






hadoop简易集群搭建(3节点 完全分布式)
前期准备工作—(已经下载下列软件包的无需重复下载)
-
hadoop3.x安装包下载地址: https://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3.tar.gz
-
centos7镜像下载地址: https://mirrors.tuna.tsinghua.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-2009.iso
-
xshell下载地址: https://wwp.lanzoul.com/iNy71v58rhi
-
xftp下载地址: https://wwp.lanzoul.com/iiQNpv57b1a
-
jdk1.8下载地址: https://www.oracle.com/java/technologies/downloads/#license-lightbox
注意!在orcale官网下载jdk1.8需要登录
新建虚拟机
-
点击创建新的虚拟机

-
选择自定义
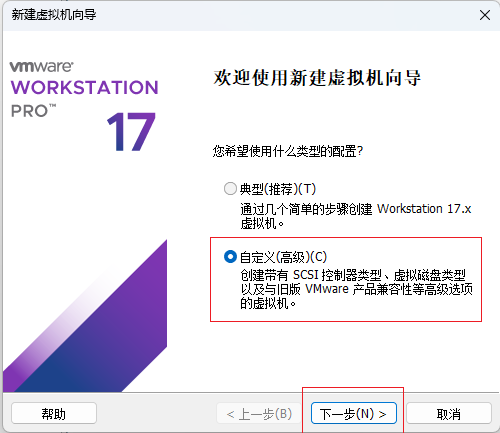
-
虚拟机硬件兼容性默认即可
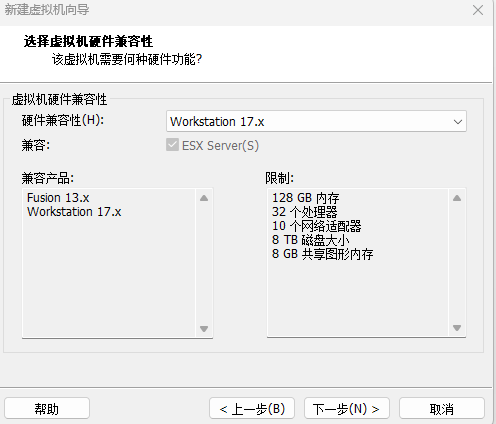
-
选择下载好的centos7光盘镜像
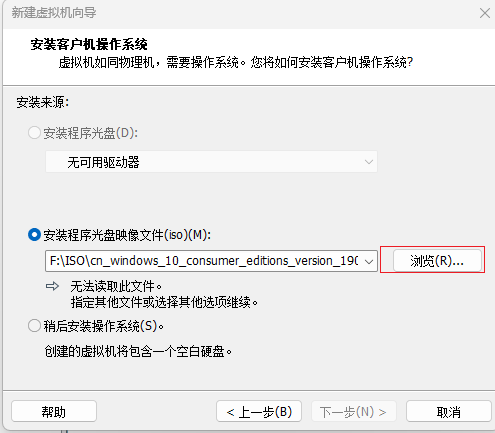
-
找到你下载好的iso镜像位置,点击打开
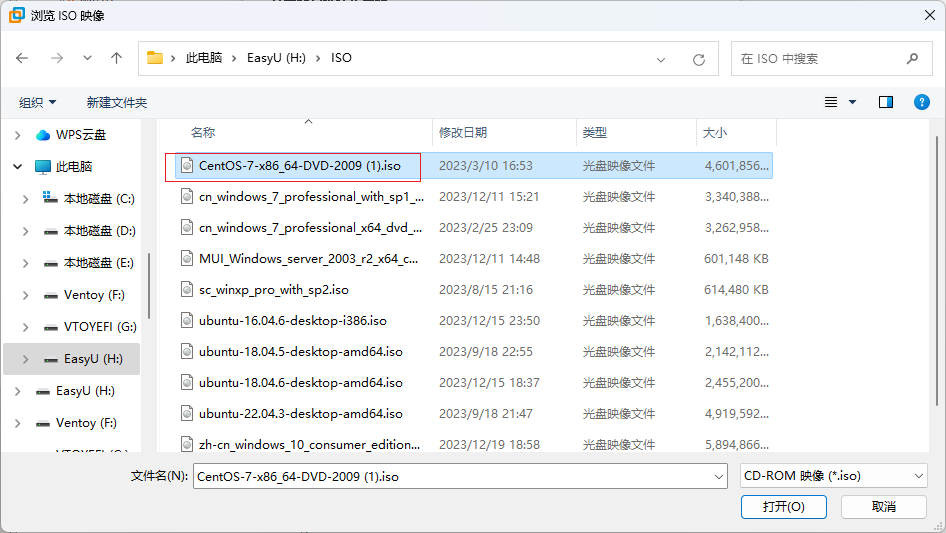
-
显示检测到centos7操作系统就可以了
-
名称、用户名等可自定义
-
修改虚拟机存放位置,尽量存放在空闲磁盘
-
处理器配置随意,vm允许配置超过本机的cpu核心数
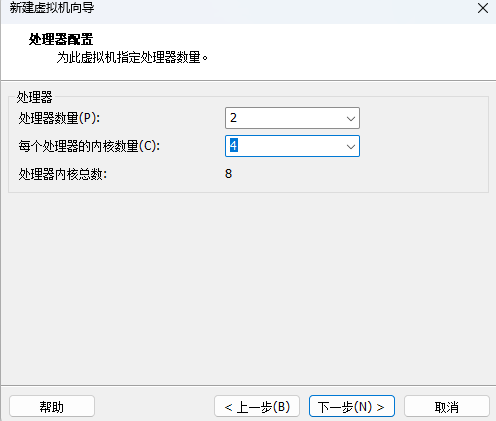
-
内存分配根据自己电脑性能而定,最低不能低于512MB,多多益善
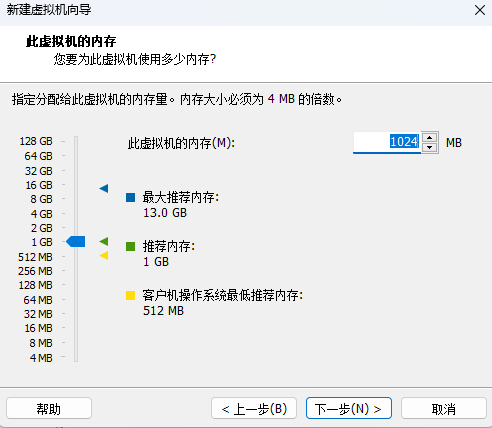
-
使用NAT网络类型
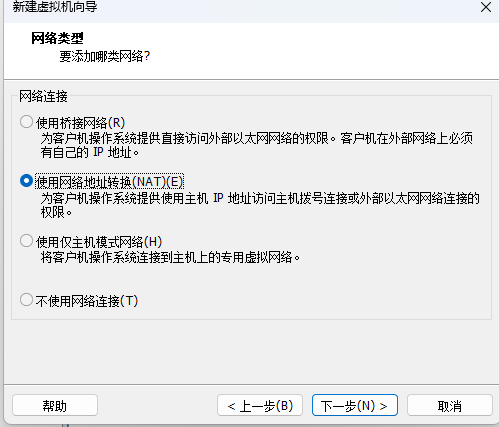
-
IO控制器默认
-
磁盘类型默认
-
选择磁盘默认
-
磁盘容量40GB,这不是实际占用的磁盘大小,请放心
-
指定磁盘文件默认
-
点击完成,等待安装
-
安装完成
-
登录,用户密码是刚刚在新建虚拟机时的那个账号密码
-
右键打开终端
-
切换到root用户
su - root注意!此处需要输入密码,密码就是你在新建虚拟机时写的那个用户密码,这里输入密码没有回显!

