







目录
概述
悲观锁(Pessimistic Lock)
以前我们在实现线程安全问题时一般都是使用的锁方式来解决并发问题,如使用synchronized、ReentrantLock等,这种方式被称为悲观锁,因为每次进行操作前都需要先加上锁,也就是执行临界区代码时,一定是假设当前有很多其他线程在访问,为了百分之百的安全必须加锁,所以叫做悲观锁,所持有的是悲观态度。悲观锁,具有强烈的独占和排他特性。
乐观锁(Optimistic Locking)
今天我们要讲的是乐观锁,乐观锁假设数据一般情况不会造成并发冲突,持乐观态度,当真正的运行程序时才会检测是否有冲突,如果有的话则返回给用户异常信息,让用户决定如何去做。乐观锁是非阻塞的,没有之前的锁的同步等待的概念。乐观锁一般用于竞争不是很激烈的情况下,这样没必要每次都去加锁,也增加了系统的吞吐率。(乐观锁在java层面实则无锁),java实现这种乐观锁使用的是CAS操作。
悲观锁示例:
现在有一个取钱的类,类中的初始余额为100000,每一个线程没有withdraw(10),为了保证线程的安全性,保证最后的余额是对的,所以悲观锁的解决方法是加上synchronized关键字:
class Account {
//账户余额
public int balance = 100000;
public void withdraw(int balance) {
//同步操作
synchronized (this) {
this.balance -= balance;
}
}
}测试:
public static void main(String[] args) throws InterruptedException {
Account account = new Account();
List<Thread> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
Thread t = new Thread((() -> {
account.withdraw(10);
}));
list.add(t);
}
long start = System.currentTimeMillis();
//开始线程
list.forEach(Thread::start);
//等待全部线程完成
for (Thread thread : list) {
thread.join();
}
long end = System.currentTimeMillis();
//打印最后的余额
System.out.println("最后的账户余额为:"+account.balance+"---用时:"+(end-start)+"ms");
//最后的账户余额为:0---用时:647ms
}乐观锁示例:
class Account {
//账户余额,原子类
public AtomicInteger balance = new AtomicInteger(100000);
public void withdraw(int balance) {
while (true) { //循环的减去余额,因为如果冲突了,就会减余额失败,需要重新操作
int pre = this.balance.get(); //取到当前值
int update = pre - balance;//当前余额-需要取得余额=需要更新的余额
if (this.balance.compareAndSet(pre, update)){ //CAS操作
break;//CAS成功则退出循环
}
}
}
}最后的账户余额为:0---用时:605ms 比加锁的稍微快了一点
其中的关键是compareAndSet,简称CAS(Compare And Swap),CAS看起来是比较和交换两件事,但是在CPU级别上是原子的,不可分割的。
上述代码中一定不要省略了int pre=this.balance.get(),如果写成了:
int update = this.balance.get() - balance; if (this.balance.compareAndSet(this.balance.get(), update)){ break; }那就出问题了,因为update的值已经被确定了,但是CAS修改时,最新值可能已经被修改过了,此时update的值是一个脏数据.
