







目录
MarkWord
首先来看看64位jvm中java对象在堆中是怎样存放的。
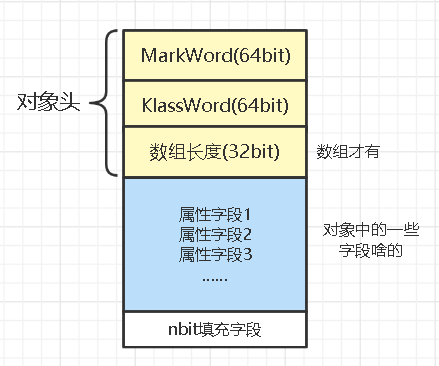
Java对象头分为64bit的MarkWord字段,它用来存放该对象的锁信息、hashcode、GC等信息,另外还有一个64bit的KlassWord字段,指向方法区中Class信息的指针,意味着该对象可随时知道自己是哪个Class的实例。如果是数组的话还会多出一个32bit的数组长度字段。
我们主要关注的是MarkWord那一段,如下:
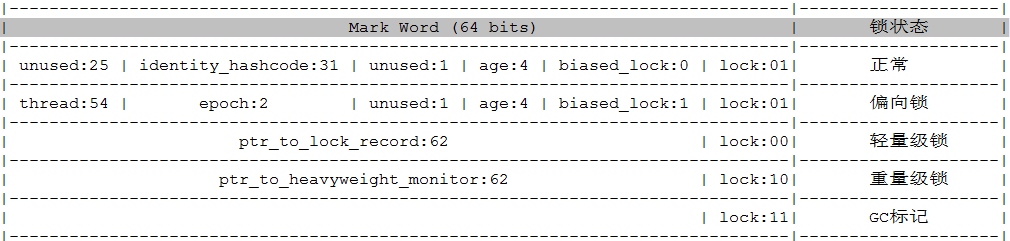
通过MarkWord的最后2bit,区别当前对象处于何种状态
Monitor
Monitor被翻译为监视器或管程,管程就是synchronized的原理
管程
管程是在os中是生产者和消费者的一种概念,是一种高级的进程互斥和同步机制,比信号量机制更简单易用。
管程的定义就差不多是一个类,类中定义了一个缓冲区,生产者和消费者操作这个类中的内部函数对缓冲区进行取或者放,每次仅允许一个进程(或线程)在管程内执行某个内部函数,这也保证了一个时间段只有一个进程或线程能够访问缓冲区,且这种互斥访问特性是由编译器负责实现的。
管程每次只允许一个进程或线程进入,如果有互斥访问的线程,就会在条件变量中进行等待,等待出来的线程唤醒它。
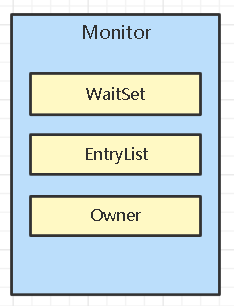
如上图:Monitor对象一般都会带有WaitSet和EntryList,其中的Owner是当前已经进入的线程,可以说出是该Monitor对象的主人;EntryList一个阻塞队列,等待Owner执行完后唤醒的一些等待的线程;WaitSet是一个也是一个集合,存放那些之前获得过锁但是运行时,条件不满足进入WAITING状态的线程。
管程之所以被说是一个类,是因为管程采用了封装的思想,把复杂的细节隐藏了,我们只需要调用管程提供的特定“入口”就能实现进程同步/互斥了
synchronized与管程
每一个Java对象都能关联一个Monitor管程对象,如果使用synchronized给java某个对象上锁(重量级锁)之后,该对象头的MarkWord就会指向关联的Monitor对象的指针(Monitor),请看MarkWord中的重量级锁的前62bit就是用来存放这一指针的。
管程Monitor类是操作系统中的一个数据结构,底层实现我们不可见
大致流程:
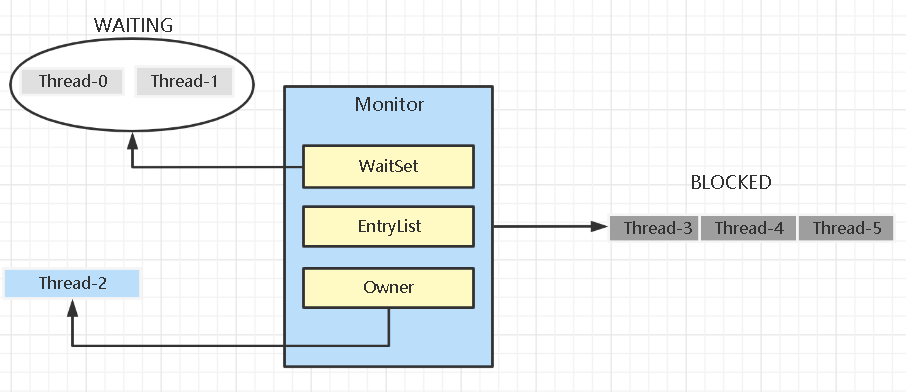
- 当线程执行到synchronized时就会尝试找一个Monitor对象与该synchronized中锁的对象关联
- 关联成功后,把该对象MarkWord后两位状态改为从10(重量级锁),前62位变为一个指向Monitor的指针
- 刚开始Monitor中的Owner为null
- 当Thread-1执行到synchronized(obj)时就会将Monitor的所有者Owner置为Thread-1,Monitor中只能有一个Owner
- 如果有其他线程也执行到synchronized时,就会进入EntryList BLOCKED
- 当Thread-1执行完后,会唤醒EntryList中等待的线程,互相竞争锁
- WaitSet中的线程是之前获得过锁,但条件不满足进入WAITING状态的线程
- synchronized 必须是进入同一个对象的monitor才有上述的效果,不同的锁对象Monitor不同
- 不加synchronized的对象不会关联监视器,不遵从以上规则
程序中的synchronized对应的jvm指令为monitorenter和monitorexit。一个进入Monitor,一个退出Monitor。
锁
