







第一章习题答案
选择题
ACAAB
CCDAD
CBABD
CAACA
CDC
填空题
1、(1)树形 (2)图形
2、(1)确定性 (2)输出
3、(1)时间复杂度 (2)空间复杂度
4、 (1)一对一 (2)一对多 (3)多对多
5、物理结构
6、关系
7、存储空间
8、(1)有穷指令 (2) 时间复杂度 (3)时间复杂度
9、O(n2)
10、(1) 顺序(2)链式
判断题
✔✔xxx✔✔
简答题
- 1.数据结构课程研究的主要是“非数值性问题”的解决方案。包括问题所涉及的操作对象(数据)之
间的逻辑关系:在计算机中保存这一逻辑关系的方式即存储结构:以及建立在具体存储结构上的各种操作。- 2.数据是能够被计算机识别、存储和加工处理的信息的载体。
数据元素是数据集合中的一个基本单位。
数据结构是指数据的逻辑结构、存储结构以及建立在相应逻辑结构和存储结构上的算法设计。
数据元素之间的逻辑关系称作逻辑结构。
数据元素及其逻辑关系在计算机内存中的实现称为存储结构。
- (1)集合结构,结构中的数据元素之间除了“同属于一个集合”的关系外,别无其他关系。
(2)线性结构。结构中的数据元素之间存在着“一对一”的关系。
(3)树形结构。结构中的数据元素之间存在着“一对多”的关系。
4)图形结构或网状结构。结构中的数据元素之间存在看“多对多”的关系。
文章目录
前言
线性表(( LinearList ))是线性结构中最常用而又最简单的一种数据结构,几乎所有线性的关系都可以用线性表表示。线性表是线性结构的抽象,线性结构的特点是数据元素之间是一对一的线性关系,数据元素一个接一个的排列。因此,线性表可以想象为一种数据元素的序列。本章主要介绍线性表的逻辑结构和各种存储表示方法,以及定义在存储结构上的各种基本操作的实现。
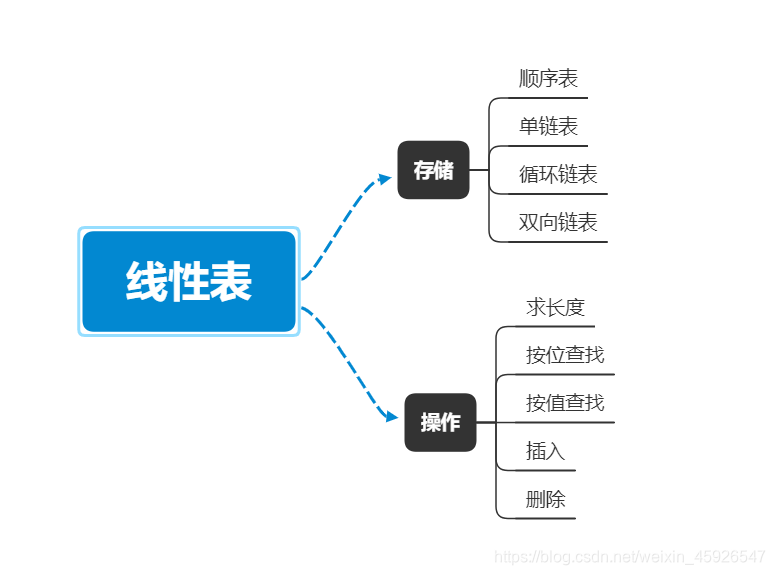
线性表
线性表
基本概念
定义:
- 线性表的定义线性表是具有
相同数据类型的n(n≥0)个数据元素的有限序列n为表长,当n=0时称为空表。- 在线性表中相邻元素之间存在着顺序关系。如对于
元素a而言,a2称为a1的直接前驱,a2称为a1的直接后继。通常将它的数据类型抽象为DataType,因为DataType可以根据具体问题而确定。
特点:
- 有且仅有一个开始结点(a1),它没有
直接前驱;- 有且仅有一个终端结点(an),它没有
直接后继;- 除了开始结点和终端结点以外,其余的结点都有且
仅有一个直接前驱和一个直接后继。
优点:
- 节约存储空间;
- 结构简单,便于访问任何元素。
缺点:
- 插入和删除需要移动大量数据;
- 以上操作程序运行销效率低;
- 表的存储空间预先匹配,会造成空间浪费或空间溢出。
二元组:
表示线性表如果用二元组进行描述如下:
Linearity =(D,R)
- 数据对象:
D={ai|1≤i≤n,n≥0}- 数据关系:
{<ai-l,ai>lai-l,aied,1≤i≤n}关系中<ai-1,ai>是一个序偶的集合,它表示线性表中数据元素的相邻关系,即ai-1领先于ai。
基本操作
- 初始化线性表
条件:表不存在;
结果:建立一个表。- 求长度
条件:线性表存在;
结果:返回长度。- 按位置查找
条件:线性表存在,要查找的位置;
结果:在线性表的第i位查找,若找到返回该元素,若没有返回0。- 按值查找
条件:线性表存在,要查找的值;
结果:在线性表查找该值,若存在则返回第一个查找到的值,若没有返回0。- 插入数值
条件:线性表存在,插入的位置,插入的数值;
结果:查找位置,插入数值,插入后的数值都往后移动。- 根据位置删除数值
条件:线性表存在,删除的位置;
结果:若线性表的长度满足该位置,则删除该数值。- 显示操作
条件:线性表存在,不为空;
结果:依次输出各个元素的值。
存储方式
顺序表
定义
用一组
地址连续单元依次存储线性表的数据元素。
存储特点
- 顺序表的
逻辑顺序和物理顺序一致;- 顺序表中任意一个数据元素都可以
随机存取。
代码案例