上例的图解如下:

线程1采用自旋的方式不断的尝试修改值,直到修改成功。
其实CAS的底层是lock cmpxchg(X86架构),在单核cpu和多核cpu下都能够保证【比较-交换】的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
CAS与volatile
CAS操作必须借助volatile才能读取到共享变量的最新值来实现【比较并交换】的效果
CAS操作每次都是需要得到变量的最新值,然后进行比较并修改的,如果没有volatile,每次都得不到最新值,那么修改操作也就会失败。关于volatile请看:传送门。
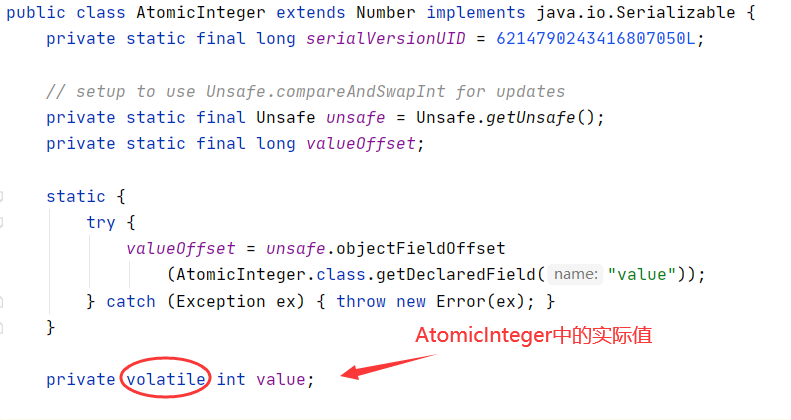
可看AtomicInteger源码,类中的value值已经被volatile修饰了,我们无须关心。
无锁效率分析
看了悲观锁和乐观锁的简单实例,我们再来分析分析这两种方式的效率。
1.加锁:当有多个线程访问临界区时,只有一个线程能给得到锁,其他线程此时会上下文切换进入阻塞状态,此时这些被阻塞的线程不会占用cpu资源,等待阻塞结束再上下文切换重新争夺锁。
2.无锁:当前线程执行临界区(即CAS操作看做是一个临界区),如果当前线程修改失败,被其他线程抢先一步的话,当前线程不会进入阻塞态,而是重新进入循环,重新进行临界区的操作,此时会一直占用cpu的资源,注意:虽然不会进入Java层面的阻塞,但由于没有分配到时间片,cpu任然可能会进行任务调度,将该线程变为就绪状态,进行上下文切换,只不过比阻塞的上下文切换的开销少。
这种阻塞的下上下文切换需要涉及到内核态到用户态的切换,一般情况下,多循环个几次更划算
我们再用实际情况演示执行演示一遍(只考虑只有两个线程运行的情况,其他干扰因素不考虑):
- 假设现在是8核的cpu,有两个线程,这两个线程刚好同时运行临界区:
如果使用加锁方式,线程A获取到锁后,线程B进入到阻塞状态,发生了上下文切换;而如果是无锁情况,线程A抢先进入了临界区,线程B一直自旋,线程B可以使用CPU的另一个核执行自旋操作,不会发生上下文切换。可以看出无锁的效率更高,因为没有发生上下文切换,
- 假设是只有1核的cpu:
那么线程B的自旋操作还是会和线程A进行争抢cpu时间片,因为只有一个核,所以这仅存的一个核会分时的执行线程A和线程B,这样AB都会发生上下文切换,导致效率变低。
cas只是减少了线程上下文切换的次数,并不是避免了线程上下文切换。
结论:这种CAS操作需要多核cpu才能发挥优势,且线程数不能太多,如果线程数超过了cpu核心数,效率也会相应的变低,所以当线程数较少核心数较多的情况下适合使用CAS,而线程数较多核心数较少的情况下更适合加锁。
CAS的特点
结合CAS和volatile可以实现无锁并发,适用于线程数少、多核CPU的场景下,且竞争较少。
- CAS是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
- synchronized是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你门都别想改,我改完了解开锁,你们才有机会。
- CAS体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
- 因为没有使用synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
原子操作类
juc提供了这样一些的原子类实现,我们来依次展开

原子整数
- AtomicBoolean(对boolean类型的封装)
- AtomicInteger(对int类型的封装)
- AtomicLong (对long类型的封装)
AtomicInteger
这三种类型基本使用方式相同。我们就以AtomicInteger为例进行讲解:
- get():取到最新的AtomicInteger内部维护的一个int vaule值
- boolean compareAndSet(int expect, int update):第一个参数为预期值,用期望值和AtomicInteger中维护的value最新值进行比较,如果和最新值一致则更改最新值为update,并且返回true,如果和最新值不一致则修改失败,返回false,通常配合while(true)使用
- getAndIncrement():先取到最新值然后让最新值进行+1操作,类似i++操作,不用说明预期值,方法也是原子的,不用配合while(true),更方便
- decrementAndGet():先给最新值减一,再取到最新值,类似--i操作,其他的都类似
- int getAndAdd(int num):先取到最新值,然后再给最新值加num
- addAndGet(int num):先加再获取值
- int updateAndGet(IntUnaryOperator updateFunction):可以使用任意的操作,如乘法除法等复杂运算。IntUnaryOperator是一个函数式接口,需要重写的方法int applyAsInt(int value);
就是我们的复杂运算,也能保证是原子操作,该接口十分灵活。 - getAndUpdate(IntUnaryOperator updateFunction):同上。但先取值再更新
IntUnaryOperator源码:
@FunctionalInterface
public interface IntUnaryOperator {
int applyAsInt(int operand);
}updateAndGet源码:其实就是是传进来一个如何操作的函数,然后再进行运算,循环的compareAndSet更新值。
public final int updateAndGet(IntUnaryOperator updateFunction) {
int prev, next;
do {
prev = get();