-
安装网络组件
yum install net-tools -
配置虚拟机网络环境
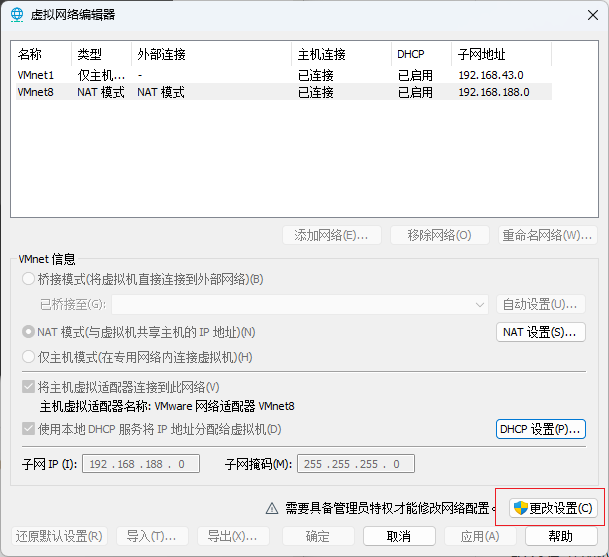
-
配置VM8虚拟网卡的dhcp服务器分配地址范围
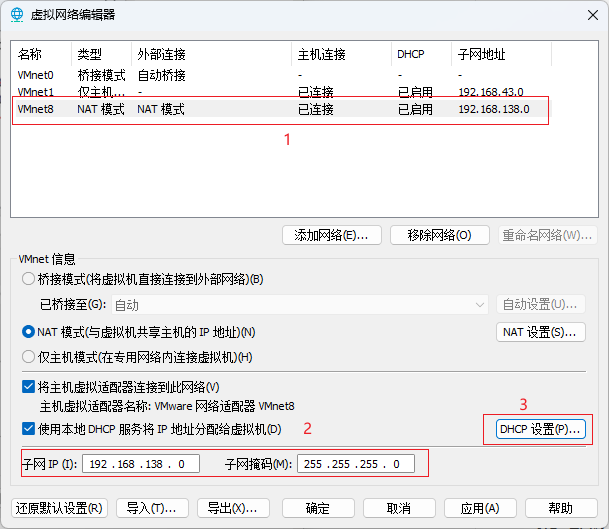
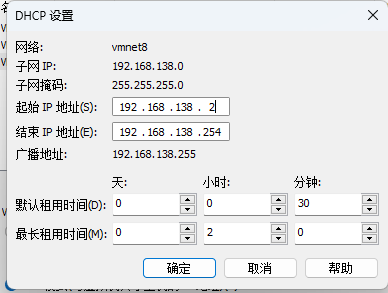
-
配置网关
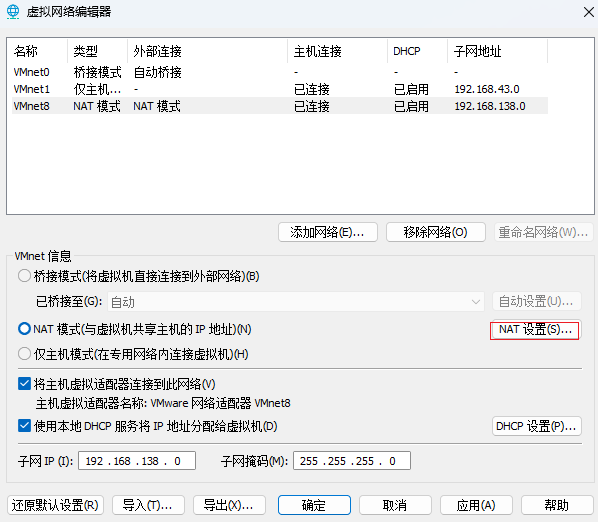
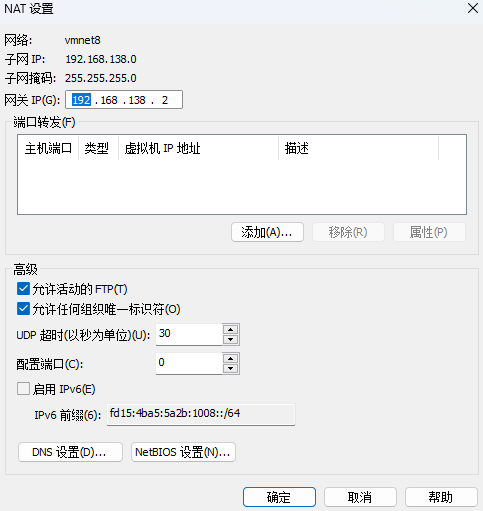
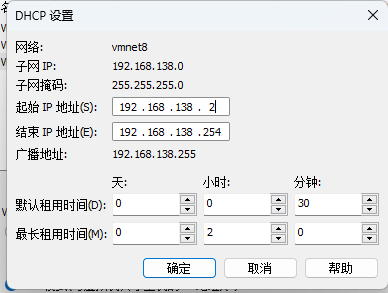
-
-
重启虚拟机
reboot
-
重启后打开终端,切换到root用户
su - root -
配置网络文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33注意,网卡的名字不同,配置文件也不同!
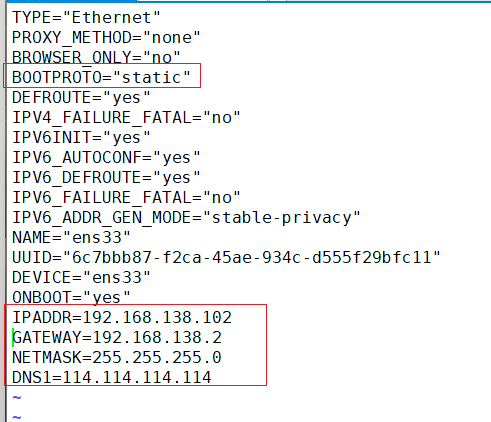
保存退出
-
设置root密码
passwd root
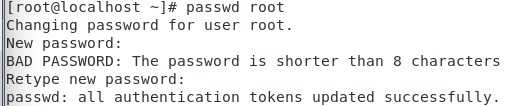
设置密码为root
-
重启虚拟机
reboot -
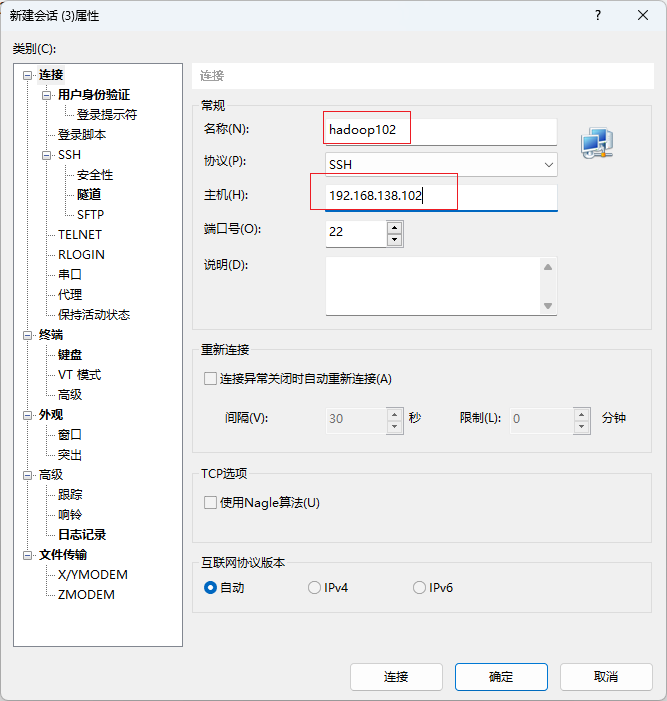
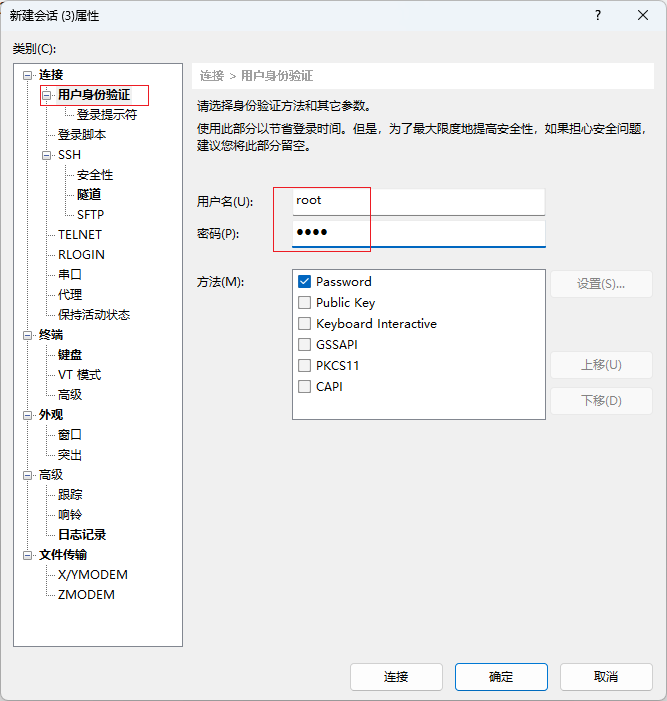
打开xshell,连接虚拟机
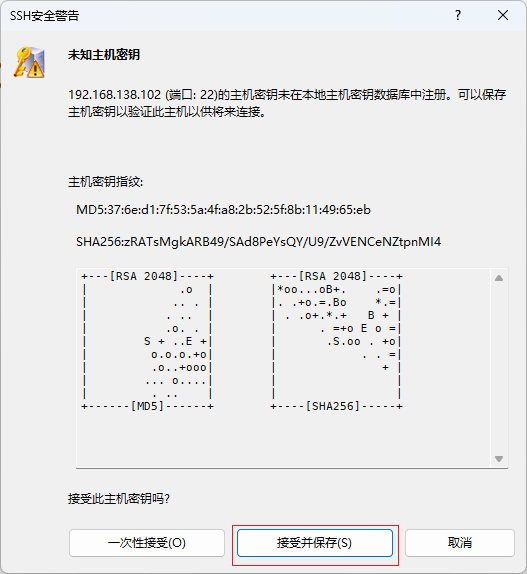
-
安装分发工具
yum install rsync -y
-
编写集群分发脚本