代码里面有详细注释,以及著明拉一俩点可能遇到的小问题。🐬
代码可直接赋值运行,各个功能都有在主函数中得到实现。这边就简单实现,所以主函数比较简洁,没有花里胡哨的代码😂。若有其他想法也可以根据下面代码继续完善表的功能。⛽
#include<stdio.h>
#define MAXLEN 100 // 定义最大长度
typedef int DataType;
/**************************定义顺序表**************************/
typedef struct
{
DataType data[MAXLEN]; // 列表存数据
int Length; // 存表的长度
}SeqList;
/**************************初始化顺序表**************************/
void initList(SeqList *L)
{
L->Length = 0; // 将表的长度赋值为0
}
/**************************创建顺序表**************************/
void createList(SeqList *L)
{
int i;
for (i=0; i<10; i++) // 创建表,循环将数值写入表中
L->data[i] = i;
L->Length = i; // 并存下表的长度 ==> 写入的元素多少个
}
/**************************根据位置获取元素**************************/
int getElem(SeqList *L, int i)
{
int temp;
if(i<1 || i>L->Length) // 判断该位置是否超出表的范围
{
return 0;
}
else
{
temp = L->data[i-1]; // 若不超出,则取出该位置的数值
printf("\n查找的值为:%d\n", temp);
return 1;
}
}
/**************************查值获取位置**************************/
int searchValue(SeqList *L, DataType x)
{
int i=0;
while(i < L->Length && L->data[i] != x) // 判断i是否超出表的范围,并且判断是否等于查找的值,若等于则跳出循环
{
i++;
}
if (i > L->Length) // 判断是否超出表的范围
{
return 0;
}
else
{
return i+1; // 返回该元素在表中的位置
}
}
/**************************插入元素**************************/
int insertElem(SeqList *L, int i, DataType x)
{
int j;
if(L->Length >= MAXLEN) // 判断表是否满了
{
printf("顺序表已满!");
return -1;
}
if(i < 1 || i > L->Length) // 判断插入的位置是否错误
{
printf("插入错误");
return 0;
}
if(i == L->Length+1) // 判断插入的位置是否是尾部,是则直接插入
{
L->data[i-1] = x;
L->Length++;
return 1;
}
for(j = L->Length-1; j > i-1; j--) // 若不满足以上条件,则插入将位置,其他元素往后移动一位
{
L->data[j+1] = L->data[j]; // 元素往后移动一位
}
L->data[i-1] = x; // 插入元素
L->Length++; // 插入一个元素,则长度加1
return 1;
}
/**************************删除元素**************************/
