







目录
对象
对象的类型与编码
当我们在Redis的数据库中新创建一个键值对时,我们至少会创建两个对象,一个对象用作键值对的键,另一个对象用作键值对的值。

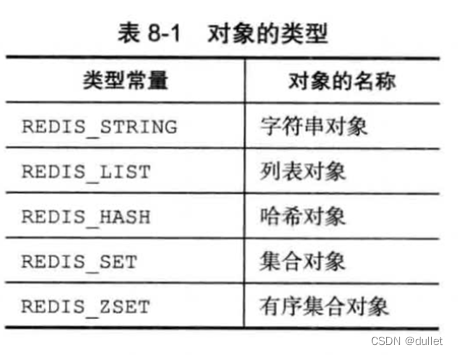
类型
type属性记录了对象的类型
编码和底层实现
对象的ptr指针指向对象的底层实现数据结构
encoding属性记录了对象所使用的编码
字符串对象
字符串对象的编码可以是int、raw、embstr
字符串值大于39字节,编码为raw
字符串值小于等于39字节,编码为embstr
区别:raw编码会调用两次内存分配函数来分别创建redisObject结构和sdshdr结构,而embstr编码则会通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含redisObject和sdshdr两个结构
embstr编码的字符串对象来保存短字符串值有以下好处:
- Embstr编码将创建字符串对象所需的内存分配次数从2次降为1次
- 释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数
- 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里,所以这种编码的字符串对象比起raw编码的字符串对象能够更好的利用缓存带来的优势
Long double类型表示的浮点数在Redis中也是作为字符串值来保存的

编码的转换
当我们对象中保存的不再是整数值,而是一个字符串值,那么字符串对象的编码将从int变为raw
embstr编码的字符串对象实际上是只读的,当我们对embstr编码的字符串对象执行任何修改命令时,程序会先将对象的编码从embstr转为raw,然后再执行修改命令,因此,一个embstr编码的字符串再修改后,就会变成一个raw编码的字符串对象。
列表对象
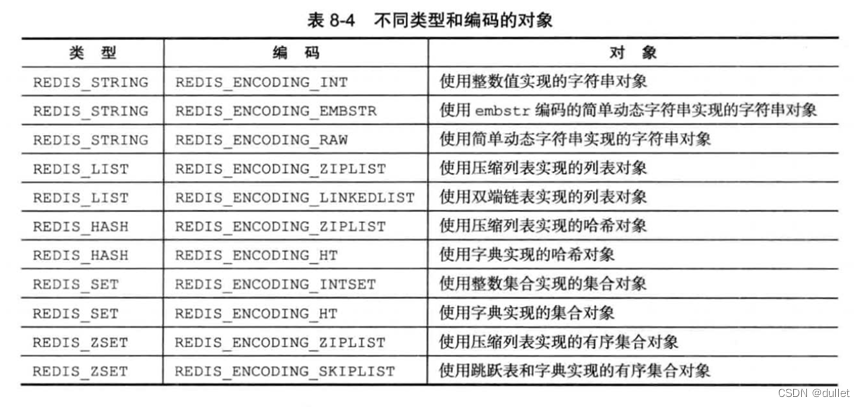
列表对象的编码可以是ziplist或者linkedlist
ziplist
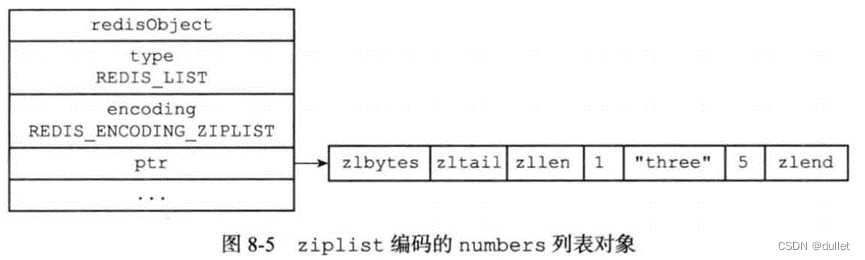
linkedlist

linkedlist编码的列表对象使用双端链表作为底层实现,每个双端链表节点(node)都保存了一个字符串对象,而每个字符串对象都保存了一个列表元素
字符串对象是Redis五种类型的对象中唯一一种会被其它四种对象嵌套的对象
编码转换
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表对象保存的元素数量小于512个
不能满足这个两个条件的列表对象需要使用linkedlist编码
哈希对象
哈希对象的编码可以是ziplist或者hashtable
ziplist
- 保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后添加到哈希对象中的键值对会被放在压缩列表的表尾方向