mkdir ~/bin && vim ~/bin/xsync#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 #这里的主机名是hadoop101~hadoop103,要根据情况修改代码 for i in hadoop102 hadoop103 hadoop104 do echo ------------------- $i -------------- rsync -rvl $pdir/$fname $user@$i:$pdir done -
给脚本赋权
chmod +x ~/bin/xsync -
关机
init 0 -
右键,克隆虚拟机
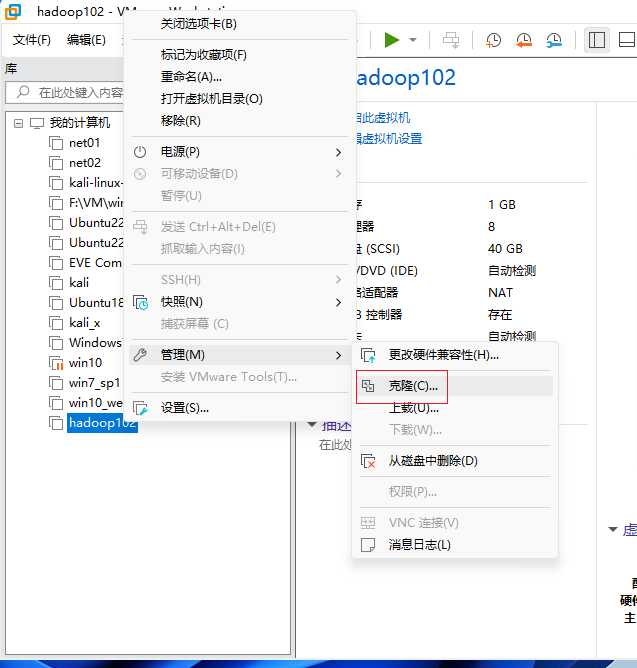
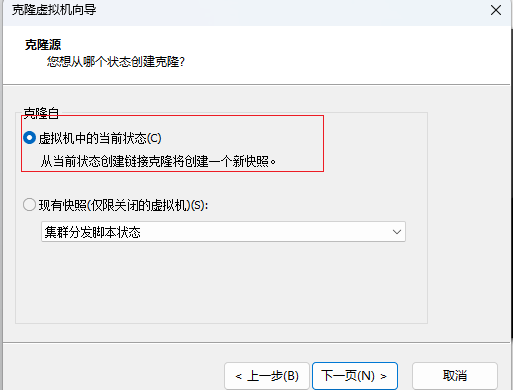
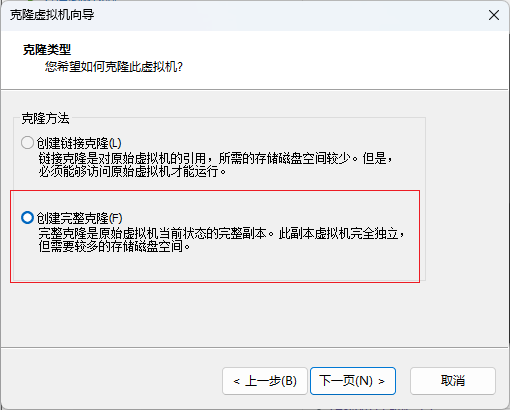
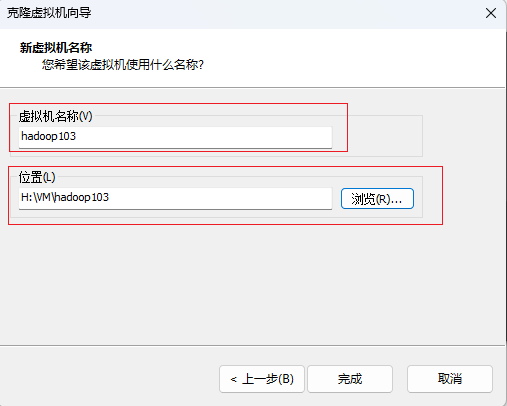
点击完成,克隆成功
再按照以上步骤克隆一台虚拟机,名称为hadoop104
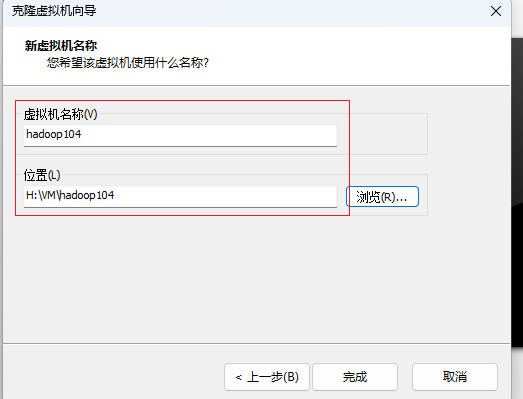
完成后如下图
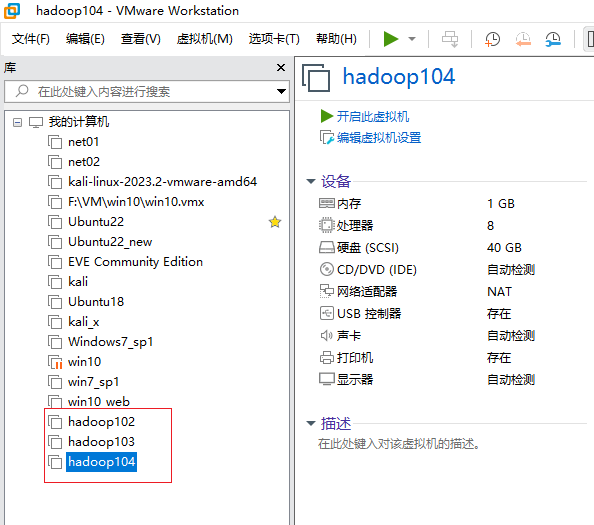
-
配置克隆的网络文件
-
开启hadoop103,切换至root用户
su - root密码是root
-
编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33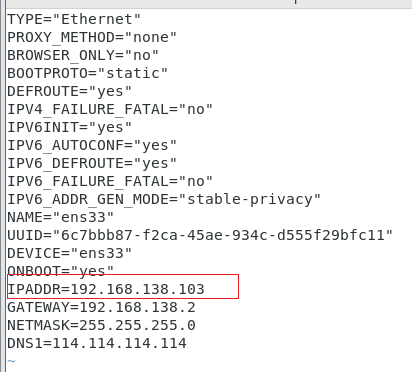
保存退出
-
重启
reboot -
开启hadoop104
-
切换至root用户
su - root -
编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33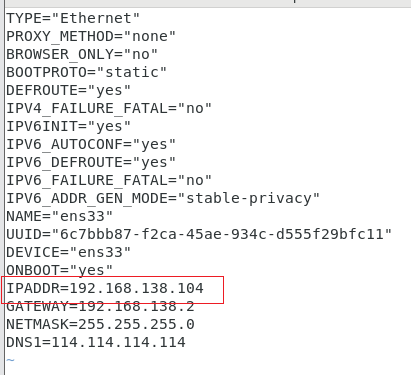
保存退出
-
重启hadoop104
reboot
-
-
启动hadoop102

确保3台节点启动成功
-