int delElem(SeqList *L, int i, DataType *x)
{
int j;
if(L->Length == 0) // 判断表是否为空
{
printf("为空");
return 0;
}
if(i < 1 || i > L->Length) // 判断是否超出表的范围
{
printf("不存在该位置");
return 0;
}
*x = L->data[i-1]; // 将删除元素赋值给x
for (j=i; j < L->Length; j++)
L->data[j-1] = L->data[j]; // 循环将元素往前移动
L->Length--; // 删除一个元素,则长度减1
return 1;
}
/**************************显示表中的元素**************************/
void showList(SeqList *L)
{
int i;
for(i=0; i < L->Length-1; i++)
{
printf("%5d", L->data[i]); // 循环表的长度,分别打印出各个数值
}
}
/**************************主函数**************************/
int main()
{
/*
· 对于指针掌握不熟悉的小伙伴可能会疑惑为什么下面传参【L】的时候前面加一个【&】:
>>> 由于函数中接收的参数是【SeqList *L】是指针类型,所以传入一个地址赋值给指针。
>>> 而【&】是取地址符号,所以传参的时候传入【&L】。
· 为什么有些传入的时候【DataType x】有些是【DataType *x】“
>>> 因为函数参数是【DataType x】,则只需传入数值即可,而带【*】的是要传入地址,
>>> 用来接收数值。
· 【注意】:在删除、插入等操作中,需要注意前提以及其他条件。如:不能超出表的范围,
表不能为空表等...
*/
/****定义****/
int flag, addr;
DataType x;
SeqList L;
/****功能实现****/
initList(&L); // 初始化
createList(&L); // 创建表
showList(&L); // 显示表
flag = getElem(&L, 5); // 根据位置获取元素
addr = searchValue(&L, 4); // 根据值获取元素位置
printf("查找的位置:%d", addr);
insertElem(&L, 2, 5); // 插入元素
printf("\n插入后:");
showList(&L); // 显示表
delElem(&L, 2, &x); // 删除元素
printf("\n删除后:\n");
showList(&L); // 显示表
return 0;
}
单链表
基本概念
概念:
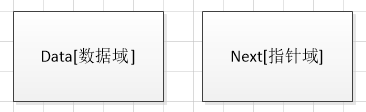
指用一组任意的
存储单元,存储线性表中的数据元素。但出于元素之间的逻辑关系,每个元素不仅需要表示它的具体内容,还要加一个表示它的直接后继元素存储位置的信息。
数据域:存储一个数据元素;指针域:存储直接后继的存储地址。
类型
带头结点:
- 带
头节点的链表中每个结点的存储地址都放在其前驱结点中,这样算法阔以对所有结点处理可一致化。- 头结点的数据域可
不存储信息,也可存储特殊信息。头结点的指针域存储链表中第一结点的地址。- 当头结点的指针域为空(
NULL),则为空链表。若不为空,当某结点的指针域为空,则它为链表的最后一个结点。

不带头结点:
基本操作
- 初始化
条件:向内存申请空间,将该结点赋NULL;
结果:返回头指针。- 头插法建立表
条件:由于单链表中的存储时根据需求而生成的,因此每添加一个数据元素,就申请一个内存空间;将新结点的指针域存放头结点的指针域;
结果:生成的链表是倒序的。- 尾插法建立表