Monitor管程是操作系统的东西,如果我们每次都碰到synchronized都去获取操作系统的Monitor也可以,但是有些情况是不必要的,所以jvm为了提高性能,对锁进行了优化,衍生出其他的比较轻量的锁。
一、轻量级锁
轻量级锁的使用场景:如果一个对象虽然有多线程访问它,但多线程访问的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化,如果发现有竞争了才会升级为重量级锁。
轻量级锁对使用者是透明的,即语法仍然是synchronized,遇到synchronized会优先使用轻量级锁。
假设有两个方法同步块,利用同一个对象加锁,同一个线程执行method1再执行method2
public static Object obj=new Object();
public static void method1(){
synchronized (obj){
method2(); //锁重入
}
}
public static void method2(){
synchronized (obj){//加锁了两次
//同步代码块
}
}官方名词:Displace MarkWord(替换MarkWord)
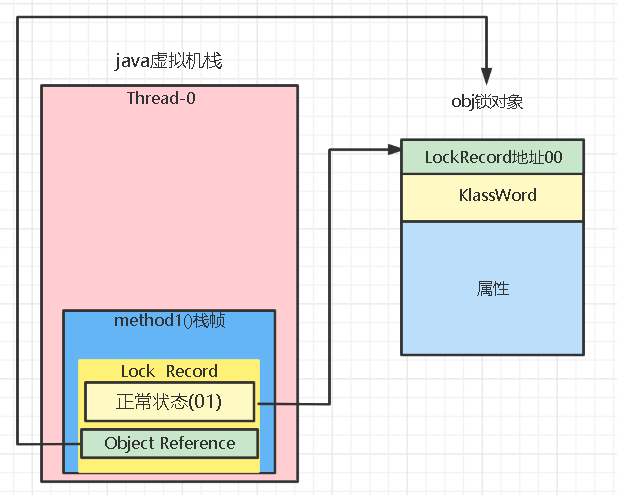
1.执行到method1的synchronized,创建锁记录(Lock Record)对象:每个线程的栈帧都会包含一个锁记录的结构,锁记录内部可以存储锁定对象的MarkWord。
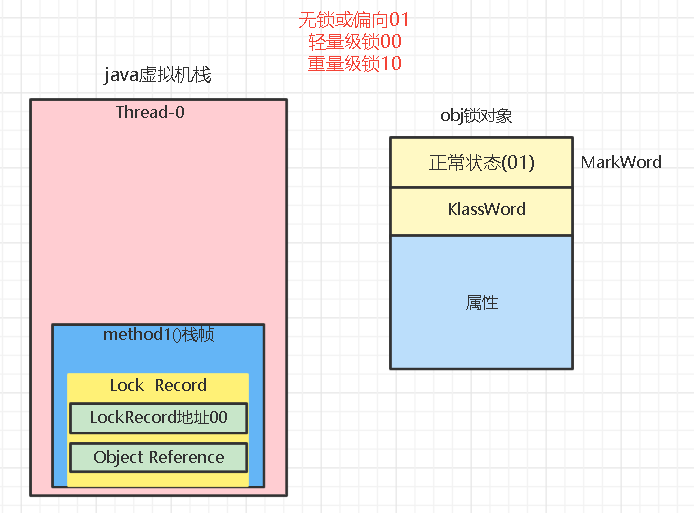
2.让锁记录中Object reference指向锁对象,并尝试用cas替换obj的Mark Word,将Mark Word的值存入锁记录,将锁记录的地址存入obj的MarkWord,这样交换就表示obj对象为一种加了轻量锁的状态。
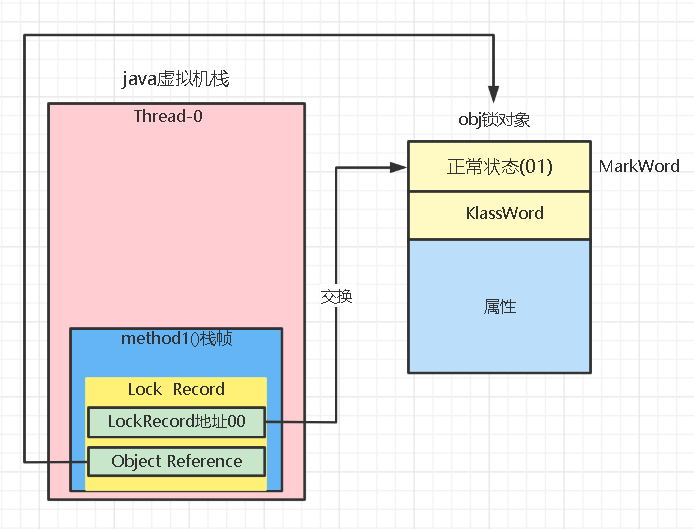
3.如果cas替换成功,则obj对象头中存放了锁记录地址和状态00,表示由该线程给对象加锁,锁记录保存了obj对象的MarkWord,这样的话如果obj对象要它的hashcode等信息的话,可以根据LockRecord的地址找到锁记录,并间接的拿到obj未加锁前的MarkWord。如下:
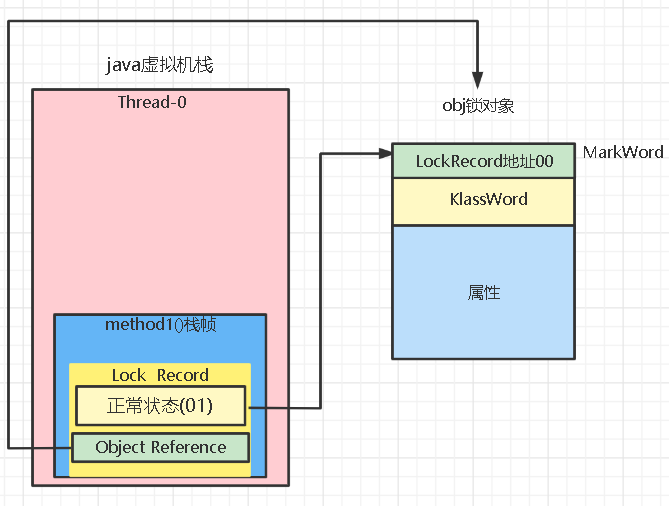
4. 如果cas失败,有两种情况:
- 如果obj后两位已经是00,表明其它线程已经持有了该Object的轻量级锁,这时表明有竞争,进入锁膨胀过程(后面有讲)。
- 如果是自己执行了synchronized锁重入,那么再添加一条Lock Record作为重入的计数。如下:method2再想交换MarkWord就会失败,因为obj的MarkWord上后两位为00,但是又因为是同一个线程,所以不会锁膨胀,只是单纯的多了一个LockRecord,表示该线程对obj锁了两次,解锁时也要解锁两次
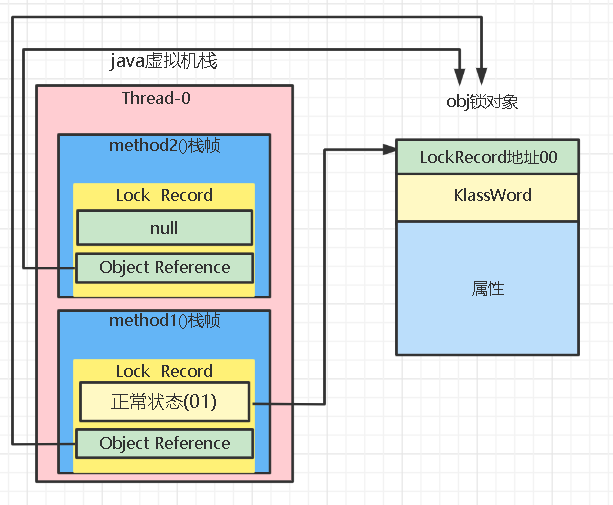
5.重入解锁,当退出synchronized代码块(解锁时)如果有取值为null 的锁记录,表示有重入,这时重置锁记录,表示重入计数减一。
6.当退出 synchronized代码块(解锁时)锁记录的值不为null,这时使用cas将 Mark Word的值恢复给对象头
-
恢复成功则解锁成功
-
恢复失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程
二、锁膨胀
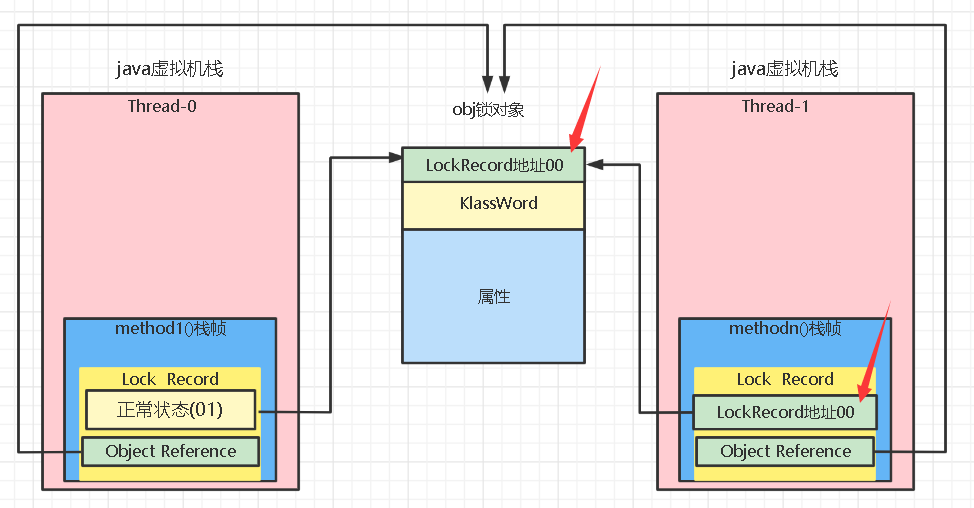
如果在尝试加轻量级锁的过程中,CAS操作无法成功,这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁。