打开xshell,新建两个会话
-
hadoop103会话
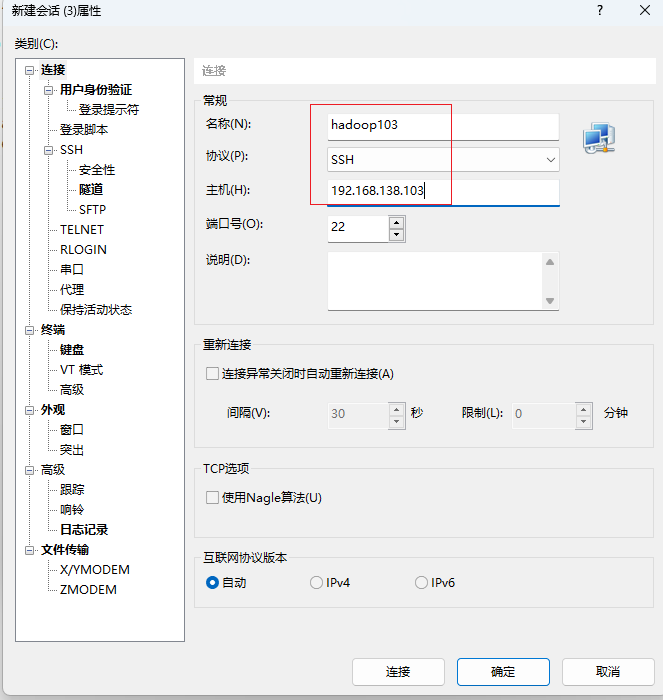
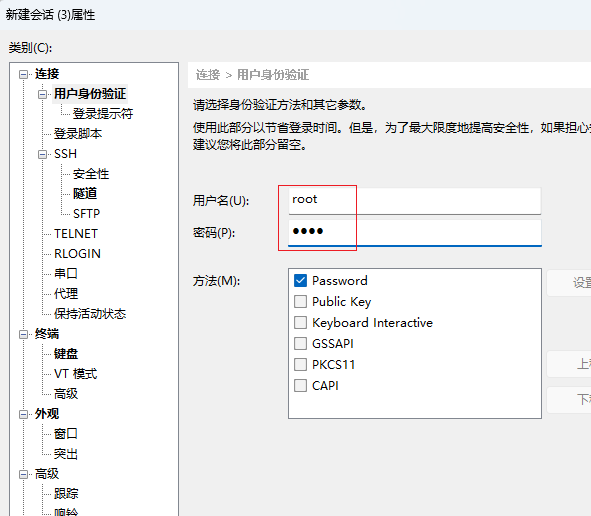
点击确定
-
hadoop104会话
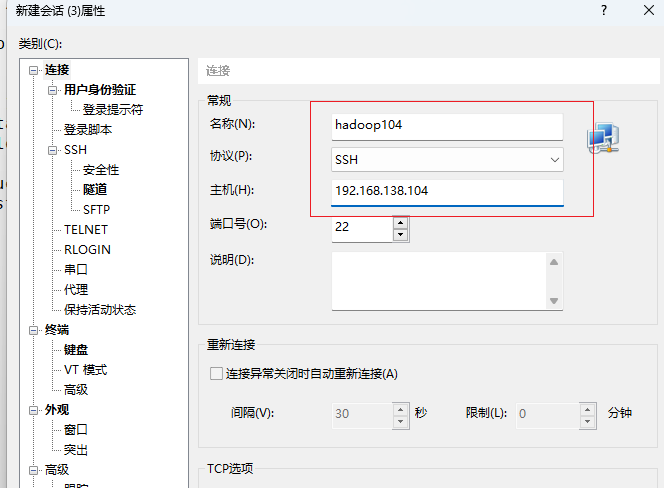
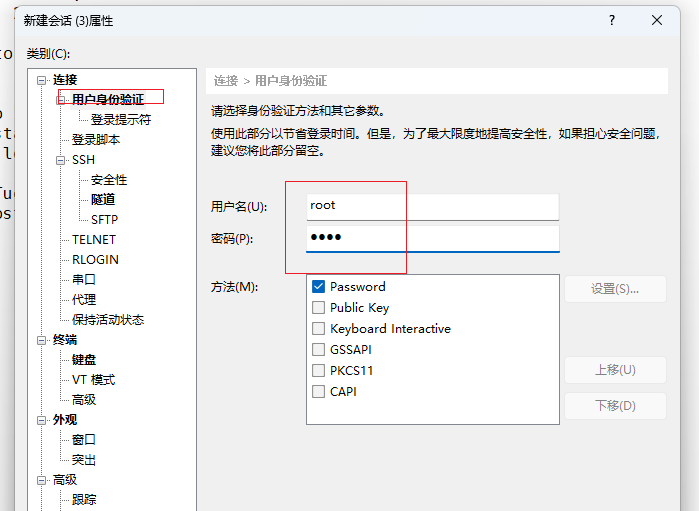
点击确定
-
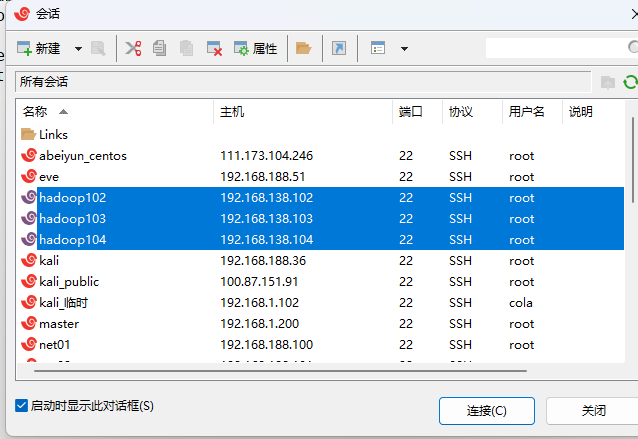
连接
选中3个会话,点击连接
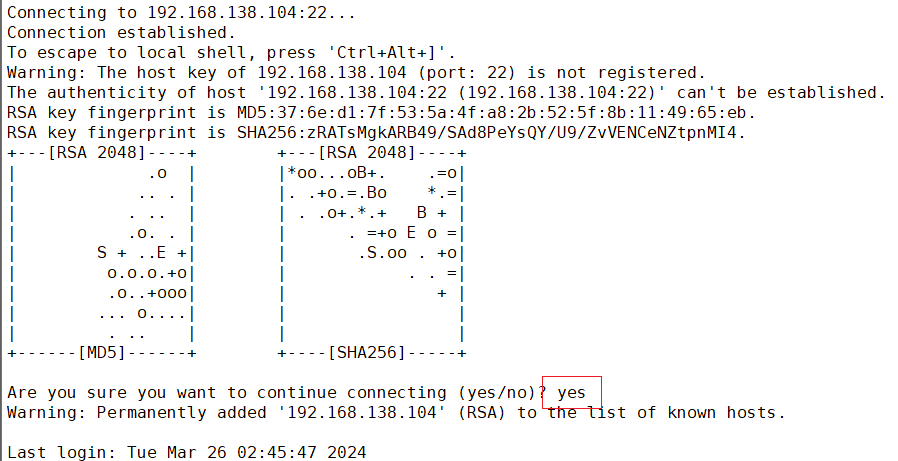
弹出如下提示,输入yes即可
-
搭建hadoop3.x完全分布式集群
集群规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| namenode | resourcemanager | datanode |
| datanode | datanode | nodemanager |
| nodemanager | nodemanager | secondarynamenode |
-
配置host映射
-
点击hadoop102选项卡
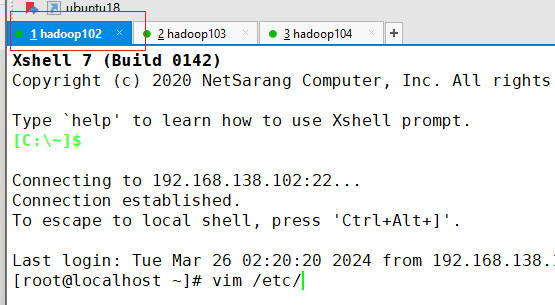
-
编辑hosts文件
vim /etc/hosts192.168.138.102 hadoop102 192.168.138.103 hadoop103 192.168.138.104 hadoop104
保存退出
-
-
配置集群ssh
-
hadoop102配置ssh无密登录
ssh-keygen -t rsa一直回车即可
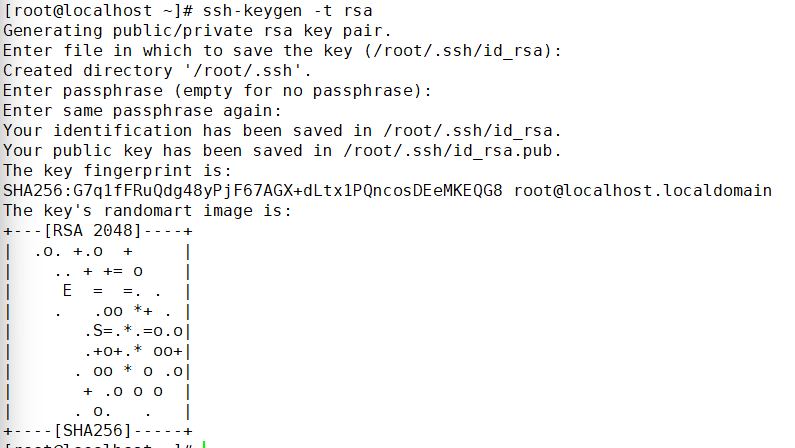
ssh-copy-id hadoop102输入yes,提示输入密码的地方输入root,这里也是没有回显的!!
