






前后端交互
浏览器输入域名到页面显示完整的流程
1.浏览器输入地址比如http://www.baidu.com,根据域名和端口号通过DNS解析成IP地址
2.根据IP地址以及端口号找到对应的服务器
(http协议中的tcp协议 )协议三次握手和四次挥手
http的默认端口号80
https默认端口号443
ftp默认端口21
mysql默认端口号3306
3.服务器接收到来自前端的请求,分配到对应路由‘/’
4.在路由里取到对应的文件。例如 index.html
(1)直接将index.html文件返回
a.有可能首页没什么数据,就是个静态页
b.也有可能页面并不完整,但是后端不渲染,先返回给前端,后期前端通过ajax重新渲染
(2)先取出index.html,然后再从数据库里拿到数据,根据数据完成页面模板替换,数据填充,得到完整的页面html字符串,再返回给前端(后端渲染)
注:1.前端渲染减轻服务器压力,但是不利于搜索引擎优化
2.后端渲染服务器压力较大,但是利于搜索引擎优化
5.浏览器拿到index.html了,就开始渲染
6.如果遇到了link标签,继续向对应服务器发送一个http请求,请求css文件,渲染样式
7.如果遇到了script标签,继续向对应服务器发送一个http请求,请求js文件,执行逻辑
8.如果js里有ajax请求,就会请求对应服务器
(1)异步请求,再回调里才能拿到结果,或者可以使用promise
(2)状态码
(3)数据格式,一般来讲都是json
9.服务器进入相应的路由,在这个路由代码里就会去查找数据库,得到json格式的数据,再返回给前端
10.前端拿到json数据以后更新页面的部分内容
HTTP协议超详讲解
HTTP协议简介
超文本传输协议,是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网数据通信的基础。
HTTP协议概述
HTTP是一个客户终端(用户)和服务器端(网站)请求和答应是标准(TCP)。通过使用网页浏览,网络爬虫或者其他的工具,客户端发起一个HTTP协议到服务器上指定端口(默认端口为80)。我们成这个客户端为用户代理程序(user agent)。应答的服务器上存着一些资源,比如HTML文件和图像。我们称这个应答服务器为原服务器(origin server)。在用户代理和原服务器中间可能存在多个中间层,比如代理服务器、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用他或他支持的层。事实上,HTTP协议可以在任何互联网协议上,或其他网络上实现。HRRP假定其它下层协议提供可靠传输。因此,任何能够提供这种保证的协议都可以被其他使用。因此也就是在其他TCP/IP协议族中使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器就会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求文件、错误消息、或者其他信息。
HTTP工作原理
HTTP协议定义web客户端如何从web服务器请求web页面,以及服务器如何把web页面传给客户端。HTTP协议采用了请求/相应模型。客户端向服务器发送一个请求报文,请求报文含请求的方法、URL、协议版本、请求头部和请求数据。
注:套接字(Socket),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程,下联网络协议栈,是应用程序通过网络协议进行通信的接口,是应用程序与网络协议根进行交互的接口。
以下是HTTP请求/相应的步骤
1.客户端连接到web服务器
一个HTTP客户端,通常是浏览器,与web服务器的HTTP端口建立一个TCP套接字连接。
2.发送HTTP请求
通过TCP套接字,客户端向web服务器发送一个文本的请求报文。HTTP请求报文由3部分组成(请求行+请求头+请求体)
3.服务器接收请求并返回HTTP响应
web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。响应头由三部分组成
-
1、一个数字和文字组成的状态码,用来显示请求成功或者失败。
-
2、响应头,和请求头一样,响应头也包含许多有用的信息,比如服务器类型、日期时间、内容类型和长度等。
-
3、响应体,也就是响应报文。
4.释放连接TCP连接
若connection模式为close,则服务器主动关闭连接,客户端被动关闭连接,释放TCP连接。
若connection模式为keepalive,组该连接会保持一段时间,再改时间内可以说基础接收请求。
5.客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
举个例子
在浏览器地址栏输入URL之后会经历以下流程
1.浏览器向DNS服务器清洁解析该URL中是域名所对应的IP地址;
2.解析出ip地址之后,根据IP地址和默认端口80,和服务器建立TCP连接;
3.浏览器发出读取文件(URL中域名后面部分对应的文件)的HTTP请求,该请求报文作为TCP三次握手的第三个报文的数据发送给服务器;
4.服务器对浏览器请求做出相应,并把对应的html文本发送给浏览器;
5.释放TCP连接;
6.浏览器将该html文本解析,并显示内容
重点知识点
-
http协议是基于TCP/IP协议之上的应用层协议
-
基于请求-响应的模式
http协议规定,请求从客户端发出,最后服务器响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收请求之前不会发送响应。
