







1、如果我们要在一个字符串里找出数字,该怎么做呢?
第一种方法,我们采用es6的filter方法来过滤
let str = "2020woyaofadacai1121"
let nums = [...str].filter(i => !Number.isNaN(parseInt(i))).join("")
第二种方法,我们用正则表达式
let str = "2020woyaofadacai1121"
let nums = str.match(/\d/g).join("")
二者一比较、孰优孰劣一目了然。
2、字面量创建正则表达式
let str = "woaizhongguo"
console.log(/u/.test(str))
3、使用对象创建正则表达式
*使用对象创建的好处是可以传入变量
let str = "woaizhongguo";
let rule = "wo"
let reg = new RegExp(rule, 'g')
console.log(reg.test(str))//true
下面我们做了一个小demo,将用户输入的字符作为正则表达式的匹配规则,如果匹配成功,用户输入的字符串则高亮显示。如图,关键代码展示:
<script>
let str = prompt("请输入要检测内容")
let reg = new RegExp(str, "g")
let div = document.querySelector(".content")
div.innerHTML = div.innerHTML.replace(reg, search => {
return `<span style="color:red">${search}</span>`
})
</script>
4、选择符的使用
|:或
let str = "woaizhongguo"
console.log(/aaa|@/.test(str))//false
let tel="010-9999999"
console.log(/(010|020)\-\d{7,8}/.test(tel))//true
5、原子表和原子组中的选择符
[ ]:原子表 匹配他其中的某一个,匹配到就返回,没有就返回null
let reg = /[123456]/
let str = "3"
console.log(str.match(reg))//3

():原子组 可以把他想象成是匹配一个整体
let reg = /(010|020)/
let str = "01082020"
console.log(str.match(reg))//010

6、转义字符
此时,我们给price写个正则表达式
错误示范:
let price = 23.34
console.log(/\d+.\d+/.test(price))//true 如果不输入小数点也是为true
为什么错误呢?首先我们需要知道“.”有两层含义,一是除换行外任何字符(优先级最高),二是普通字符
此时,我想你应该明白为什么出错了,其实就是我们的正则表达式按照优先级更高的那一层含义来执行了,所以我们需要将它所表达的含义进行转义
*如何转义? 在字符前加 “ \ ” 即可,如下图所示
let price = 23.34
console.log(/\d+\.\d+/.test(price)) //true
这里还需要注意,如果是用对象创建的正则表达式,则需要如下图一样
let reg = new RegExp("\\d+\\.\\d+")
为什么需要这样呢?
console.log("\d")// d