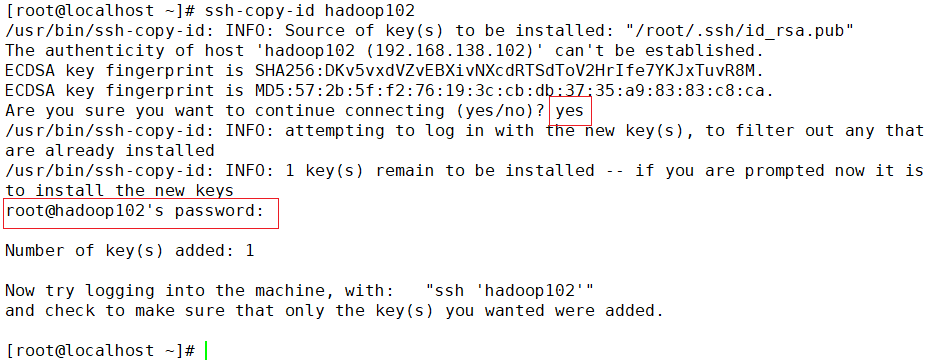
如上操作再将公钥复制到hadoop103、hadoop104
ssh-copy-id hadoop103ssh-copy-id hadoop104 -
分发hosts
xsync /etc/hosts -
hadoop103配置ssh无密登录
点击hadoop103选项卡
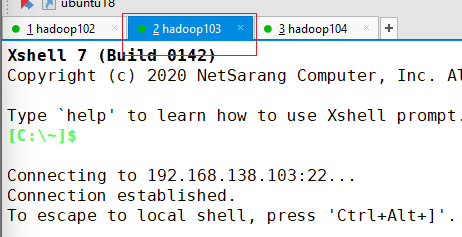
生成公钥
ssh-keygen -t rsa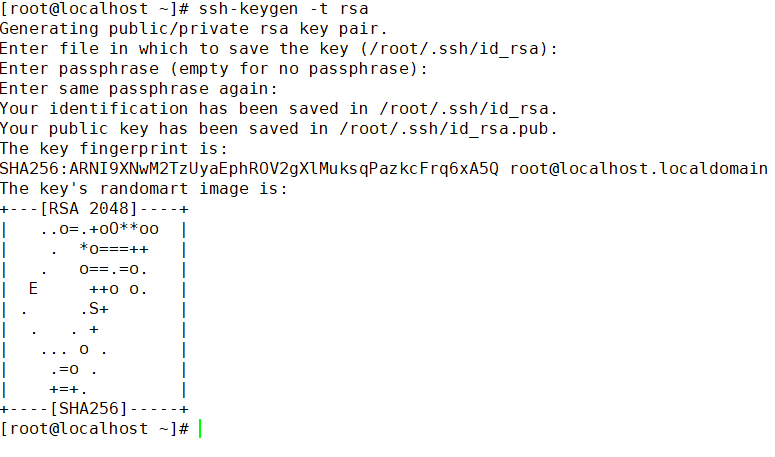
如hadoop102的操作,将公钥复制到其他节点
ssh-copy-id hadoop102ssh-copy-id hadoop103ssh-copy-id hadoop104 -
hadoop104配置ssh无密登录
选择hadoop104选项卡
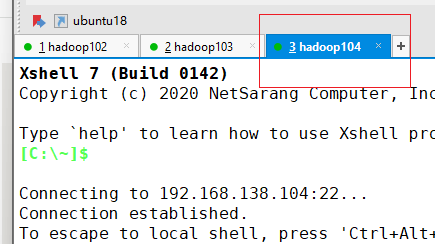
生成公钥
ssh-keygen -t rsa复制公钥到其他节点
ssh-copy-id hadoop102ssh-copy-id hadoop103ssh-copy-id hadoop104
-
-
上传hadoop安装包
-
回到hadoop102选项卡
创建目录
mkdir /opt/software && cd /opt/software -
上传安装包
开启xftp
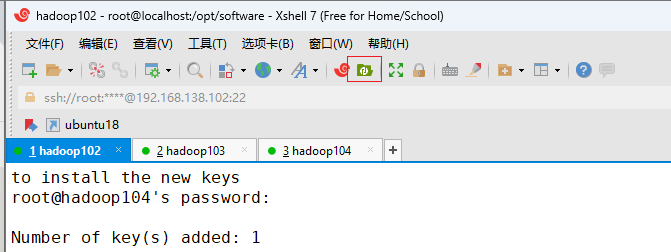
将下载好的hadoop和jdk移动到右边

回到xshell
-
创建目录并解压
mkdir /opt/moduletar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/tar -zxvf /opt/software/jdk-8u401-linux-x64.tar.gz -C /opt/module/ -