如下:当Thread-1线程准备锁obj时发现obj的后两位为00,就会交换失败,交换失败了Thread-1应该阻塞等待Thread-0解锁,但是轻量级锁没有阻塞队列,只有重量级锁的Monitor采用,所以要转为重量级锁。
-
这时Thread-1加轻量级锁失败,进入锁膨胀流程
- 即为obj对象申请Monitor锁,让obj指向重量级锁地址,后两位变为10
- 然后自己进入Monitor的EntryList BLOCKED
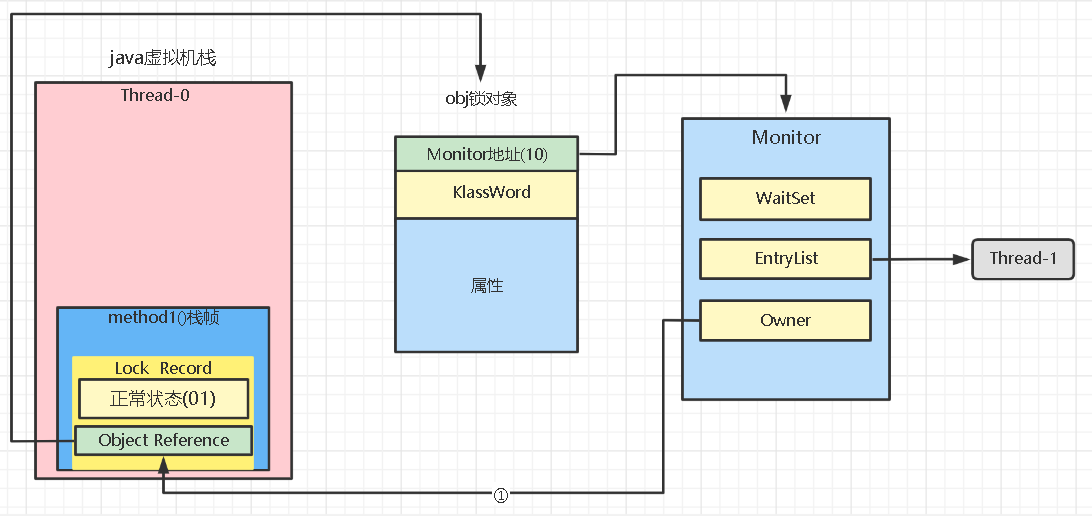
当Thread-0退出同步块解锁时,使用CAS将Mark Word的值恢复给对象头,将会交换失败,因为obj已经变为重量级锁状态了,不能用原来轻量级解锁的方法。
这时会进入重量级解锁流程,即按照Monitor地址找到Monitor对象,根据Owner从①那条线找到自己原来的的MarkWord,还原回来,再设置Monitor对象的Owner为null,唤醒EntryList中 BLOCKED线程,即解锁成功。
三、自旋优化
重量级锁竞争的时候,还可以使用自旋来进行优化,让当前线程执行一个忙循环(自旋操作),如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
自旋是发生在轻量级锁过程中的, 若在给定次数内自旋无法得到线程,则升级为重量级锁,在重量级锁条件下,所有线程都被阻塞。
- 在Java 6之后自旋锁是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,总之,比较智能。
- 自旋会占用CPU时间,单核CPU自旋就是浪费,多核CPU自旋才能发挥优势。
- Java 7之后不能控制是否开启自旋功能
四、偏向锁
轻量级锁在没有竞争时(就自己这个线程),每次重入仍然需要执行CAS操作。偏向锁是针对轻量级锁升级的
Java 6中引入了偏向锁来做进一步优化:只有第一次使用CAS将线程ID设置到对象的Mark Word头,之后发现这个线程ID是自己的就表示没有竞争,不用重新CAS。以后只要不发生竞争,这个对象就归该线程所有
public static Object obj=new Object();
public static void method1(){
synchronized (obj){
method2();
}
}
public static void method2(){
synchronized (obj){
method3();
}
}
public static void method3(){
synchronized (obj){
log.debug("method3");
}
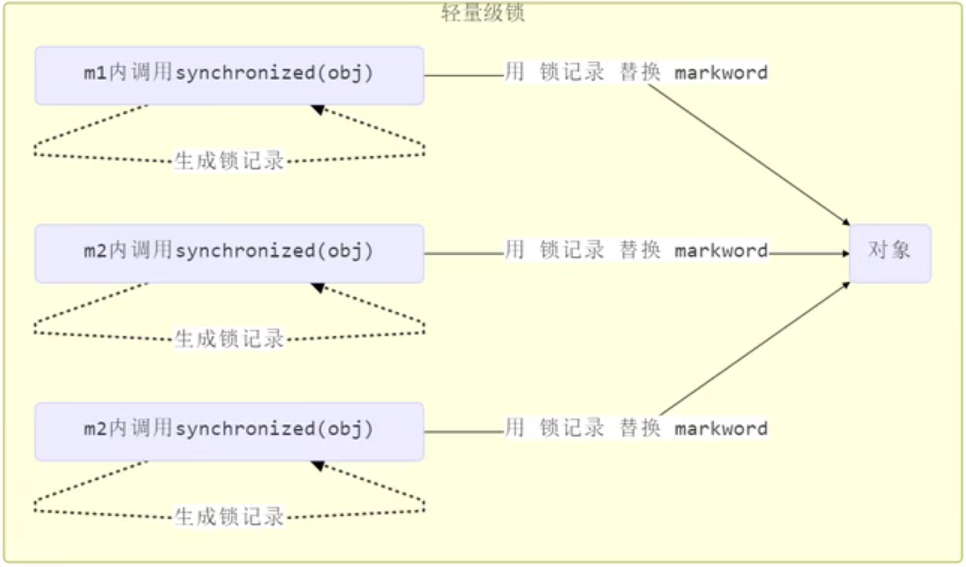
}轻量级锁和偏向锁的区别:

Java15默认不开启,可以通过配置开启偏向锁
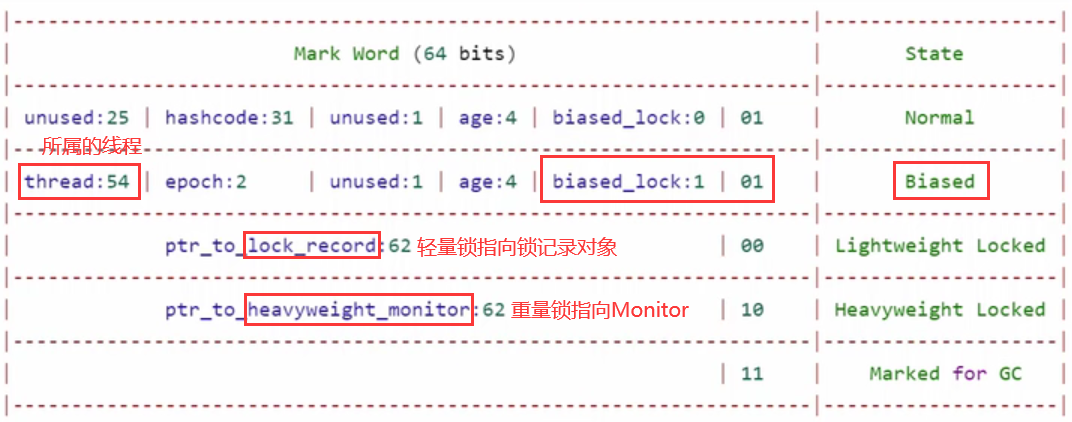
如上图:偏向锁和正常状态的区别在倒数第3bit,偏向锁的为1,正常状态为0,偏向锁的前54bit存放所属的线程id。
对象创建时:
- 如果开启了偏向锁(默认开启),那么对象创建后,markword值为0x05即最后3位为101,这时它的thread、epoch、age都为0
- 偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加VM参数-XX:BiasedLockingStartupDelay=0来禁用延迟
- 如果没有开启偏向锁,那么对象创建后,markword值为0x01即最后3位为001,这时它的hashcode age都为0,第一次用到hashcode时才会赋值