条件:需要增加一个尾指针。每读入一个有效数据,就申请一个空间将数据存入。在将其尾指针设置为空,在将新结点插入;
结果:返回一个按顺序插入的表。- 求长度
条件:由于元素个数未知,需设变量来遍历读取个数。读取每一个元素,直至该数据域不为空;
结果:返回单链表的长度- 按值查找位置
条件:传入查找的数值。一次取出链表中的值进行比较;
结果:返回该值的位置。- 按序号查找值
条件:传入i的位置。判断结点是否是i,循环对i进行匹配;
结果:返回该位置的值。- 插入操作
条件:需要获取插入结点,将该结点指向新的结点,在让新的结点指向下一个结点;
结果:返回插入后的单链表。- 删除操作
条件:输入要删除的位置;将该结点的前一个结点指向该节点后面的结点即可;
结果:返回删除后的单链表。- 输出表
条件:传入头结点;
结果:展示表中的所有元素。
补充:
- 链表在插入和删除操作中的时间复杂度都为
O(n)。- 在删除、插入结点时,需要知道其
前驱结点。- 单链表只能从头指针开始
一个个顺序进行。- 存储密度:结点数据本身所占的存
储单元数和整个结点所占的存储单元数的比。
存储密度越大,存储空间利用率就越高。【顺序表 < 链表 < 双向链表】
循环链表
概念
其实
循环链表是单链表的另一种形式。对于单链表,它的最后一个结点的指针域为空。而循环链表的最后结点的指针域指向头结点,从而构成循环链表。

与单链表的区别
前面讲到判断单链表的最后一个结点是否为空时,是看后继结点
是否等于NULL。而循环链表看的是头结点是否为空。
循环链表上的操作
循环链表上的任意一个结点出发,其他的结点都阔以找到, 可将表中任意一个结点作为
直接前驱。
双向链表
概念
简单来说,在单链表的基础上在增加一个
前驱指针域。
当头结点的后继指针域为空,则为空表。若某个结点的后继指针位为空,则为最后一个结点。

操作运算
其中,插入和删除的操作与单链表不相同。
插入操作
- 将结点s的prior域指向结点p的前一个结点;
- 将结点p的前一个结点的next域指向结点s;
- 将结点s的next域指向p结点;
- 将结点p的prior域指向结点s。
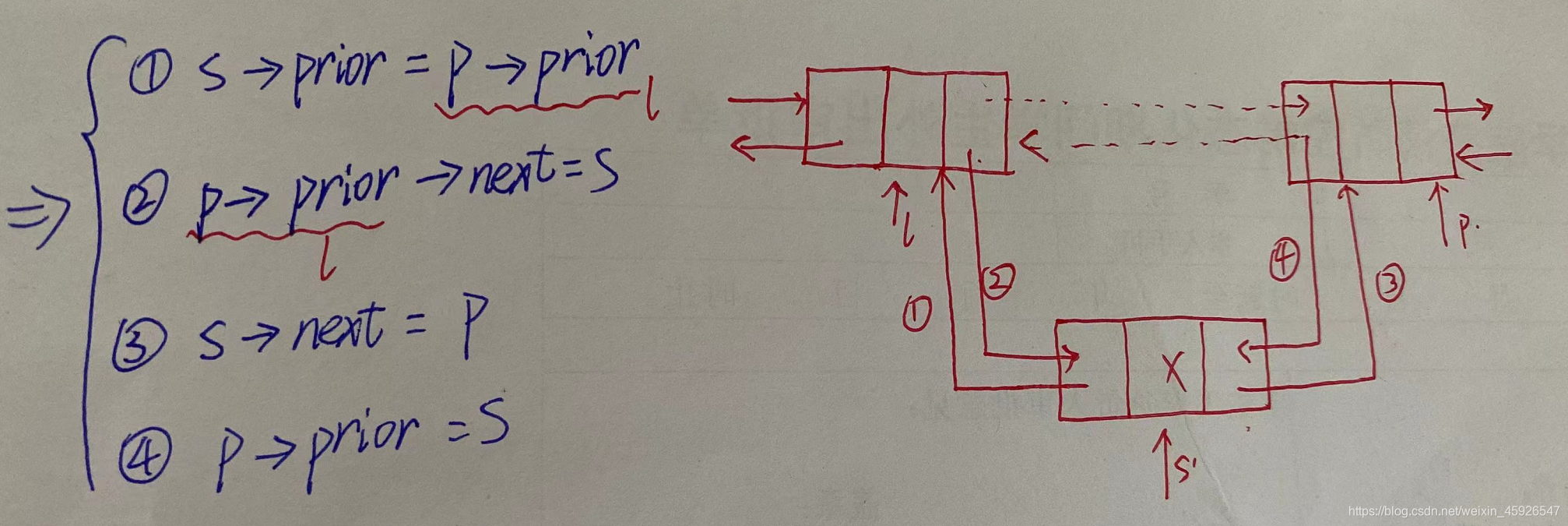
#include<stdio.h>
void DInsertElem(DLinkLinst *p, DataType x)
{
DLinkList *s;
s = (DLinkList *)malloc(sizeof(DLinkList));
s->data = x;
s->prior = p->prior;
p->prior->next = s;
s->next = p;
p->prior = s;
}
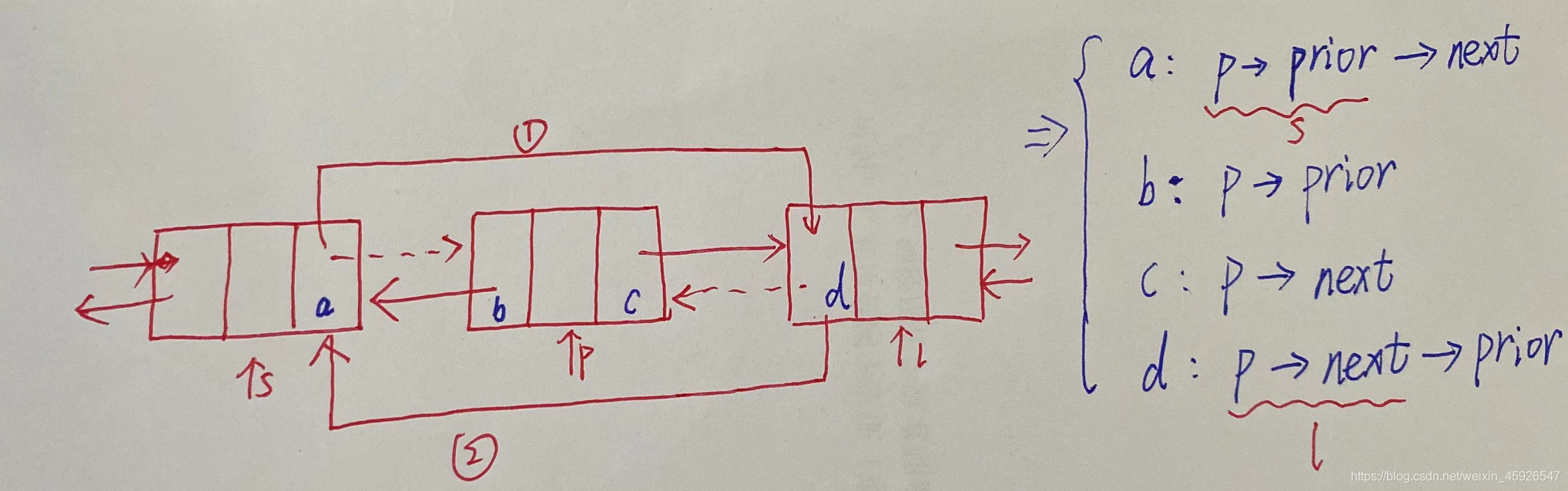
删除操作
- 将结点p前一个结点next域指向结点p的next域
- 将结点p后一个结点的prior域指向结点p的prior域
- 释放结点p
void DDeletElem()
{
*x = p->data;
p->prior->next = p->next;
p->next->prior = p->prior;
free(p);
}
顺序表与链表的对比
| 顺序表 | 单链表 | |
|---|---|---|
| 优点 | 简单易实现 | 较复杂 |
| 无需额外增加存储 | 需要时,在指定分配空间 | |
| 随机访问,随机存储 | 访问元素繁琐 | |
| 缺点 | 插入、删除效率低 | 需知前驱结点 |
| 空间预先匹配,造成浪费 | 需要时,在指定分配空间 | |
| 相对于空间 | 知大小 ✔ | 大小难确定 ✔ |
| 相对于时间 | 存取操作多 ✔ | 插入删除多 ✔ |
代码案例
/*
@Author : Jaibuti
@Software: CodeBlocks
@title: 单链表
*/
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef int DataType;