通过上图的输出,我们可以看出\d 输出的还是 d,而我们正则表达式想要接收的是 \d,所以需要对它再进行一次转义
关于转义,再来看一个例子吧
*下面url中的 // 和 . 被转义了
let url = "https://www.baidu.com"
let result = /https?:\/\/\w+\.\w+\.\w+/
console.log(result.test(url))//true
7、字符边界约束
* ^ :以……开始 $:以……结束
下面我们来匹配,以数字开始并以数字结束的一个或多个数字,如下图所示:
let str = "24123213"
let result = /^\d+$/
console.log(result.test(str))//true
下面是一个小demo,输入3至6位字母,验证正确或失败,关键代码,如图所示:
<script>
document
.querySelector("[name='user']")
.addEventListener("keyup", function () {
let flag = this.value.match(/^[a-z]{3,6}$/)
document.querySelector("span").innerHTML = flag ? "正确" : "失败"
})
</script>
8、数值与空白元字符
\d:匹配数字 \D:除了数字
let str = "woaizhongguo 2020";
let result = /\d/g
let result_=/\d+/g
console.log(str.match(result))//["2", "0", "2", "0"]
console.log(str.match(result_))//["2020"]
let str = "张三:010-99999999,李四:020-77777777";
let result = str.match(/\d{3}-\d{7,8}/g)
console.log(result)//["010-99999999", "020-77777777"]
let str="woaizhongguo 2020"
console.log(str.match(/\D+/))//woaizhongguo
\s:匹配空白 \S:匹配除了空白
\n:换行符
console.log(/\s/.test("\nhd"))//true
如下图在有换行符,空格的情况下匹配中文
*在原子表中加上^符号,表示除了原子表了的内容都要
let str = `
张三:010-99999999,李四:020-77777777
`;
let result = str.match(/[^-\d:,\s]+/g)
console.log(result)//["张三", "李四"]
9、w与W元字符
\w:字母、数字、下划线 \W:除了字母、数字、下划线
let str = "woaizhongguo2010@@"
let result = str.match(/\w+/g)
console.log(result)//["woaizhongguo2010"]
*邮箱验证我们可以这样做:
let str = "1095518902@qq.com"
let result = /^\w+@\w+\.\w+$/.test(str)
console.log(result)//true
题目:以字母开头的5-10位数字、字母或者下划线
let str = "woaizhongguo"
let result = /^[a-z]\w{4,9}$/.test(str)
console.log(result) //false
10、点元字符的使用
. :除了换行符之外的所有字符
let str = "woaizhongguo#$%*()_-!"
let result = str.match(/.+/)
console.log(result)//woaizhongguo#$%*()_-!
let str = `
woaizhongguo
sichuan
`
let result = str.match(/.+/)
console.log(result)//woaizhongguo
如上图,就体现出了点元字符不能匹配换行符,所以如果我们要想要匹配后面的内容,可以这样做:
let str = `
woaizhongguo
sichuan
`
let result = str.match(/.+/s)
console.log(result)
*注意:这里的s是写在最后的,它代表的是一种模式,即单行匹配模式,可以理解为它会忽略换行符

再说一点,如果我们要匹配空格,可以像下图所示,可以直接输入空格,也可以输入\s,它和我们普通字符一样,只是看不见而已
let tel = "010 - 99999999"
let result = tel.match(/\d+ - \d{8}/)
console.log(result)//010 - 99999999
或
let result = tel.match(/\d+\s-\s\d{8}/)
11、精巧的匹配所有字符
let str = `
<span>
woaizhongguo
sichuan
</span>
`
let result=str.match(/<span>[\s\S]+<\/span>/)
console.log(result)

小结:其实要匹配所有字符主要是运用了原子表和元字符大小写之间互补的功能,上图例子中使用[\s\S]来表示了所有字符,其实也可以,[\d\D]、[\w\W]等等
12、i 与 g 模式修正符
i:不区分大小写 g:全局匹配
let str="WoAiZhongGuo"
let result=str.match(/woaizhongguo/)
console.log(result)//null
let str="WoAiZhongGuo"
let result=str.match(/woaizhongguo/i)
console.log(result)//WoAiZhongGuo
如上所示,就是 i 修正符的作用以及运用,下面我们来看看 g 是如何运用的吧
let str = "woaizhongguoqingdao"
let result = str.match(/o/)
console.log(result)//o
let str = "woaizhongguoqingdao"
let result = str.match(/o/g)
console.log(result)//["o", "o", "o", "o"]
从上面的例子,不难看出使用了 g 修正符的正则表达式匹配除了字符串中的所有 o ,而没有使用 g 修正符的则只匹配了一个
13、m 多行匹配符实例
问题:将下图字符串str,转换成key:value的格式,例如 {title,price:200元}
+:1个或多个 *:0个或多个
m(修正符):每一行单独处理
let str = `
#1 js,200元 #
#2 php,300元 #
#9 java,120元 # 未上架
#3 node.js,180元 #
`;
let result = str.match(/^\s*#\d+\s+.+\s+#$/gm)
console.log(result)

上图,我们通过m修正符的运用将字符串中需要的数据进行了提取,下面我们对其进行处理
let str = `
#1 js,200元 #
#2 php,300元 #
#9 java,120元 # 未上架
#3 node.js,180元 #
`;
let result = str.match(/^\s*#\d+\s+.+\s+#$/gm)
result = result.map(item => {
item = item.replace(/\s*#\d+\s*/, "").replace(/\s*#/, "");
[title, price] = item.split(",")
return {
title,
price
}
})
console.log(result)