- 在上面测试代码运行时在添加JVM参数-XX:-UseBiasedLocking禁用偏向锁。
查看对象头
使用jol查看对象头的MarkWord信息,加入依赖:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>测试:
//-XX:-UseCompressedOops 使用此参数关闭指针压缩,所以Klass字段占用8字节,否则开启的话为4字节
//-XX:BiasedLockingStartupDelay=0 关闭偏向锁的延迟
Dog a = new Dog();//Dog类里面有个int型的成员变量
//打印对应的对象头信息
System.out.println(ClassLayout.parseInstance(a).toPrintable());结果为:可以看到对象头信息为偏向状态,且前面的所属线程id字段都为0。

查看hashcode
从64位jvm对象头可知,无锁的情况下MarkWord中前56bit(31+25)存放对象的hashcode。
代码如下:此代码没有关闭偏向锁的延迟,所以查看的是正常状态
Dog a = new Dog();
System.out.println("before hash");
System.out.println(ClassLayout.parseInstance(a).toPrintable());
System.out.println("jvm计算HashCode-------"+Integer.toHexString(a.hashCode()));
System.out.println("after hash");
System.out.println(ClassLayout.parseInstance(a).toPrintable());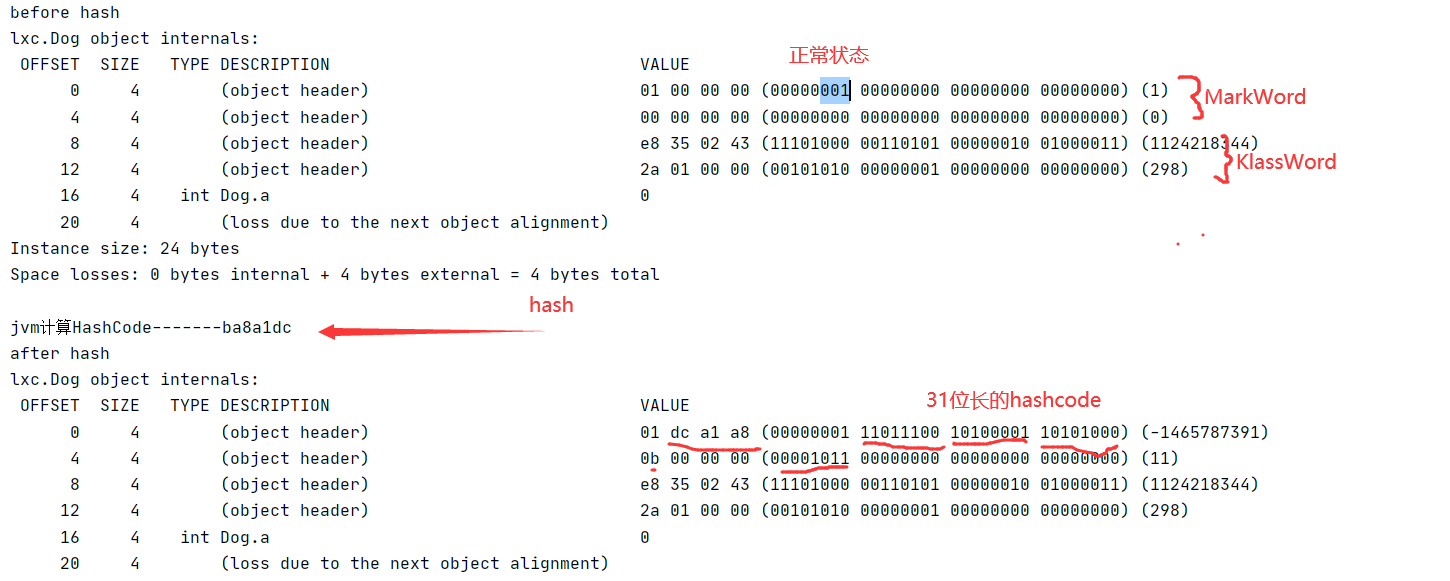
可以看到我们在没有进行hashcode运算的时候,所有的值都是空的。当我们计算完了hashcode,对象头就是有了数据。因为是小端存储,所以你看的值是倒过来的。前25bit没有使用所以都是0,后面31bit存的hashcode,所以第一个字节中八位存储的分别就是分代年龄、偏向锁信息、对象状态,
小端存储指从内存的低地址开始,先存储数据的低序字节再存高序字节;相反,大端存储指从内存的低地址开始,先存储数据的高序字节再存储数据的低序字节。
查看偏向锁
关于对象状态一共分为五种状态,分别是无锁、偏向锁、轻量锁、重量锁、GC标记,但是2bit只能表示4种状态(00,01,10,11)JVM的做法将偏向锁和无锁的状态表示为同一个状态,然后根据图中偏向锁的标识再去标识是无锁还是偏向锁状态。
//-XX:BiasedLockingStartupDelay=0关闭延迟
Dog a = new Dog();
System.out.println("before lock");
System.out.println(ClassLayout.parseInstance(a).toPrintable());
synchronized (a){ //上偏向锁
System.out.println("locking");
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
System.out.println("after lock");
System.out.println(ClassLayout.parseInstance(a).toPrintable());结果为
before lock
lxc.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE //表示偏向锁状态,线程id为0
