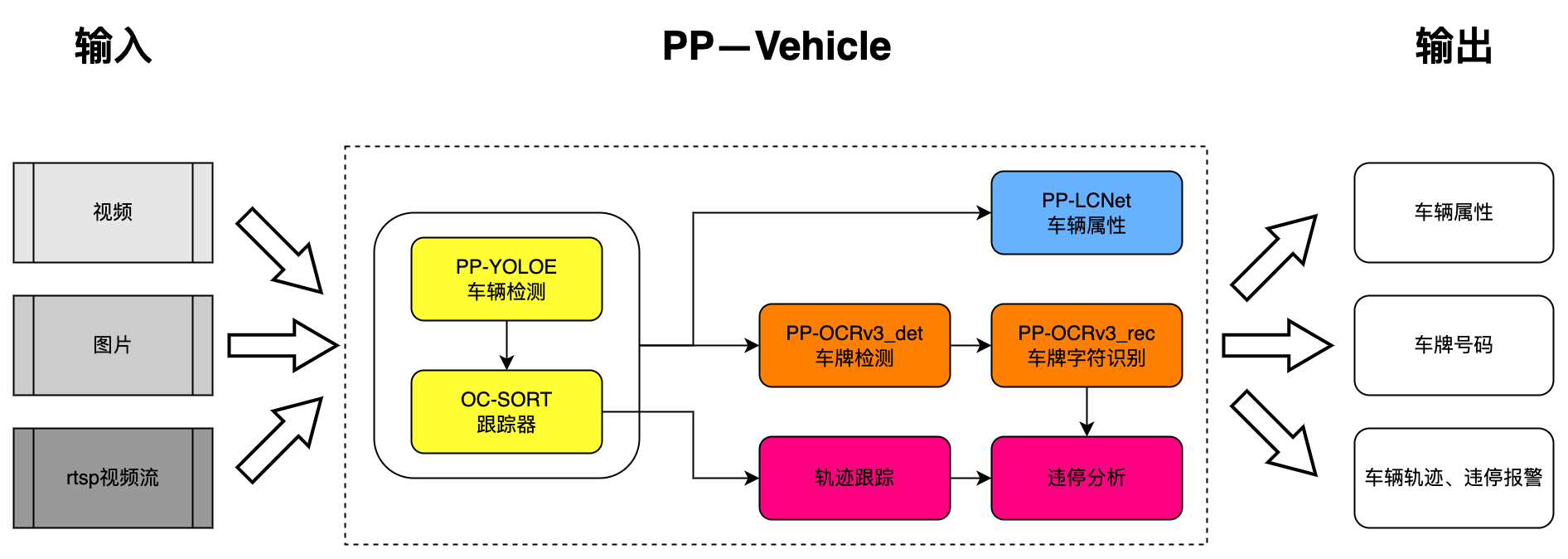
车牌号码识别
所用算法:
- 车辆检测 PP-YOLOE-l
- 车牌检测 PP-OCRV3_det
- 车牌字符识别 PP-OCRV3_rec

车辆属性分析
所用算法:
- 车辆检测 PP-YOLOE
- 车辆属性识别 PPLCNet


违章检测
基于跟踪算法获取每辆车的轨迹,如果车辆中心在违停区域内且在规定时间内未发生移动,则视为违章停车
(1) 车辆检测 PP-YOLOE-l
(2)车牌检测 PP-OCRV3_det
(3)车牌字符识别 PP-OCRV3_rec
1. 车辆检测 PP-YOLOE-l
2. 车辆跟踪 PP-YOLOE-S

5.2.3 结论
测试了车牌识别,与目前已有能力方法相比,多加了个车辆检测模型,效果较好。车辆属性、违章、计数大都基于视频数据集,测试了图片数据集,效果一般,泛化性需进一步验证。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