next = updateFunction.applyAsInt(prev);
} while (!compareAndSet(prev, next)); //循环调用compareAndSet
return next;
}实例:
AtomicInteger balance = new AtomicInteger(0);
//都是原子的操作,
int i = balance.incrementAndGet();//自增并获取值
int i1 = balance.getAndIncrement();//获取值并自增
int i2 = balance.getAndDecrement(); //取到值后自减
int i3 = balance.getAndAdd(100); //先取值 再加100
//读取的值 设置值
balance.updateAndGet(value->value*10/5);//Lambda表达式,通用操作AtomicInteger关键源码:就是掉用Unsafe类的方法,Unsafe见下文。
public class AtomicInteger extends Number implements java.io.Serializable {
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
//获得value域在该类中的偏移量
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
//CAS操作
public final boolean compareAndSet(int expect, int update) {
//实际是调用了unsafe的操作,实现原子性
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
}原子布尔型的类其实底层还是使用的int,把boolean改为int再执行Unsafe的CAS操作
原子引用
- AtomicReference
- AtomicStampedReference
- AtomicMarkableReference
如果需要用到一些引用类型只能用原子引用。
AtomicReference
我们对前面的取钱的类进行改写,余额不再是整数,而是BigDecimal引用,实现超大余额和小数的存储:
class Account {
//原子引用类使用AtomicReference,泛型是我们需要的引用类型
public AtomicReference<BigDecimal> balance = new AtomicReference<>(new BigDecimal("100000"));
public void withdraw(BigDecimal amount) {
while (true) {
//取到当前最新值
BigDecimal pre = balance.get();
//减去余额,返回的是一个新的对象,需要更新value值
BigDecimal update = pre.subtract(amount);
if (balance.compareAndSet(this.balance.get(), update)) {//CAS
break;//CAS成功则退出循环
}
}
}
}如上:AtomicReference更原子整数的用法基本相同,只不过AtomicReference比较的是对象的引用地址,而不是比较equals,更新引用中的字段属性是没有影响的。如下:
@Slf4j
public class Demo {
static Person A = new Person("A");
static Person B = new Person("A");
static AtomicReference<Person> atomicReference = new AtomicReference<>(A);
public static void main(String[] args) throws InterruptedException {
System.out.println(A.equals(B));//true,Person重写了equals和hashcode方法
//比较失败因为A的引用不等于B的引用
log.debug("{}",atomicReference.compareAndSet(B, A));//false
A.name="B";//修改类中的字段值
log.debug("{}",atomicReference.compareAndSet(A, B));//true
}
}ABA问题
如下一段代码,主线程先获取到当前的最新值value值为A,当他想要更新A为C前,其他线程抢先一步,把最该最新值A改为了B,又有其他线程把最新值从B改回成了A,此时主线程才开始执行CAS操作,按理来说主线程先前获取的最新值pre已经不是最新值了,因为被别的线程改过,但是主线程是不知道的,他一对比发现pre值和当前最新值引用一致,所以就进行了CAS操作把A改为了C,这就是ABA问题
@Slf4j
public class Demo {
static Person A = new Person("A");
static Person B = new Person("B");
static Person C = new Person("C");
//初始为A
static AtomicReference<Person> atomicReference = new AtomicReference<>(A);
public static void main(String[] args) throws InterruptedException {
Person pre = atomicReference.get();//得到当前最新值A
other();//模拟其他线程对原子引用的更改
Thread.sleep(1000);
log.debug("A->C {}", atomicReference.compareAndSet(pre, C));//true