14、汉字与字符属性
*注意:我们需要知道任何字符都有相应的属性进行区分
L:表示是字母 P:表示标点符号 需结合u模式才有效
*其他属性简写属性的别名
匹配字母
let str = "hello2020!"
let result=str.match(/\p{L}/gu)
console.log(result)// ["h", "e", "l", "l", "o"]
匹配标点符号
let str = "hello2020!"
let result=str.match(/\p{P}/gu)
console.log(result)//["!"]
匹配中文
let str = "我爱你china2020!"
let result=str.match(/\p{sc=Han}/gu)
console.log(result)
字符也有unicode文字系统属性 Script=文字系统,使用 \p{sc=Han} 获取中文字符 han为中文系统,其他语言请查看文字语言表
在匹配宽字节的时候需要加上u模式
let str = "𝒳𝒴";
let result=str.match(/[𝒳𝒴]/g)
console.log(result)

let str = "𝒳𝒴";
let result = str.match(/[𝒳𝒴]/gu)
console.log(result)

15、lastindex属性的作用
*正则表达式匹配出来的结果通常会有很多属性
let str = "helloworld";
let result = str.match(/\w/)
console.log(result)

如果加上g模式,就会丢失这些属性
let str = "helloworld";
let result = str.match(/\w/g)
console.log(result)

如果想要保留这些属性,可以这样做,使用exec方法
let str = "helloworld";
let reg = /h/g
let result = reg.exec(str)
console.log(result)
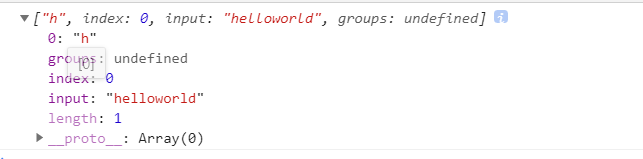
*正则表达式有一个lastIndex属性,它会记录上一次搜索的点,仅在全局模式生效
let str = "helloworld";
let reg = /\w/g
console.log(reg.lastIndex)
console.log(reg.exec(str))
console.log(reg.lastIndex)
console.log(reg.exec(str))

16、有效率的y模式
y模式与g模式差不多,区别在于,y模式需要连续的,没有就不找了,而g模式可以跳过继续找,直到字符串结束
例如下图前两个字符都是h所以打印出来了,即时后面还有h,但是第三个字符不是,就没有连续,所以打印出null
let str = "hhllhhhhoworld";
let reg = /h/y
console.log(reg.exec(str))
console.log(reg.lastIndex)
console.log(reg.exec(str))
console.log(reg.lastIndex)
console.log(reg.exec(str))
console.log(reg.lastIndex)

来看下面这个demo:
let str = "我爱你中国1111,222222,333啦啦啦啦";
let reg = /(\d+),?/y;
let arr = [];
reg.lastIndex = 5
while ((res = reg.exec(str))) arr.push(res[1])
console.log(arr)

17、原子表的使用
*这里的\1 代表的是取前面原子组匹配的结果
let str = "2020-11-28";
let reg = /^\d{4}([-\/])\d{2}\1\d{2}$/;
console.log(str.match(reg))

18、区间匹配
如下代码中的 [a-z] 代表的是a到z之中的一个字符,它是一个范围。
let ipt = document.querySelector(`[name="username"]`)
ipt.addEventListener("keyup", function () {
this.value.match(/^[a-z]\w{3,6}$/)
})
19、排除匹配
*在原子表中使用 ^ 符号,就会排除原子表里的内容进行匹配
let str="张三:010-99999,李四:020-888888"
console.log(str.match(/[^\d:\-,]+/g))

20、原子表字符不解析
*注意:在原子表中特殊字符不会被正确解析,它还是代表本意,不会有正则表达式当中的特殊含义
let str = "(helloworld).+"
let result = str.match(/[.+]/gi)
console.log(result)