改名
mv /opt/module/jdk1.8.0_401/ /opt/module/jdk
-
-
添加JAVA_HOME
-
添加java环境变量
vim /etc/profile#JAVA_HOME export JAVA_HOME=/opt/module/jdk export PATH=$PATH:$JAVA_HOME/bin
-
-
添加HADOOP_HOME
-
添加hadoop环境变量
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
保存退出
-
刷新环境变量
source /etc/profile -
分发环境变量
xsync /etc/profile
-
-
修改配置文件
-
改名
mv /opt/module/hadoop-3.1.3/ /opt/module/hadoop -
core-site.xml
vim /opt/module/hadoop/etc/hadoop/core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop/data</value> </property> </configuration>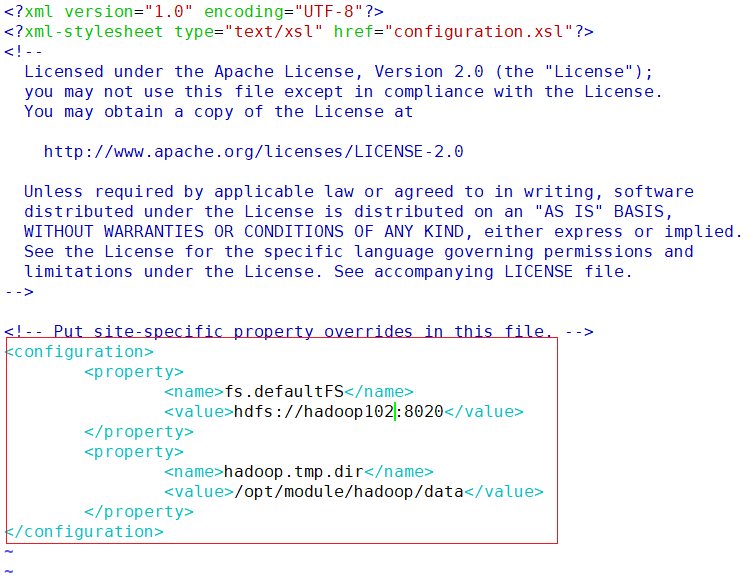
保存退出
-
hdfs-site.xml
vim /opt/module/hadoop/etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration>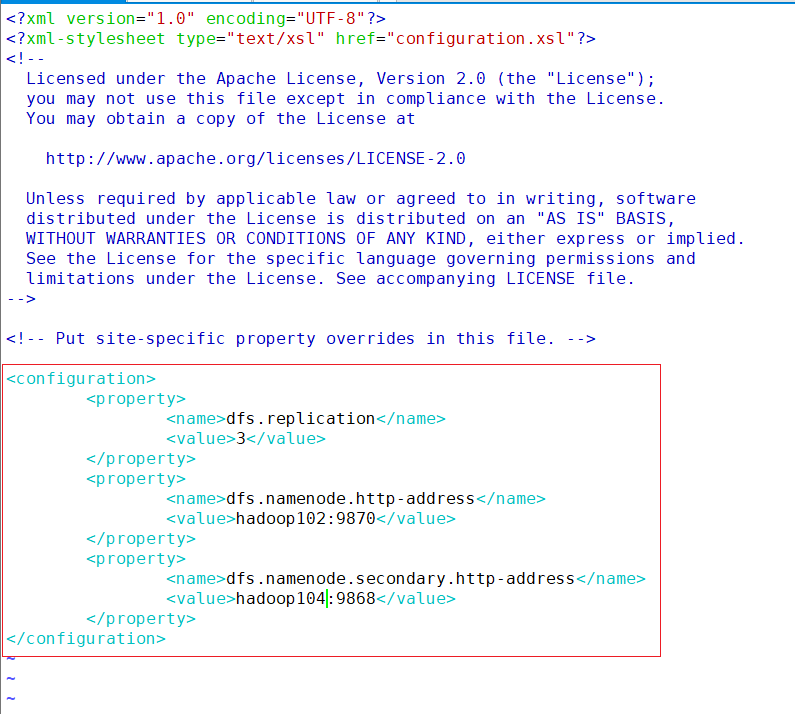
-
yarn-site.xml
vim /opt/module/hadoop/etc/hadoop/yarn-site.xml<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> </configuration>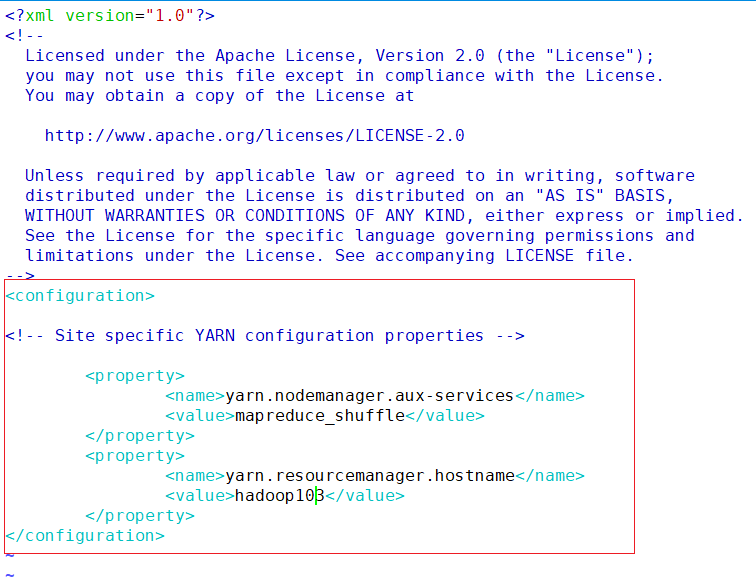