// 17:35:36.661 [Thread-0] - 210 A->B true
// 17:35:36.771 [Thread-1] - 320 B->A true
// 17:35:37.781 [main] - 1330 A->C true
}
static void other() throws InterruptedException {
new Thread(() -> {
log.debug("A->B {}", atomicReference.compareAndSet(atomicReference.get(), B));//true
}).start();
Thread.sleep(100);
new Thread(() -> {
log.debug("B->A {}", atomicReference.compareAndSet(atomicReference.get(), A));//true
}).start();
}
}问题分析:在某些场景下,虽然主线程对比发现先前的值和现在的最新值是相同的,但是毕竟这个值是被修改了两次的,应该算是不一致的值,所以主线程应该修改失败,所以就出现了问题。
如果要解决该问题,让主线程能够知道其他线程修改过该值的的话,可以使用下面的原子引用类。
AtomicStampedReference
只要有其它线程【动过了】共享变量,那么自己的CAS就算失败,这时,仅比较值是不够的,需要再加一个版本号。版本号的作用是:哪个线程修改了值,就把当前版本号加一,且做CAS操作时需要比较版本号,版本号相同才能CAS成功。
- int getStamp():获取版本号,是一个int类型的值
- V getReference():得到当前最新引用值
- public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp):比以前的原子类多了一个期望版本号和新的版本号,不仅引用值要一致,而且版本号也要一致才能修改 ,再指定一个新的版本号即可,一般新版本号加一即可
示例:
//构造方法需要指明初始版本号,这里指定为0
static AtomicStampedReference<Person> asr = new AtomicStampedReference<>(A, 0);
public static void main(String[] args) throws InterruptedException {
//获取版本号,得到0
int stamp = asr.getStamp();
//获取当前最新值引用
Person pre = asr.getReference();
other();//模拟其他线程对原子引用的更改
Thread.sleep(1000);
log.debug("A->C {}", asr.compareAndSet(pre, C, stamp, stamp + 1));//false,因为最新版本号为2了,不一致
log.debug("最新版本号为:{}",asr.getStamp());
//18:31:38.575 [Thread-0] - 198 A->B true
//18:31:38.681 [Thread-1] - 304 B->A true
//18:31:39.693 [main] - 1316 A->C false
//18:31:39.693 [main] - 1316 最新版本号为:2
}
static void other() throws InterruptedException {
new Thread(() -> {
int stamp = asr.getStamp();
log.debug("A->B {}", asr.compareAndSet(asr.getReference(), B, stamp, stamp + 1));//true
}).start();
Thread.sleep(100);
new Thread(() -> {
int stamp = asr.getStamp();
log.debug("B->A {}", asr.compareAndSet(asr.getReference(), B, stamp, stamp + 1));//true
}).start();
}其他的都差不多。
AtomicMarkableReference
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A-> B-> A -> C,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。 但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference,它的版本号不是int类型的了,而是一个布尔类型的,因此只有两种状态。
- boolean isMarked():获取最新的状态标记
该类就不过多解释了。
原子数组
- AtomicIntegerArray(数组元素是int类型的)
- AtomicLongArray(数组元素是long类型的)
- AtomicReferenceArray (数组元素是引用类型的)
如果改变了数组中的元素,那么就被视为不一致了,多线程下数组的元素更改是不安全的,所以需要原子数组。
AtomicIntegerArray
- compareAndSet(int index, int expect, int update):需要加上数组下标
- get(int index):获取对应下标值
- AtomicIntegerArray(int length):构造方法指定一个数组长度,源码就是new int[length]
看如下一段代码:对原子数组和非原子数组做了一个对比,结果也很明显,原子数组是正确的,非原子数组结果不正确
public class Demo {
//指定原子数组长度,元素类型为int型