21、邮箱验证中原子组的使用
let a = "1099@qq.com";
let ipt = document.querySelector("[name=txt]");
ipt.addEventListener("keyup", function () {
var result = this.value.match(/^[\w-]+@([\w]+\.)+(com|cn|org)$/i)
console.log(result)
})
22、原子组引用完成替换操作
let str = `
<h1>我</h1>
<h3>爱</h3>
<h4>你</h4>
`
let reg = /<(h[1-6])>([\s\S]+)<\/\1>/ig
//第一种方法,利用$
// console.log(str.replace(reg, ` <div>$2</div>`))
//p0代表正则匹配的完整字符串
let result = str.replace(reg, (p0, p1, p2) => `<p>${p2}</p>`)
console.log(result)
23、嵌套分组但不记录分组
使用?:可使该原子组不被记录
let str=`
https://www.baidu.com
`;
let reg=/https:\/\/(\w+\.\w+\.(?:com|org))/
console.log(str.match(reg))

24、批量使用正则完成验证
可将多个正则表达式放入数组中来进行批量验证
let ipt = document.querySelector('[name=username]')
let regs = [/^[a-z0-9]{5,10}$/i, /[A-Z]/, /\d/]
ipt.addEventListener("keyup", function () {
let state = regs.every(e => e.test(this.value))
console.log(state
? "正确"
: "错误")
})
25、禁止贪婪
我们都知道+代表1个或多个,如果在+
后面加上?则表示会更倾向于匹配少的一方,也就是1个
let str = "hello"
let result = str.match(/h+?/)
console.log(result)

更多写法
let result = str.match(/h*?/)
let result = str.match(/h{2,100}?/)
let result = str.match(/h{2,}?/)//{2,}代表2个或无限个
*注意:?本身代表0个或1个,再加上?则代表0个
let result = str.match(/h??/)
26、标签替换的禁止贪婪使用
<main>
<span>www.baidu.com</span>
<span>www.soho.com</span>
<span>www.sina.com</span>
</main>
<script>
const main = document.querySelector('main');
//在这里如果不加?对其进行禁止贪婪,+则可以匹配所有的内容
const reg = /<span>([\s\S]+?)<\/span>/gi;
main.innerHTML = main.innerHTML.replace(reg, (v, p1) => {
return `<h4>${p1}</h4>`
})
</script>
27、使用matchAll完成全局匹配
如下代码,我们如果想要取出span标签内的内容,则可以使用matchAll
<main>
<span>www.baidu.com</span>
<span>www.soho.com</span>
<span>www.sina.com</span>
</main>
<script>
const main = document.querySelector('main');
const reg = /<span>([\s\S]+?)<\/span>/gi;
const obj = main.innerHTML.matchAll(reg)
for (const key of obj) {
console.dir(key)
}
</script>

28、为低端浏览器定义原型方法matchAll
String.prototype.matchAll = function (reg) {
let res = this.match(reg);
if (res) {
let result = this.replace(res[0], "*".repeat(res[0].length));
let match = result.matchAll(reg) || []
return [res, ...match]
}
}
let str = "helloworld";
console.log(str.matchAll(/o/i))
29、字符串split方法
let str = "2020-12/13"
let result = str.split(/[-\/]/)
console.log(result)

30、$符在正则替换中的使用
let str = "(010)99999999 (020)88888888";
let reg = /\((\d{3,4})\)(\d{7,8})/g
console.log(str.replace(reg, '$1-$2'))

$`:匹配内容左边 $':匹配内容右边 $&:匹配的内容
let str = "=hello="
let result=str.replace(/hello/,"$&")
console.log(result)
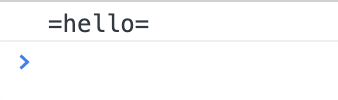
let result=str.replace(/hello/,"$&world")

let str = "=hello="
let result=str.replace(/hello/,"$`")
console.log(result)

let str = "=hello*"
let result=str.replace(/hello/,"$'")
console.log(result)