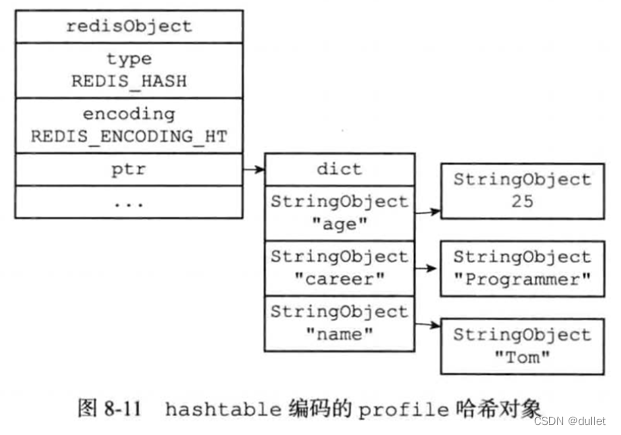
hashtable
hashtable编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值对来保存:
- 字典的每个键都是一个字符串对象,对象中保存了键值对的键
- 字典的每个值都是一个字符串对象,对象中保存了键值对的值
编码转换
当哈希对象同时满足以下两个条件时,哈希对象使用ziplist编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对数量xiaoyu512个
不能满足这两个条件的哈希对象需要使用hashtable编码
集合对象
集合对象的编码可以是intset或者hashtable
Intset
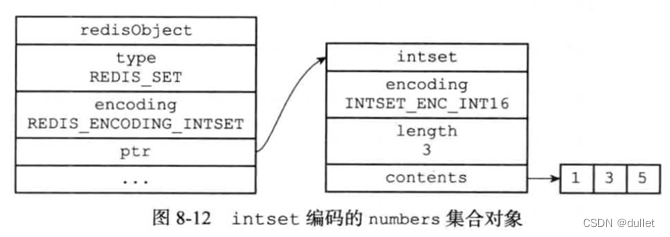
Hashtable
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为NULL
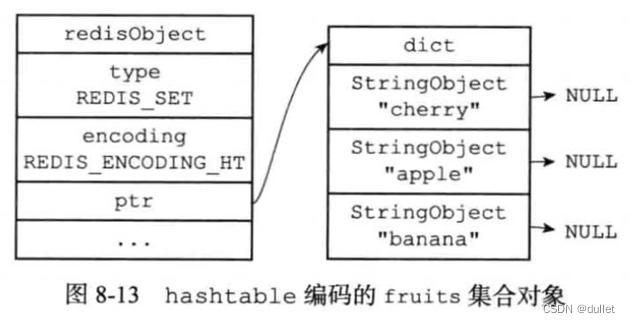
编码转换
当集合对象可以同时满足以下两个条件时,对象使用intset编码:
- 集合对象保存的所有元素都是整数值
- 集合对象保存的元素数量不超过512个
不能满足这两个条件的集合对象需要使用hashtable编码
有序集合对象
有序集合的编码可以是ziplist或者skiplist
Ziplist
Ziplist编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)
压缩列表内的集合元素按分值从小到大进行排序,分支较小的元素被放置在靠近表头的位置,而分值较大的元素被放置在靠近表尾的位置