/**************************创建链表结构体**************************/
typedef struct linknode
{
DataType data; // 数据域
struct linknode *next; // 指针域
}LinkList;
/****************************************************
* 功能:链表初始化
* 思路:
` 申请空间;
` 指向下一个数据为空。
* 参数:无
* 返回值:返回单链表
****************************************************/
LinkList *InitList()
{
LinkList *head;
head = (LinkList *)malloc(sizeof(LinkList));
head->next = NULL;
return head;
}
/****************************************************
* 功能:头插法
* 思路:
` 申请空间;
` 每一个结点都插入头部。
* 参数:
` 链表;
` 输入的整数个数。
* 返回值:返回单链表
****************************************************/
void CreateListH(LinkList *head, int n)
{
LinkList *s;
int i;
printf("请输入%d个整数:\n", n);
for(i=0; i<n; i++)
{
s = (LinkList *)malloc(sizeof(LinkList));
scanf("%d", s->data);
s->next = head->next;
head->next = s;
}
printf("链表建立成功...");
}
/****************************************************
* 功能:尾插法
* 思路:
` 申请空间
` 每一个结点都插入头部
* 参数:
` 链表;
` 输入的整数个数。
* 返回值:返回单链表
****************************************************/
void CreateListL(LinkList *head, int n)
{
LinkList *s, *last;
int i;
last = head;
printf("请输入%d个整数:\n", n);
for(i=0; i<n ;i++)
{
s = (LinkList *)malloc(sizeof(LinkList));
scanf("%d", &s->data);
s->next = NULL;
last->next = s;
last = s;
}
printf("\n链表操作成功...\n");
}
/****************************************************
* 功能:插入结点
* 思路:
* 参数:
` 链表;
` 输入的整数个数;
` 模式选择:0-头插入;其他-尾插法。
* 返回值:返回单链表
****************************************************/
void CreateList(LinkList *head, int n, int mode)
{
if (mode == 0)
{
CreateListH(head, n);
}
else
{
CreateListL(head, n);
}
}
/****************************************************
* 功能:获取链表的长度
* 思路:
` 根据当前结点指向的下一个是否为空
` 若为空则是最后一个。
* 参数:
` 链表;
* 返回值:链表长度