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) f0 34 02 a4 (11110000 00110100 00000010 10100100) (-1543359248)
12 4 (object header) 65 01 00 00 (01100101 00000001 00000000 00000000) (357)
locking
lxc.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE //后面的54位为Thred的ID
0 4 (object header) 05 a0 ad 8b (00000101 10100000 10101101 10001011) (-1951555579)
4 4 (object header) 64 01 00 00 (01100100 00000001 00000000 00000000) (356)
8 4 (object header) f0 34 02 a4 (11110000 00110100 00000010 10100100) (-1543359248)
12 4 (object header) 65 01 00 00 (01100101 00000001 00000000 00000000) (357)
after lock
lxc.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 a0 ad 8b (00000101 10100000 10101101 10001011) (-1951555579)
4 4 (object header) 64 01 00 00 (01100100 00000001 00000000 00000000) (356)
8 4 (object header) f0 34 02 a4 (11110000 00110100 00000010 10100100) (-1543359248)
12 4 (object header) 65 01 00 00 (01100101 00000001 00000000 00000000) (357)
这时候大家会有疑问了,为什么在没有加锁之前是偏向锁,准确的说,应该是叫可偏向的状态,因为它后面没有存线程的ID,当locking的时候,后面存储的就是线程的ID,既然这儿存储是线程的ID,那么HashCode又存储到什么地方去了?是不是计算了HashCode就是不能偏向了?我们来验证一下,计算完HashCode,还是不是偏向锁了
hash破坏偏向锁
//在加锁前计算hash值
System.out.println("hash计算"+Integer.toHexString(a.hashCode()));结果为:
hash计算5cad8086 //计算了hashcode
before lock
lxc.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE //直接变为了正常状态,不是可偏向状态了
0 4 (object header) 01 86 80 ad (00000001 10000110 10000000 10101101) (-1384086015)
4 4 (object header) 5c 00 00 00 (01011100 00000000 00000000 00000000) (92)
8 4 (object header) 10 37 82 cd (00010000 00110111 10000010 11001101) (-847104240)
12 4 (object header) 1c 02 00 00 (00011100 00000010 00000000 00000000) (540)
locking //上锁