static AtomicIntegerArray asr = new AtomicIntegerArray(10);
static int[] array = new int[10];
public static void main(String[] args) throws InterruptedException {
ArrayList<Thread> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {//10个线程
Thread t = new Thread(() -> {
for (int j = 0; j < 10000; j++) { //循环10000次,轮流的给10个下标加一
array[j % 10]++;//原始的数组
//CAS原子数组的元素
while (true) {
int pre = asr.get(j % 10);
if (asr.compareAndSet(j % 10, pre, pre + 1)) {
break;
}
}
//asr.getAndIncrement(j%10);可代替
}
});
list.add(t);
}
list.forEach(Thread::start);
for (Thread t : list) {
t.join();
}
System.out.print("原始数组类型:");
for (int i : array) {
System.out.printf("%d ", i);
}
System.out.println();
System.out.print("原子数组类型:");
for (int i = 0; i < asr.length(); i++) {
System.out.printf("%d ", asr.get(i));
}
//原始数组类型:9830 9808 9751 9726 9730 9716 9705 9704 9713 9652
//原子数组类型:10000 10000 10000 10000 10000 10000 10000 10000 10000 10000
}
}其他的没了,用法差不多。
字段更新器
- AtomicIntegerFieldUpdater(属性是int类型的)
- AtomicLongFieldUpdater (属性是long类型的)
- AtomicReferenceFieldUpdater(属性是引用类型的)
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合volatile修饰的字段使用,否则会出现异常。
上面的原子引用类型是保护的指针的地址,它是看不到对象中的属性被更改的,字段更新器保护的是引用的属性,而不是引用的指针地址。
AtomicReferenceFieldUpdater
- AtomicReferenceFieldUpdater<U,W> newUpdater(Class<U> tclass, Class<W> vclass, String fieldName):用于构造AtomicReferenceFieldUpdater对象的方法,不能用普通的构造方法了。第一个参数是引用对象的类型,第二个是引用字段的类型,第三个是字段名称。
- boolean compareAndSet(T obj, V expect, V update):第一个参数是监听具体哪个对象的字段。
演示:
@Slf4j
public class Demo {
//Person类中有一个String name的属性,且是volatile修饰的
static AtomicReferenceFieldUpdater<Person, String> arf =
AtomicReferenceFieldUpdater.newUpdater(Person.class, String.class, "name");
public static void main(String[] args) throws InterruptedException {
//新建一个对象,用于监视该对象name属性的更改
Person person = new Person("A");
log.debug("A->B {}", arf.compareAndSet(person, "C", "B"));
log.debug("{}", person.name);
//10:33:09.859 [main] A->B false
//10:33:09.862 [main] A
}
}原子累加器
父类:Striped64
- LongAccumulator
- LongAdder
- DoubleAccumulator
- DoubleAdder
专门做累加的原子类(可加可减的),之前的原子整数也可以实现,只不过该类的效率更高,更适合做单纯的累加操作。
LongAdder
@Slf4j
public class Demo {
static AtomicLong al=new AtomicLong(0);
static LongAdder la=new LongAdder();
public static void main(String[] args) throws InterruptedException {
List<Thread> list=new ArrayList<>();
for (int i = 0; i < 5; i++) {
Thread t=new Thread(()->{
for (int j = 0; j < 500000; j++) {
// al.incrementAndGet();
la.increment();//每次加一
}
});
list.add(t);
}
long start = System.currentTimeMillis();
list.forEach(Thread::start);
for (Thread thread : list) {
thread.join();
}