****************************************************/
int GetListLength(LinkList *head)
{
LinkList *p = head->next;
int j=0;
while(p!=NULL)
{
p = p->next;
j++;
}
return j;
}
/****************************************************
* 功能:获取元素位置
* 思路:
` 根据当前结点的数据域是否等于该元素
* 参数:
` 链表;
` 要查找的元素。
* 返回值:无
****************************************************/
void GetLocate(LinkList *head, DataType x)
{
int j=1;
LinkList *p;
p = head->next;
while(p!=NULL && p->data!=x)
{
p=p->next;
j++;
}
if(p != NULL)
{
printf("\n在表的第%d位找到值为%d的结点...\n", j, x);
}
else
{
printf("未找到该值\n");
}
}
/****************************************************
* 功能:根据位置查找元素
* 思路:
` 根据当前结点是否为该位置
* 参数:
` 链表;
` 查找的位置。
* 返回值:无
****************************************************/
void SearchList(LinkList *head, int i)
{
LinkList *p;
int j=0;
p = head;
if(i > GetListLength(head))
{
printf("该位置已超出链表范围\n");
}
while(p->next != NULL && j<i)
{
p = p->next;
j++;
}
if(j==i)
{
printf("\n在第%d为上的元素值为%d...\n", i, p->data);
}
}
/****************************************************
* 功能:根据元素位置插入元素
* 思路:
` 根据当前结点是否为该位置
* 参数:
` 链表;
` 查找的位置;
` 插入的元素。
* 返回值:无
****************************************************/
void InsertList(LinkList *head, int i, DataType x)
{
int j=0;
LinkList *p, *s;
p = head;
while(p->next != NULL && j<i-1)
{
p=p->next;
j++;
}
if(p != NULL)
{
s = (LinkList *)malloc(sizeof(LinkList));
s->data = x;
s->next = p->next;
p->next = s;
printf("\n元素插入成功...\n");
}
else
{
printf("\n元素插入失败\n");
}
}
/****************************************************
* 功能:删除元素
* 思路:
` 根据当前结点是否为该位置
* 参数:
` 链表;
` 删除的位置。
* 返回值:无
****************************************************/
void DeletList(LinkList *head, int i)
{
int j=0;
DataType x;
LinkList *p = head, *s;
while(p->next != NULL && j<i-1)