lxc.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE //变为轻量级锁
0 4 (object header) 68 f0 df 1d (01101000 11110000 11011111 00011101) (501215336)
4 4 (object header) cc 00 00 00 (11001100 00000000 00000000 00000000) (204)
8 4 (object header) 10 37 82 cd (00010000 00110111 10000010 11001101) (-847104240)
12 4 (object header) 1c 02 00 00 (00011100 00000010 00000000 00000000) (540)
after lock
lxc.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE //解锁轻量级锁换回的MarkWord,hashcode
0 4 (object header) 01 86 80 ad (00000001 10000110 10000000 10101101) (-1384086015)
4 4 (object header) 5c 00 00 00 (01011100 00000000 00000000 00000000) (92)
8 4 (object header) 10 37 82 cd (00010000 00110111 10000010 11001101) (-847104240)
12 4 (object header) 1c 02 00 00 (00011100 00000010 00000000 00000000) (540)我们可以发现:算出hashcode的时候,把对象变为了不可偏向的状态,locking的时候变成了轻量锁,after lock 的时候变成了无锁,所以我们得出对象计算了HashCode,就不是偏向锁了。
撤销偏向状态
1.调用了对象的hashCode,但偏向锁的对象MarkWord中存储的是线程id,如果调用hashCode 会导致偏向锁被撤销
- 轻量级锁会在锁记录LockRecord中记录hashCode
- 重量级锁会在Monitor中记录hashCode
2.当有其它线程使用偏向锁对象时,会将偏向锁升级为轻量级锁
线程在使用完偏向锁后不会主动释放,需要在有其他线程也要获取这个锁时,会设置对象上的锁为不可偏向状态,并且升级为轻量级锁(前提是多个线程错开使用,否则膨胀为重量级锁)
即当一个锁obj第一次被线程A加锁,偏向于A,A执行完了,obj还会一直偏向于A,但是此时B线程需要加锁obj了(A执行完了,AB交错执行),B锁定状态时obj是轻量级锁,B锁定结束后obj变为001不可偏向状态。
3.调用wait notify
wait方法直接将锁升级到重量级,才能释放monitor的owner
查看轻量锁
看完了偏向锁的对象头,我们再来看看轻量锁的对象头,轻量级锁尝试在应用层面解决线程同步问题,而不触发操作系统的互斥操作,轻量级锁减少多线程进入互斥的几率,不能代替互斥。
关闭偏向锁:
Dog a = new Dog();
System.out.println("before lock");
System.out.println(ClassLayout.parseInstance(a).toPrintable());
synchronized (a){
System.out.println("locking");
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
System.out.println("after lock");