31、$&的使用
<main>
百度一下,你就知道
</main>
<script>
const main=document.querySelector("body main")
main.innerHTML=main.innerHTML.replace("百度一下",`<a href="https://www.baidu.com">$&</a>`)
</script>

32、原子组别名
let str=`
<h1>百度</h1>
<span>新浪</span>
<h1>微博</h1>
`
const reg=/<(h[1-6])>.*<\/\1>/ig
console.log(str.replace(reg,"<h4>$2</h4>"))
我们还可以通过?<> 的方式给原子组起别名
const reg=/<(h[1-6])>(?<content>.*)<\/\1>/ig
console.log(str.replace(reg,"<h4>$<content></h4>"))

33、使用原子组别名优化正则
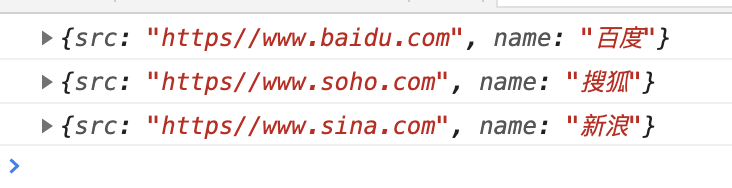
<main>
<a id="baidu" href="https//www.baidu.com">百度</a>
<a id="soho" href="https//www.soho.com">搜狐</a>
<a id="sina" href="https//www.sina.com">新浪</a>
</main>
<script>
const main=document.querySelector("body main");
const reg=/<a.*?href=(["'])(?<src>.*?)\1>(?<name>.*?)<\/a>/ig
for (const item of main.innerHTML.matchAll(reg)){
console.log(item["groups"])
}
</script>
34、零宽现行断言 (限制后面是什么)
我们想给只有"瓜子二手车"里面的瓜子加上链接。
<main>
瓜子二手车,没有中间商赚差价,买二手车上瓜子
</main>
<script>
let main=document.querySelector("main");
let reg=/瓜子(?=二手车)/g
main.innerHTML=main.innerHTML.replace(reg,`<a href="https//www.baidu.com">$&</a>`)
</script>

35、使用断言规范价格
let lessons = `
js,200元,300次
php,300.00元,100次
node,180元,200次
`
let reg = /(\d+)(.00)?(?=元)/ig
lessons = lessons.replace(reg, (v, ...args) => {
args[1] = args[1] || ".00"
return args.splice(0, 2).join("")
})
console.log(lessons)

36、零宽后行断言
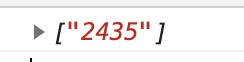
let str = "hello2435world2345"
const reg = /(?<=llo)\d+/ig
console.log(str.match(reg))
37、使用断言模糊电话号
let user = `
张三:12345678901
李四:09876543210
`
let reg = /(?<=\d{7})\d{4}/ig
user = user.replace(reg, v => {
return "*".repeat(4)
})
console.log(user)

38、零宽负向先行断言
?!:限制后面不是什么
如下代码,我们想取出"world",
let str = "hell2020world"
let reg = /[a-z]+(?!\d+)$/i
console.log(str.match(reg))
39、断言限制用户名关键词
如果我们要限制用户输入的用户名开头不能是“亚索”
let ipt = document.querySelector("[name=username]");
ipt.addEventListener("keyup", function () {
const reg = /^(?!亚索).*/i;
console.log(this.value.match(reg))
})

如果是在开头之后的任何位置都不能出现“亚索”这两个字,正则如下:
const reg = /^(?!.*亚索.*).*/i;
40、零宽负向后行断言(前面不是什么)
?<!:用来限制前面不是什么
let str = "hello2020world"
let reg = /(?<!\d+)[a-z]+/i
console.log(str.match(reg))

41、使用断言排除法统一数据
const main = document.querySelector("main");
const reg = /https:\/\/([a-z]+)?(?<!oss)\..+?(?=\/)/ig
main.innerHTML = main.innerHTML.replace(reg, v => {
return "https://oss.houdunren.com"
})
















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