-
mapred-site.xml
vim /opt/module/hadoop/etc/hadoop/mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property> </configuration>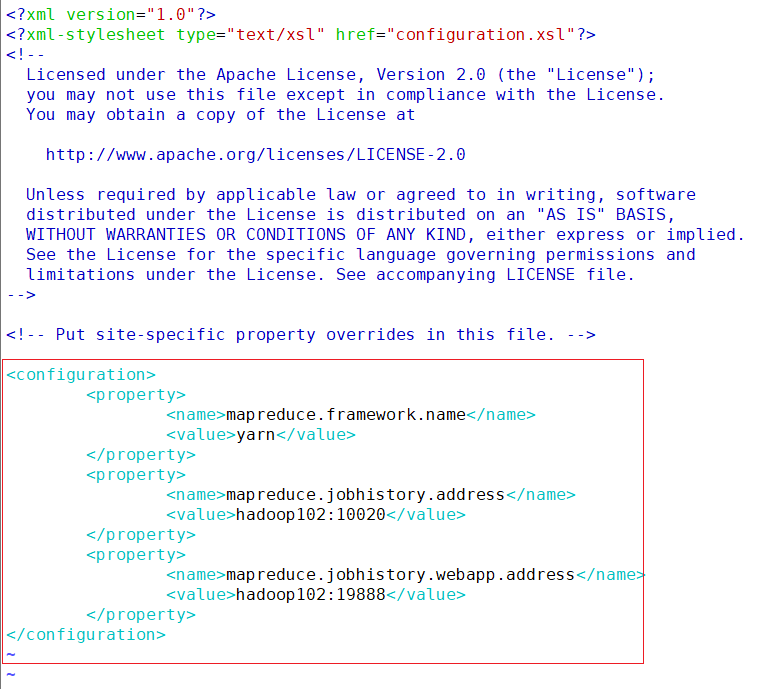
-
在hadoop-env.sh配置java环境变量
vim /opt/module/hadoop/etc/hadoop/hadoop-env.sh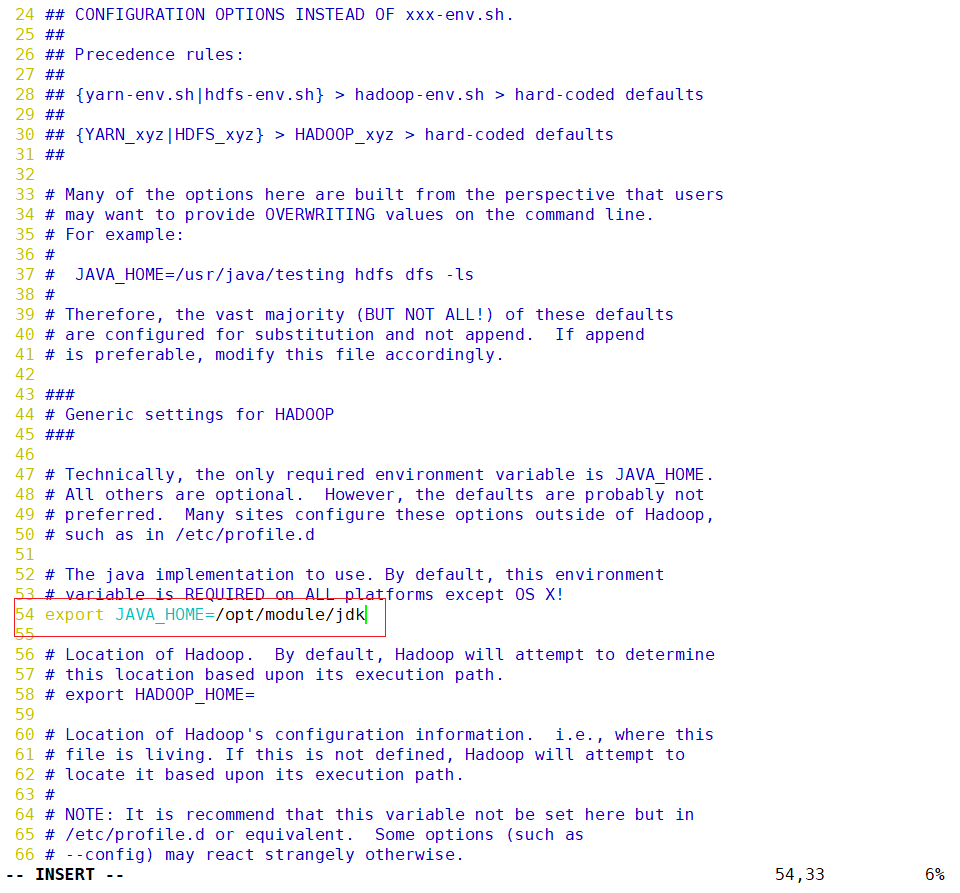
保存退出
-
在sbin/start-dfs.sh , sbin/stop-dfs.sh 两个文件顶部添加以下参数
vim /opt/module/hadoop/sbin/start-dfs.shHDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root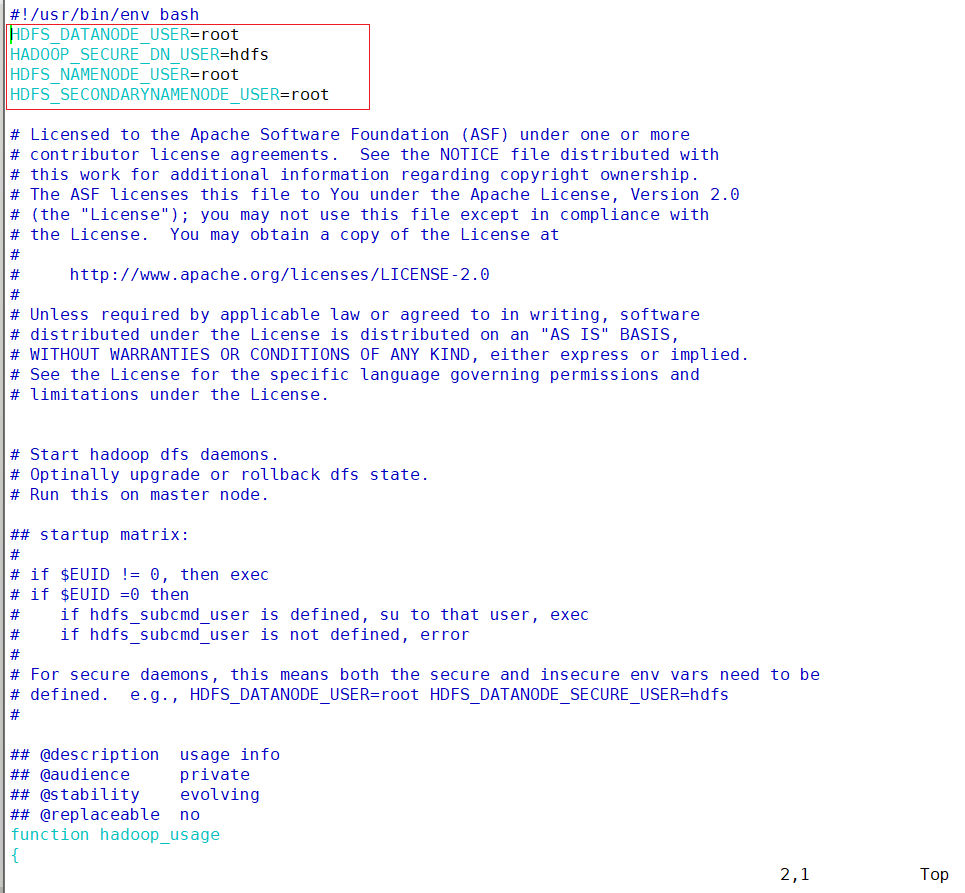
vim /opt/module/hadoop/sbin/stop-dfs.sh#!/usr/bin/env bash HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root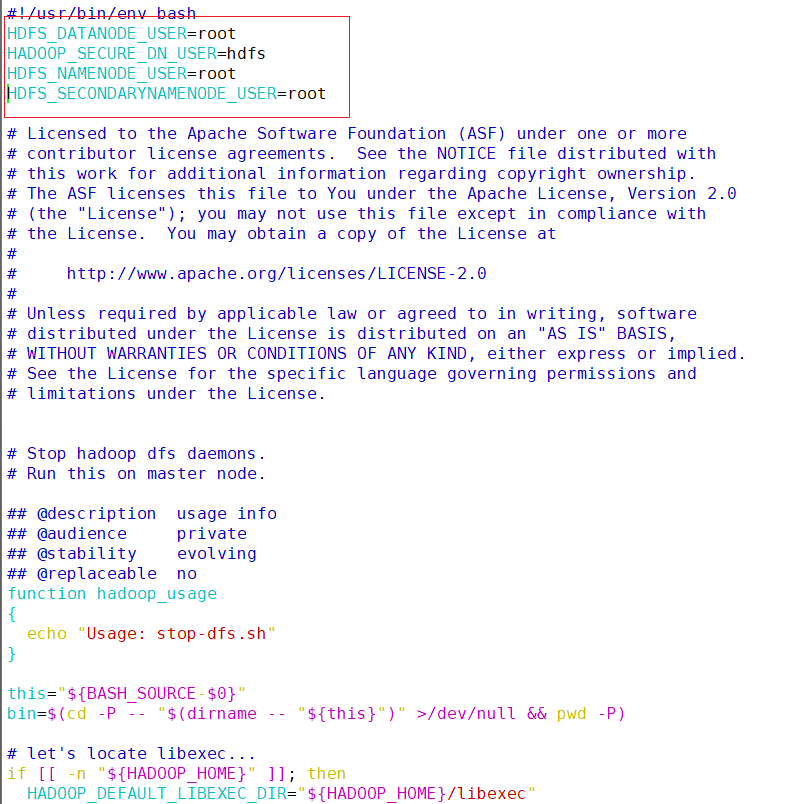
-
在sbin/start-yarn.sh , sbin/stop-yarn.sh两个文件顶部添加以下参数
vim /opt/module/hadoop/sbin/start-yarn.shYARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root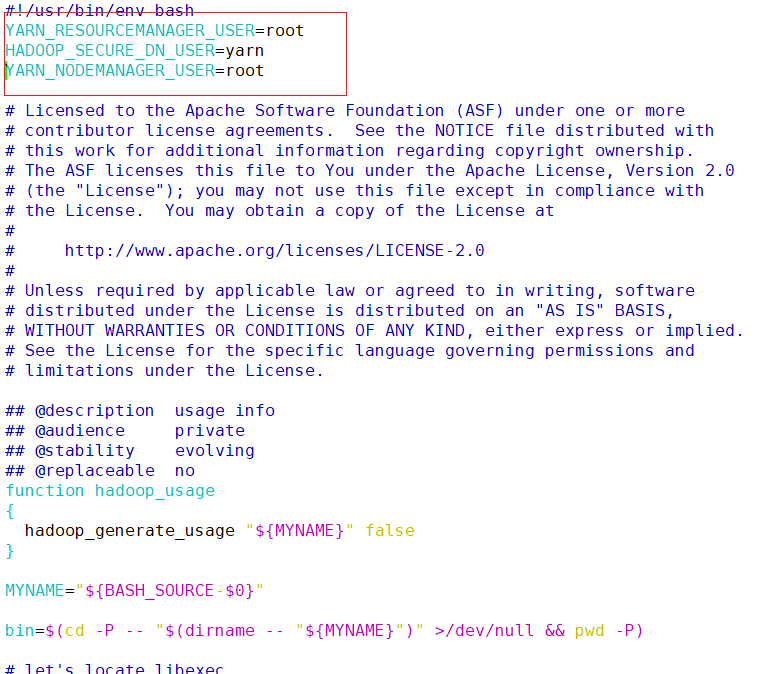