{
p = p->next;
j++;
}
if(p->next != NULL && j==i-1)
{
s = p->next;
x = s->data;
p->next = s->next;
free(s);
printf("\n成功删除第%d位上的元素%d...\n", i, x);
}
else
{
printf("\n删除结点位置错误...\n");
}
}
/****************************************************
* 功能:显示链表的所有元素
* 思路:
` 根据当前结点是否为空
* 参数:
` 链表;
* 返回值:无
****************************************************/
void DisplayList(LinkList *head)
{
LinkList *p;
p = head->next;
while (p != NULL)
{
printf("%5d", p->data);
p = p->next;
}
}
int main()
{
LinkList *h; // 创建链表
h = InitList(); // 初始化链表
CreateList(h, 4, 1); // 创建链表
DisplayList(h); // 显示链表
int len = GetListLength(h); // 获取链表
printf("\n长度:%d\n", len);
GetLocate(h, 1); // 获取位置
SearchList(h,1); // 查找值
InsertList(h, 2, 2); // 插入元素
DisplayList(h); // 显示链表
DeletList(h, 2); // 删除元素
DisplayList(h); // 显示链表
return 0;
}
本章小结
- 线性表是最简单的数据结构,元素一对一,存储方式【顺序、链式】;
- 顺序表优点:随机存取、节约空间;
- 顺序表缺点:扩充困难、插入、删除耗时长,复杂;
- 链式:通过结点连接,【单链、双链、循环链】;
- 单链表优点:易扩充、插入、删除;
- 单链表缺点:存储空间浪费;
- 双链表:既能找到前结点又能找到后结点;
- 循环链表最后一个结点的指针指向头结点的地址。
本章练习
一、选择题
1、下面关于线性表的叙述中,错误的()
A、线性表采用顺序存储,必须占用一片连续的存储单元。
B、线性表采用顺序存储,便干讲行插入和删除操作。
C、线性表采用链接存储,不必占用一片连续的存储单元。
D、线性表采用链接存储,便干插入和删除操作。
2、在有n个结点的顺序表上做插入、删除结点运算的时间复杂度为()
A、O(1)
B、O(n)
C、O(n2)
D、O(1og2n)
3、两个指针P和Q,分别指向单链表的两个元素,P所指兀系定Q所指兀索前驱的条件是()
A、P->next==Q->next
B、P->next==Q
C、Q->next==P
D、 P==Q
4、在单链表中,增加头结点的目的是()。
A、使单链表至少有一个结点
B、标志表中首结点的位置
D、方便运算的实现
C、说明该单链表时线性表的链式存储结构
5、在顺序表中,只要知道(),就可以求出任意一个结点的存储地址。
A、基地址
B、结点大小
C、向量大小
D、基地址和结点大小
6、链表不具备的特点是()
A、随机访问
B、不必事先估计存储空间
C、插入删除时不需移动元素
D、所需空间与线性表成正比
7.在()运算时,使用顺序表比链表好
A、插入
B、根据序号查找
C、删除
D、根据元素查找
8、在单链表指针为p的结点之后插入指针为s的结点,正确的操作是()
A、p->next=s;s->next=p->next;
B、s->next=p->next;p->next=s;
C、p->next=s;p->next=s->next;
D、p->next=s->next;p->next=s;
9、用链表表示线性表的优点是().
