豆瓣排行榜爬虫
利用正则表达式匹配目标字符来对数据进行爬取
import random
import re
import requests
import csv
fp = open('../others/doubantop250.csv','a+',encoding='utf-8',newline='')
writer = csv.writer(fp)
url = "https://movie.douban.com/top250?start="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1660.57"
}
proxies = [
{'http': '42.63.65.37:80'},
{'http': '42.63.65.13:80'},
{'http': '42.63.65.15:80'},
{'http': '42.63.65.7:80'},
{'http': '42.63.65.8:80'},
{'http': '42.63.65.9:80'},
{'http': '39.173.106.248:80'},
{'http': '39.173.106.249:80'},
]
proxy = random.choice(proxies)
for i in range(0, 226, 25):
new_url = url + str(i)
response = requests.get(url=new_url, headers=headers, proxies=proxy)
content = response.text
moviestitle = re.compile(
r'<div class="item">.*?<span class="title">(?P<moviename>.*?)</span>.*?<p class="">.*?导演:(?P<editor>.*?) .*?主演:(?P<actor>.*?)<br>.*?(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?<span>(?P<numbersofevaluators>.*?)</span>',
re.S)
result = moviestitle.finditer(content)
for item in result:
name = item.group("moviename")
editor = item.group("editor")
actor = item.group("actor")
year = item.group("year").strip()
score = item.group("score")
numbersofevaluators = item.group("numbersofevaluators")
print(name, editor, actor, year, score, numbersofevaluators)
movieinfo=[name,editor,actor,year,score,numbersofevaluators]
writer.writerow(movieinfo)
fp.close()
response.close()
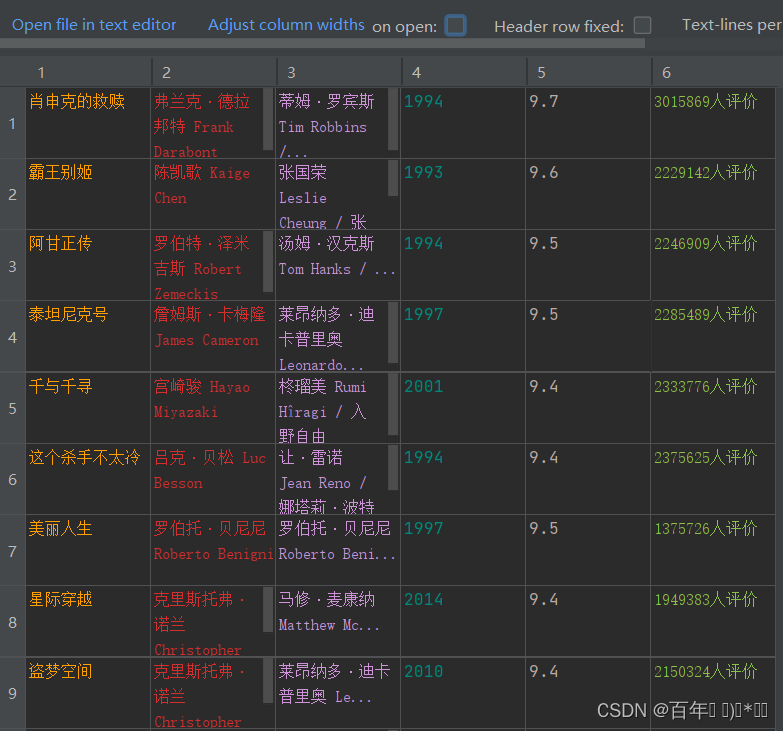
结果


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