vim /opt/module/hadoop/sbin/stop-yarn.shYARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
-
编辑workers添加集群节点主机名
vim /opt/module/hadoop/etc/hadoop/workershadoop102 hadoop103 hadoop104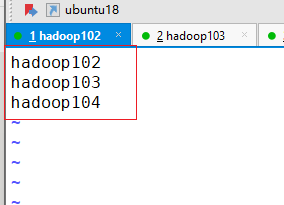
-
分发module目录
xsync /opt/module -
格式化hdfs
hdfs namenode -format -
关闭防火墙
每台节点都执行以下命令
systemctl stop firewalld && systemctl disable firewalld -
启动hadoop
start-dfs.sh注意!yarn需要在hadoop103启动
切换到hadoop103
source /etc/profilestart-yarn.sh切换到hadoop104
source /etc/profile -
在各节点输入jps命令查看hadoop进程
hadoop102
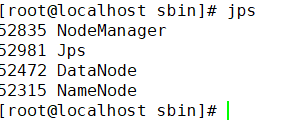
hadoop103
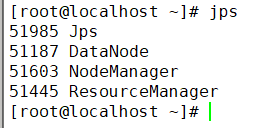
hadoop104
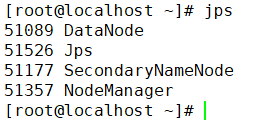
-
-
在网页浏览器访问hadoop web页面
192.168.138.102:9870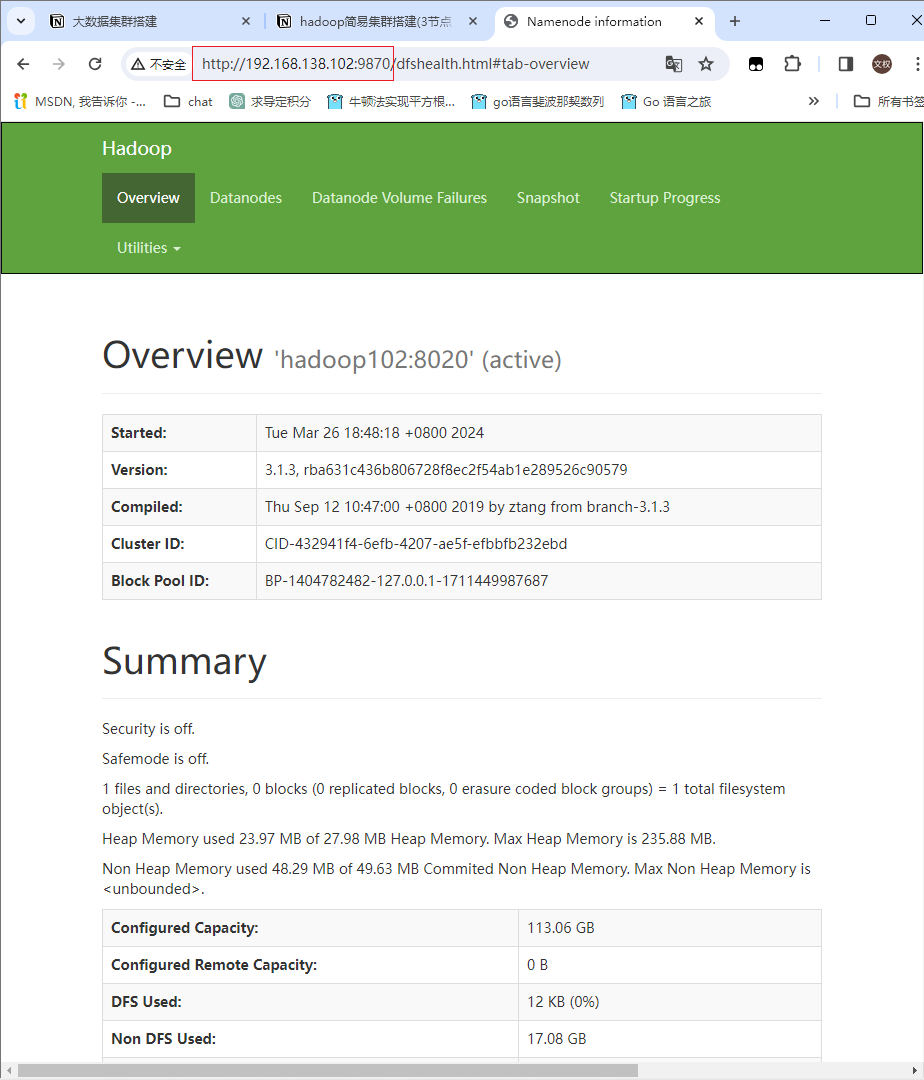
搭建完成!!














 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