long end = System.currentTimeMillis();
// log.debug("花费了{}ms,结果为{}",end-start,al.get());//花费了50ms,结果为2500000
log.debug("花费了{}ms,结果为{}",end-start,la.longValue());//花费了18ms,结果为2500000
}
}性能提升的原因:在有竞争时,设置多个累加单元,Thread-0累加Cell[0],而Thread-1累加Cell[1]……最后将结果汇总。这样它们在累加时操作的不同的Cell变量,因此减少了CAS重试失败,从而提高性能。
Striped64源码如下:
//累加单元数组,懒惰初始化
transient volatile Cell[] cells;
//基础值,如果没有竞争,则会用cas累加这个域
transient volatile long base;
//在cells创建或扩容时,值为1,表示加锁
transient volatile int cellsBusy;
@sun.misc.Contended //防止缓存行伪共享的注解
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
//用于cas方式进行累加
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
}
Unsafe
之前讲解的cas操作,底层都是调用的Unsafe类的方法。Unsafe对象提供了非常底层的,操作内存、线程的方法。
Unsafe对象不能直接调用,需要用反射实例化对象。如下:
@CallerSensitive
public static Unsafe getUnsafe() {
……
}Unsafe类的构造方法是private的,可以使用getUnsafe方法获取,但是该方法上面有个 @CallerSensitive注解,该注解可以检测到你调用的类是哪个类加载器加载的,如果是系统的类那就没什么问题,如果是我们自己建的类调用该方法,会抛java.lang.SecurityException异常,可以走捷径设置jvm参数让bootstrap类加载器加载我们的类,就不会有异常。
但是一般不会这么做,一般通过反射调用,获取Unsafe对象:
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);误用的话会不安全,所以取名Unsafe。直接用unsafe对象,线程安全的去修改对象里面的类变量。底层是通过内存偏移量并交换。
CAS示例:
@Slf4j
public class Demo {
public static void main(String[] args) throws InterruptedException, NoSuchFieldException, IllegalAccessException {
Unsafe unsafe = getUnsafe();
//获取域中对应的偏移量, 类中的每个域的偏移地址都是固定不变的
long idOffset = unsafe.objectFieldOffset(Person.class.getDeclaredField("id"));
long nameOffset = unsafe.objectFieldOffset(Person.class.getDeclaredField("name"));
long ageOffset = unsafe.objectFieldOffset(Person.class.getDeclaredField("age"));
log.debug("id的偏移量为:{},name的偏移量为:{},age的偏移量为:{}", idOffset, nameOffset, ageOffset);
Person person = new Person(1, "张三", 18);
//执行cas操作 //对象, 偏移量, 最新值, 要改变的值
unsafe.compareAndSwapInt(person, idOffset, person.getId(), 2);
unsafe.compareAndSwapObject(person, nameOffset, person.getName(), "李四");
unsafe.compareAndSwapInt(person, ageOffset, person.getAge(), 20);
log.debug("{}", person);
}
public static Unsafe getUnsafe() throws NoSuchFieldException, IllegalAccessException {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
}
}
@Data
@ToString
class Person {
private int id;
private String name;
private int age;
public Person(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
}结果为
id的偏移量为:12,name的偏移量为:20,age的偏移量为:16
Person(id=2, name=李四, age=20)
这里的偏移量是根据jvm底层判定的,首先会把int的排在前面所以就出现了违反顺序的偏移量
关于CAS的操作,Unsafe提供了:
- compareAndSwapObject
- compareAndSwapInt
- compareAndSwapLong
如果要使用short、char等类型,我们只需要简单的转为int就行了。
可以根据一些原子类的源码来写出自己的原子类,并不复杂。
参考:















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