A,便于进行插入和删除操作
B,便于随机存取
C.占用的存储空间较顺序表少
D.元素的物理顺序与与逻辑顺序一致
10、在一个长度为n的顺序表中,若要删除第i(1≤i≤n)个元素,则需向前移动()一个元素。
A. n-i+1
B. n-i-1
C. n-i
D.i
11、在一个长度为n的顺序表中,若要在第i(1≤i≤n)个元素前插入一个元素时,则需向后移动()个元素。
A.n-i+1
B. n-i-1
C.n-i
D.i
12、设p为指向单循环链表上某结点的指针,则的直接前驱()
A、找不到
B.查找时间复杂度为O(1)
C、查找时间复杂度为 O(n)
D、查找结点的次数约为n
13、等概率情况下,在有n个结点的顺序表上做插入结点运算,需平均移动结点的数目为()
A、n
B、(n-1)/2
C、n/2
D、(n+1)/2
14、以下链表结构中,从当前结点出发能够访问到任意结点的是()
A、单向链表和双向链表
B、循环链表和单向链表
C、循环链表和双向链表
D、单向链表、双向链表和循环链表
15.对具有n个结点的线性表进行插入或删除操作,所需的算法时间复杂度为()。
A.O(n2)
B.O(nlog2n)
C. O(log^2n)
D.O(n)
二、填空题
- 1、线性表 L=(a1…,an)采用顺序存储,假定删除表中任意元素的概率相同,则删除一个元素平均需要移动元素的个数是____;
- 2、顺序表相对于链表的优点是:____和随机存取;链表相对于顺序表的优点;
- 3、在单链表中要在已知结点P之前插入一个新结点,需找到P的直接前趋结点的地址,其查找的时间复杂度为_____;
- 4、在长度为n的顺序表中,如果要在第i个元素前插入一个元素,要后移_____个元素‘
- 5、链表相对于顺序表的优点是插入心制除方便;缺点是存储密度____;
- 6、链式存储的特点是利用_____来数据元素之间的逻辑关系;
- 7、在双向链表中,每个结点有俩个指针域,一个指向____结点,另一个指向其____结点;
- 8、在一个双链表中,设指针p是指向该表中待删除的结点,则需要执行的操作为:____;
- 9、若对一个线性表经常进行查找操作,而很少进行插入和删除操作时,则采用____存储结构为宜。相反,若经常进行的是插入和删除操作时,则采用___存储结构为宜。
三、判断题
- 1、线性表的链式存储结构优于顺序存储结构();
- 2、链表的每个结点都恰好包含一个指针域();
- 3、在线性表的链式存储结构中,逻辑上相邻的两个元素在物理位置上并不一定紧邻();
- 4、顺序存储方式的优点是存储密度大,插入、删除效率高();
- 5、线性链表的删除算法简单,因为当删除链中某个结点后,计算机会自动地将后续的各个单元向前移动();
- 6、顺序表的每个结点只能是一个简单类型,而链表的每个结点可以是一个复杂类型();
- 7、线性表链式存储的特点是可以用一组任意的存储单元存储表中的数据元素();
- 8、线性表采用顺序存储,必须占用一片连续的存储单元();
- 9、顺序表结构适宜于进行顺序存取,而链表适宜于进行随机存取();
- 10、插入和删除操作是数据结构中最基本的两种操作,所以这两种操作在数组中也经常使用();
四、应用题
1、若有100个学生,每个学生有学号、姓名、平均成绩,存储这些数据应采用什么样的存储结构最方便?写出这些结构类型定义。
2、设计一个算法,删除顺序表中值为x的所有结点。
3、设计一个算法,将带头的单链表逆置。
4、有一个单链表,其头指针为head,编写一个函数计算域为 x的结点个数(不同结点元素值可能相同)。
5、用链表结构存储多项式,求两个多项式A加B的和。要求在建立多项式链表时,总是按照指数大到小顺序排列的。
约瑟夫环问题
若小伙伴们有时间的话,可以练习一下这道题目
问题描述
约瑟夫环问题的种描述是: 编号为1,2,…….n的n个人按顺时针方向围坐一圈,每人持有一个密码(正整数)。一-开始任选个正整数作为报数上限m, 从第一个人开始按顺时针方向自1开始顺序报数,报到n时停止报数。报m的人出列,将它的密码作为新的m值,从它的顺时针万向的下一个人开始重新从1报数,如此下去,直至全部人出列为止。最后按照出列的顺序输出各人的编号。
数据结构
typedef sturct Node
{
int data;
int password;
struct Node *next;
}LinkList;
主要函数
- 构建单链表
- 初始化单链表
- 确定人数
- 给每个人赋值
- 确定上限
- 得出队顺序
- 输出结果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











