







在Linux环境下C程序经常会出现A segmentation fault(段错误),如果我们的程序只有几十行,那么我们可以通过printf输出调试来找到哪个地方出现了异常,但如果是在项目中,如果我们还是通过print找查找错误,那么效率会很低。那么我们来学习一下Linux环境下通过core文件来找到发生段错误的位置。
1. 什么是core文件?
对于c程序员来说,core文件是分析内存错误的有用的文件,结合gdb命令,一般情况下(有时候代码编译的时候没有包含debug信息或者栈空间被破坏,会看不到具体的位置信息),可以知道导致core的具体的代码位置。当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”)。我们可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump 对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序 出错时的情景。
2. 在Ubuntu20中怎么开启core dump功能
在终端输入命令:ulimit -c

输出结果为0,说明默认是关闭core dump的。
使用命令 ulimit -c unlimited 来开启core dump功能,并且不限制core dump文件的大小;如果需要限制文件的大小,将unlimited改成core文件最大的大小,单位为blocks(KB)

用上面的命令只会对当前的终端环境有效,如果想要永久生效,可以参考以下方法:
法一:
修改/etc/security/limits.conf参考以下代码:
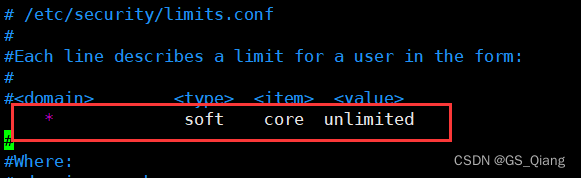
法二:
编辑 .bashrc 文件:
vim ~/.bashrc
添加:
ulimit -c unlimited
保存,退出。
source ~/.bashrc
source命令使修改立即生效。就可以了。
更改core文件生成目录
通过cat /proc/sys/kernel/core_pattern命令查看core文件保存路径。
如果想要把core文件生成在当前目录下,可以通过以下命令进行修改。
echo core-%e-%p-%t > /proc/sys/kernel/core_pattern
将更改core文件生成路径,自动放在这个当前目录下。
core文件参数详情:
%p - insert pid into filename 添加pid
%u - insert current uid into filename 添加当前uid
%g - insert current gid into filename 添加当前gid
%s - insert signal that caused the coredump into the filename 添加导致产生core的信号
%t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间
%h - insert hostname where the coredump happened into filename 添加主机名
%e - insert coredumping executable name into filename 添加程序名
3. 测试
#include <stdio.h>
int main() {
int *p = NULL;
*p = 2;
printf("%d\n",*p);
return 0;
}
//编译,编译时需要加上-g参数
gcc -o test -g test.c
//执行
./test
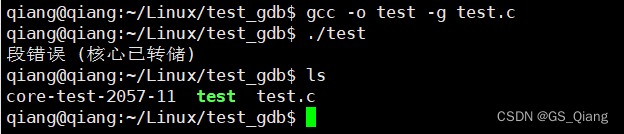
当前目录下生成了一个core文件,文件名中的test表示添加程序名、2057表示添加pid、11表示添加core文件生成时的unix时间。
//调试文件
gdb test core-test-2057-11
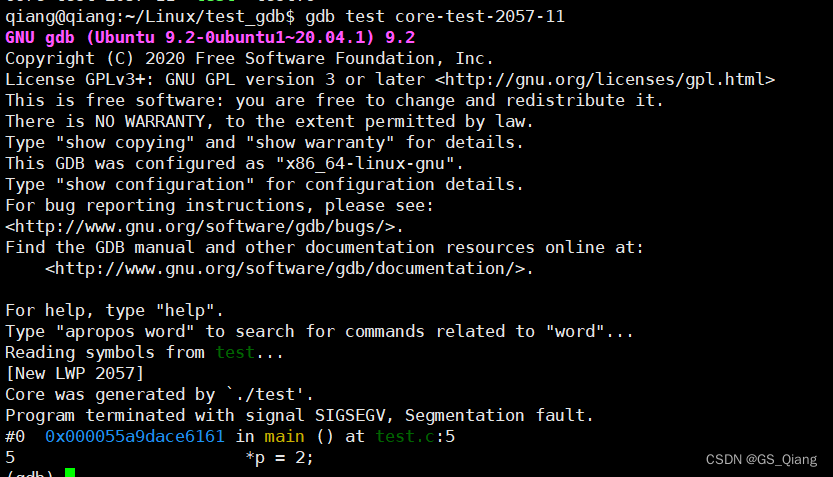
通过调试文件可以看到段错误发生在test.c:5的*p=2处。
4. 常见的GDB调试命令
在使用gcc/g++编译文件时,要加上-g参数
例如:
gcc -o learn_gdb -g learn_gdb.c
进入gdb:
gdb learn_gdb -q
常用命令:
调试命令 (缩写) 作用
(gdb) break (b) 在源代码指定的某一行设置断点,其中xxx用于指定具体打断点位置
(gdb) run (r) 执行被调试的程序,其会自动在第一个断点处暂停执行。
(gdb) continue (c) 当程序在某一断点处停止后,用该指令可以继续执行,直至遇到断点或者程序结束。
(gdb) next (n) 令程序一行代码一行代码的执行。
(gdb) step(s) 如果有调用函数,进入调用的函数内部;否则,和 next 命令的功能一样。
(gdb) until (u)
(gdb) until (u) location 当你厌倦了在一个循环体内单步跟踪时,单纯使用 until 命令,可以运行程序直到退出循环体。
until n 命令中,n 为某一行代码的行号,该命令会使程序运行至第 n 行代码处停止。
(gdb) print (p) 打印指定变量的值,其中 xxx 指的就是某一变量名。
(gdb) list (l) 显示源程序代码的内容,包括各行代码所在的行号。
(gdb) finish(fi) 结束当前正在执行的函数,并在跳出函数后暂停程序的执行。
(gdb) return(return) 结束当前调用函数并返回指定值,到上一层函数调用处停止程序执行。
(gdb) jump(j) 使程序从当前要执行的代码处,直接跳转到指定位置处继续执行后续的代码。
(gdb) quit (q) 终止调试。
(gdb) Backtrace(bt) 查看堆栈。
(gdb) info threads 显示当前可调试的所有线程
(gdb) thread ID 切换当前调试的线程为指定ID的线程
(gdb) attach process-id 在gdb状态下,开始调试一个正在运行的进程
(gdb) thread apply all command 所有线程执行command















 1374
1374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