System.out.println(ClassLayout.parseInstance(a).toPrintable());#before lock
OFFSET SIZE TYPE DESCRIPTION VALUE #001 normal
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 38 22 03 5f (00111000 00100010 00000011 01011111) (1594040888)
12 4 (object header) bf 01 00 00 (10111111 00000001 00000000 00000000) (447)
#locking
OFFSET SIZE TYPE DESCRIPTION VALUE #00 轻量锁
0 4 (object header) 88 f4 6f cb (10001000 11110100 01101111 11001011) (-881855352)
4 4 (object header) 3a 00 00 00 (00111010 00000000 00000000 00000000) (58)
8 4 (object header) 38 22 03 5f (00111000 00100010 00000011 01011111) (1594040888)
12 4 (object header) bf 01 00 00 (10111111 00000001 00000000 00000000) (447)
#after lock
OFFSET SIZE TYPE DESCRIPTION VALUE #001 nomal
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 38 22 03 5f (00111000 00100010 00000011 01011111) (1594040888)
12 4 (object header) bf 01 00 00 (10111111 00000001 00000000 00000000) (447)批量重偏向
如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程T1的对象仍有机会重新偏向T2,重偏向会重置对象的Thread ID
当撤销偏向锁阈值超过20次后,jvm 会这样觉得,我是不是偏向错了呢,于是会再给这些对象加锁时重新偏向至加锁线程,这里的撤销偏向锁不是撤销同一个对象的,而是一个线程中,有20个不同的对象累积被撤销20次。
如果一个线程偏向->轻量级多次 那么之后偏向就不会->轻量级 而是偏向->重偏向
批量撤销
当撤销偏向锁阈值超过40次后,jvm会这样觉得,自己确实偏向错了,根本就不该偏向。于是整个类的所有对象都会变为不可偏向的,新建的对象也是不可偏向的
循环40次的场景下:这个计数是针对某个类的对象,开始不管什么类的对象都累加
t1:全部偏向t1; t2:一半撤销为轻量,一半重偏向t2; t3:撤销重偏向于t2的20个对象。
这个时候也就撤销了40次了,下一次创建这个类的对象的时候,初始状态就是001的了,变为不可偏向状态
5.锁消除
锁消除是发生在编译器jit级别的一种锁优化方式。 有时候我们写的代码完全不需要加锁,却执行了加锁操作。这是编译器检测到了就可以同步消除。
1.
public static int x=0;
public static void method1() {
x++;
}
public static void method2() {
//每次新建一个局部对象,给他加锁
Object obj = new Object();
synchronized (obj) {
x++;
}
}测试后,method1和method2运行时间差不多
