







我们上一讲已经拿到了完整的 html 页面,这一讲我们来对我们要爬取的页面进行分析,然后去读取相应的数据
一、页面分析
打开我们要爬的页面,然后鼠标右键,选择检查

不难发现,我们要爬取的内容,都在一个 id 为 post_list 的 div 块中,也就是说,我们要先拿到这个 div。
接着再来看
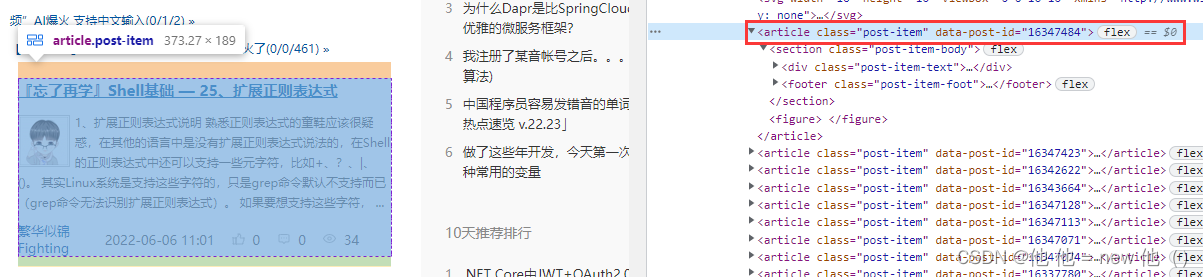
每一个博客都是扔在了 article 标签中,那也就是说我们再去拿这个标签,然后里面有各种 div、a、span 标签,这些里面有我们需要的内容,解析这些内容即可。
总的来说其实还是比较容易的,现在我们来通过代码进行实现~
二、解析 html 页面
解析 html 页面,我们主要用到了一个叫 Jsoup 的解析器,同样,建议大家也去它官网上看看它的 API 接口,不是很难。除去 Jsoup 之外,还要看一个东西:XPath,这个东西也是我们要用的一个玩意,比较有趣,它的话直接去菜鸟教程、W3school 学一下就好。
1. 获取 id 为 post_list 的 div 块
...
for(int i = 1; i <= 1; i++) {
HtmlPage page = webClient.getPage(taskUrl + i);
List<DomElement> blogMainDiv = page.getByXPath("//div[@id='post_list']");
}
...这里我们直接用 page 通过 XPath 的方式进行获取。简单解释一下 //div[@id='post_list'] 这个东西
- //:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
- div[@id='post_list']:获取 id 为 post_list 的 div 模块。
这里我们就可以得到一个 List 集合(因为它可能根据 XPath 解析出多条记录,所以返回的是 List 集合)。
但是!既然这里是返回的一个 List,我们还不如直接再往深拿一下。

再来观察页面,可以看到,我们要的东西其实都是在 section 中,也就是说,我们完全可以通过 XPath 拿到 section List,然后去解析 section 下面的东西,所以说我们来修改一下我们刚刚写的代码~
List<DomElement> blogMainDiv = page.getByXPath("//div[@id='post_list']/article/section");2. 获取博客标题
上面拿到 DomElement List 之后,我们来循环它,然后通过 Jsoup 将 DomElement 转换成 Document,这样我们通过操作 Document 就可以了。
Jsoup 的 Document 有一个方法,就是通过 css 标签获取到 Element 或 Elements 结构的数据,这样我们其实就可以得到博客标题所在的 a 标签了。
List<DomElement> blogMainDiv = page.getByXPath("//div[@id='post_list']/article/section");
for(DomElement x : blogMainDiv) {
Document document = Jsoup.parse(x.asXml());
Element section_div = document.select(".post-item-text").first();
Element section_div_a = section_div.select("a[href]").first();
String blogTitle = section_div_a.text();
System.out.println(blogTitle);
}这里要说一下,document.select 本身返回的是 Elements,因为我们可以观察网站结构发现,css 叫 post-item-text 的在一个 section 中只有一个,所以我这里直接用 first 方法获取到第一个即可。下面 section_div.select("a[href]") 也是同理。
然后我们来测试一下。

可以看到,是没有问题的。
3. 获取博客连接
博客连接是存储在 a 标签的 href 属性中,我们可以通过 Element 的 attr 方法进行获取。
String blogUrl = section_div_a.attr("href");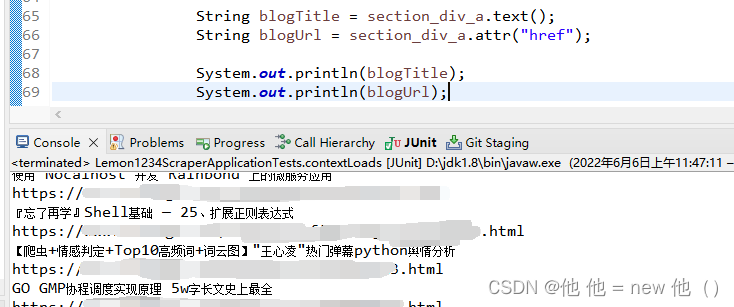
通过测试我们也可以看到,是没有问题的。
4. 获取到所有我们需要的信息
这里我们根据以上的这两种方式,拿到所有我们需要的信息,这里我直接上代码了~
List<DomElement> blogMainDiv = page.getByXPath("//div[@id='post_list']/article/section");
for(DomElement x : blogMainDiv) {
Document document = Jsoup.parse(x.asXml());
Element section_div = document.select(".post-item-text").first();
Element section_div_a = section_div.select("a[href]").first();
String blogTitle = section_div_a.text();
String blogUrl = section_div_a.attr("href");
Element section_div_p = section_div.select("p").first();
String content = section_div_p.text();
Element section_div_p_a = section_div_p.select("a[href]").first();
// cnblog 博客页可能存在没有头像的博客。
String authorUrl = null;
String imageUrl = null;
if(section_div_p_a != null) {
authorUrl = section_div_p_a.attr("href");
Element section_div_p_a_img = section_div_p_a.select("img[src]").first();
imageUrl = section_div_p_a_img.attr("src");
}
Element section_footer = document.select(".post-item-foot").first();
Element section_footer_a_span = section_footer.select("a span").first();
String authorName = section_footer_a_span.text();
Element section_footer_span_span = section_footer.select("span span").first();
String blogCreateDt = section_footer_span_span.text();
}这里同样要有补充说明
- 大家可以多翻几页博客,你会发现一个问题,有的博客是没有用户头像的,也就是说我们获取不到这个,所有才要有判空处理
- 因为页面上没有单独的用户 id,所以我们到时候要通过解析用户的主页地址来获取,所以不要着急。
- 这里其实有一个 bug,如果没有用户头像,我这里其实连用户的 url 也没有获取到,但其实我们可以在下面获取用户名称的时候去拿,但是我懒得写了,你要是为了完美可以自己修改一下~
到这里为止,我们的页面就解析完成了,下一讲我们来说保存数据(保存数据时也有坑~)
这一讲就讲到这里,有问题可以联系我:QQ 2100363119,欢迎大家访问我的个人网站:https://www.lemon1234.com
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