Skiplist
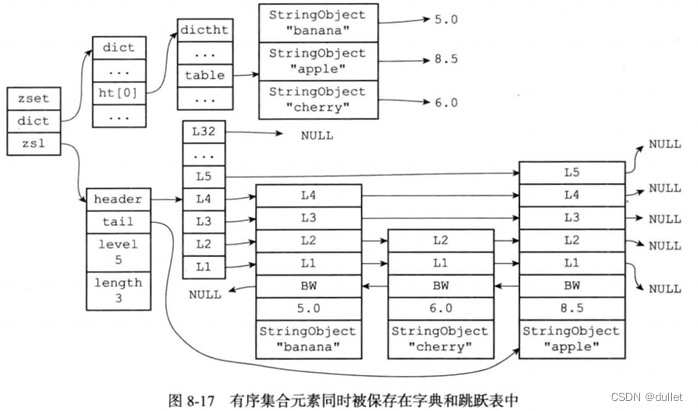
有序集合为什么需要同时使用跳跃表和字典来实现?
同时使用字典和跳跃表的性能会更高。如果只使用字典来实现有序集合,那么虽然以O(1)复杂度查找成员的分值这一特性会被保留,但因为字典以无序的方式来保存集合元素,所以每次在执行范围操作时,程序都需要对字典保存的所有元素进行排序,完成这种排序至少O(NlogN)时间复杂度,以及额外的O(N)内存空间。
另一方面,如果只是用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但没有了字典,所以根据成员查找分值这一操作的复杂度将从O(1)上升为O(logN)。
编码转换
当有序集合对象可以同时满足以下两个条件时,对象使用ziplist编码:
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素成员的长度都小于64字节
不能满足以上两个条件的有序集合对象将使用skiplist编码
类型检查与命令多态
类型检查的实现
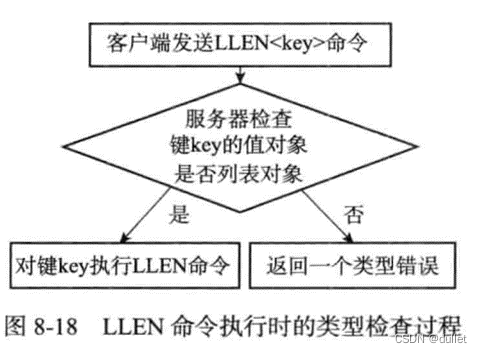
多态命令的实现
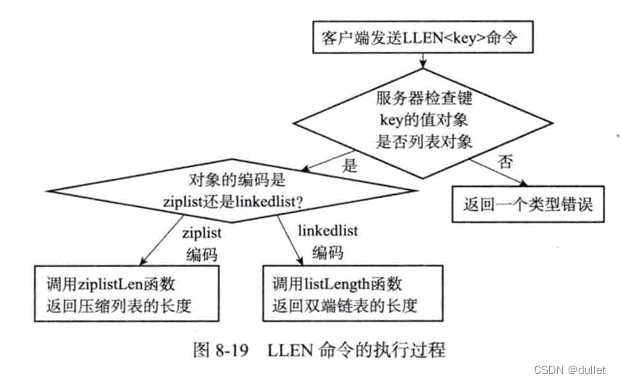
我们可以将DEL、EXPIRE、TYPE等命令也成为多态命令,因为无论输入键是什么类型,这些命令都可以正确运行。
DEL、EXPIRE等命令与LLEN等命令的区别在于,前者是基于类型的多态——一个命令可以同时用于处理多种不同类型的键,而后者是基于编码的多态——一个命令可以同时用于处理多种不同编码。
内存回收
Redis在自己对象系统中构建了一个引用计数技术实现的内存回收机制
- 再创建一个新对象时,引用计数的值会被初始化为1
- 当对象被一个新程序使用时,它的引用计数值会被增一
- 当对象不再被一个程序使用时,它的引用计数值会被减一
- 当对象的引用计数值变为0时,对象所占用的内存会被释放
对象共享
多个键共享同一个值对象需要执行以下两个步骤:
- 将数据库键的值指针指向一个现有的值对象
- 将被共享的值对象的引用计数增一

Redis会在初始化服务器时,创建一万个字符串对象,这些对象包含了从0到9999的所有整数值,当服务器需要用到值为0到9999的字符串对象时,服务器就会使用这些共享对象,而不是新对象。
为什么Redis不共享包含字符串的对象?
字符串对象值相对更加复杂,而一个共享对象保存的值越复杂,验证共享对象和目标对象是否相同所需的复杂度就会越高,消耗的CPU时间也会越多,因此,尽管共享更复杂的对象可以节约更多的内存,但受到CPU时间的限制,Redis只对包含整数值的字符串对象进行共享。
对象的空转时长

lru,该属性记录了对象最后一次被命令程序访问的时间
空转时长=当前时间-lru
注意:
如果服务器打开了maxmemory选项,并且服务器用于回收内存的算法为volatile-lru或者allkeys-lru,那么当服务器占用的内存数超过了maxmemory选项所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存。















 2424
2424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