其实是JIT即时编译器,对代码进行了优化,发现obj对象不可能脱离该类的范围,不可能被共享,所以synchronized会被优化掉。
-XX:-EliminateLocks 可以关闭该优化,此时运行速度慢10几倍
2.
public static String createStringBuffer(String str1, String str2) {
StringBuffer sBuf = new StringBuffer();
sBuf.append(str1);// append方法是同步操作
sBuf.append(str2);
return sBuf.toString();
}append方法用了synchronized关键词,它是线程安全的。但我们可能仅在线程内部把StringBuffer当作局部变量使用:
代码中createStringBuffer方法中的局部对象sBuf,就只在该方法内的作用域有效,不同线程同时调用createStringBuffer()方法时,都会创建不同的sBuf对象,因此此时的append操作若是使用同步操作,就是白白浪费的系统资源。
这时我们可以通过编译器将其优化,将锁消除,前提是java必须运行在server模式(server模式会比client模式作更多的优化),同时必须开启逃逸分析:
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks
其中+DoEscapeAnalysis表示开启逃逸分析,+EliminateLocks表示锁消除。
逃逸分析:比如上面的代码,它要看sBuf是否可能逃出它的作用域?如果将sBuf作为方法的返回值进行返回,那么它在方法外部可能被当作一个全局对象使用,就有可能发生线程安全问题,这时就可以说sBuf这个对象发生逃逸了,因而不应将append操作的锁消除,但我们上面的代码没有发生锁逃逸,锁消除就可以带来一定的性能提升。
6.锁粗化
锁粗化就是告诉我们任何事情都有个度,有些情况下我们反而希望把很多次锁的请求合并成一个请求,以降低短时间内大量锁请求、同步、释放带来的性能损耗。
1.
public void doSomethingMethod(){
synchronized(lock){
//do some thing
}
//这是还有一些代码,做其它不需要同步的工作,但能很快执行完毕
synchronized(lock){
//do other thing
}
//粗化后-》
public void doSomethingMethod(){
//进行锁粗化:整合成一次锁请求、同步、释放
synchronized(lock){
//do some thing
//做其它不需要同步但能很快执行完的工作
//do other thing
}上面的代码是有两块需要同步操作的,但在这两块需要同步操作的代码之间,需要做一些其它的工作,而这些工作只会花费很少的时间,那么我们就可以把这些工作代码放入锁内,将两个同步代码块合并成一个,以降低多次锁请求、同步、释放带来的系统性能消耗
2.
for(int i=0;i<size;i++){
synchronized(lock){
}
}
//粗化后-》
synchronized(lock){
for(int i=0;i<size;i++){
}
}上面代码每次循环都会进行锁的请求、同步与释放,看起来貌似没什么问题,且在jdk内部会对这类代码锁的请求做一些优化,但是还不如把加锁代码写在循环体的外面,这样一次锁的请求就可以达到我们的要求,除非有特殊的需要:循环需要花很长时间,但其它线程等不起,要给它们执行的机会。















 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