-
无状态保存
HTTP是一种不保存状态,即无状态协议。http协议自身不对请求和响应之间的状态进行保存。也就是说在http这个级别,协议对于发送过的请求或响应都不做持久化处理。
使用HTTP协议,每当有新的请求发送时,就会有对应的新的响应产生。协议本身并不能保留之前的一切的请求或响应报文信息。这是为了更快的处理大量事务,确保协议的可伸缩性,而特意吧HTTP协议设计成如此简单。可是,随着web的不断发展,因无状态而导致业务处理变得棘手的情况增多了。跳转页面却任然需要保存登录状态这种情况就需要保存状态。http为无状态协议,但是为了实现这种功能就引入了cookie技术。有了cookie再使用HTTP协议,就可以管理状态了。有关cookie的讲解稍后继续。
无连接
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并受到客户的应答后,即断开连接。才用这种方式,可以节省传输时间,并且可以提高并发性,不能和每个用户建立长久的连接,请求一次响应一次,服务器和客户端连接就中断了。早期的http是请求一个相应之后直接就断开了,但是现在的http协议1.1版本不是直接断开,而是等待几秒钟,目的是等待用户的后续操作,如果用户在这几秒内有新的请求,那么还是通过之前的连接通道来收发消息,如果过了这几秒中,用户没有发送新的请求,那么就会断开连接,这样可以提高效率,减少短时间内建立连接的次数。默认3秒
七层网络模型
物理层 > 数据链路层 > 网络层 > 传输层 > 会话层 > 表示层 > 应用层
- 应用层:网络服务与最终用户的一个接口( 协议有:http,https)
- 表示层:数据的表示安全压缩(五层模型已合并到应用层)
- 会话层:建立、管理、终止会话(五层模型已合并到应用层)对应主机进程,指本地主机与远程主机正在进行的会话
- 传输层:定义传输数据的协议端口号,以及流控和差错校验。(协议有:TCP, UDP数据一旦离开网卡即进入网络传输层)
- 网络层:进行逻辑地址寻址,实现不同网络之间的路径选择。(协议有:ICMP IGMP IP(IPV4 IPV6))
- 数据链路层:建立逻辑连接,进行硬件地址寻址,差错校验等功能(由底层网络定义协议)将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正。
- 物理层:建立维护断开物理连接(由底层网络定义协议)TCP/IP层级模型结构,应用层之间的协议通过逐级调用传输层、网络层和物理数据链路层而可以实现应用层的应用程序通讯互联。
HTTP请求方法
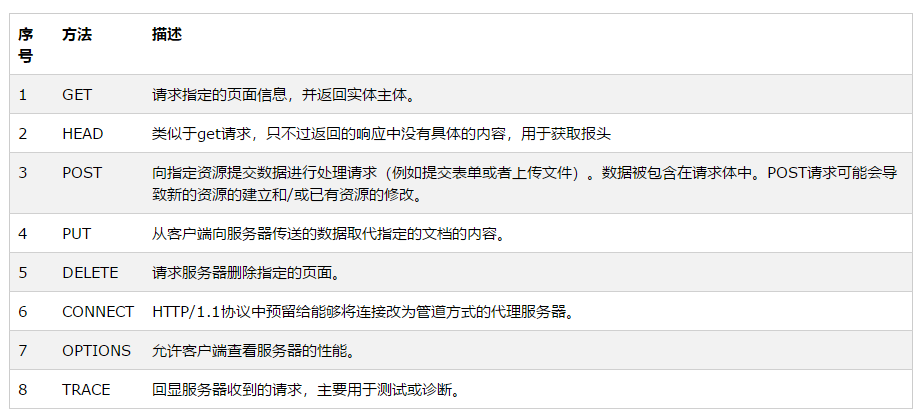
比较get和post
结论:get和post没有实质区别,只是报文格式不同
get - 从指定的资源请求数据
post - 向指定的资源提交要被处理的数据
GET方法
请注意查询字符串(名称/值对)是在get请求的url中发送的
- get请求可被缓存
- get请求保存在浏览器历史记录中
- get请求可被收藏为书签
- get请求不应在处理敏感数据时使用
- get请求有长度限制
- get请求只应当用于取回数据
POST方法
请注意,查询字符串(名称/值对)是在post请求的http主体中发送的
-
post请求不会被缓存
-
post请求不会保留在浏览器历史记录中
-
post请求不能被收藏为书签
-
post请求对数据长度没有要求
post与get安全性比较
按照网上大部分文章解释,post比get安全,因为地址栏看不见。
然而从传输角度来说他们都是不安全的,因为http在网络上是明文传输的只要在网络节点上捉包,就能完整的获取数据报文。要想安全传输,就只有加密也就是https。
GET产生一个TCP数据包,POST产生两个数据包
对于get方式请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据)
而对于post,浏览器先发送header,服务器响应100continue,浏览器再发送data,服务器响应200(返回数据)
so,基于这一点三个注意
1.get与post都有自己的语义,不能随便混用。
2.据研究,在网络环境好的情况下,发一次包和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次保的TCP在验证数据包的完整性上,有非常大的优点。
3.并不是所有的浏览器都发送两次包,Firefox就只发送一次。
HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前http版本号,三位数字组成的状态码,以及描述状态的短语,彼此由空格分隔。
状态码的第一个数字代表当前响应的类型:
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
| 类别 | 原因短语 | |
|---|---|---|
| 1xx | information(信息状态码) | 接收的请求正在处理 |
| 2xx | success(成功状态码) | 请求正常,处理完毕 |
| 3xx | redirection(重定向状态码) | 需求进行附加操作已完成请求 |
| 4xx | client error(客户端错误状态码) | 服务器无法处理请求 |
| 5xx | server error(服务器错误状态码) | 服务器处理请求出错 |
URL
url = 协议 + 域名或IP + 端口号 + 路径 + 查询字符串 + 锚点
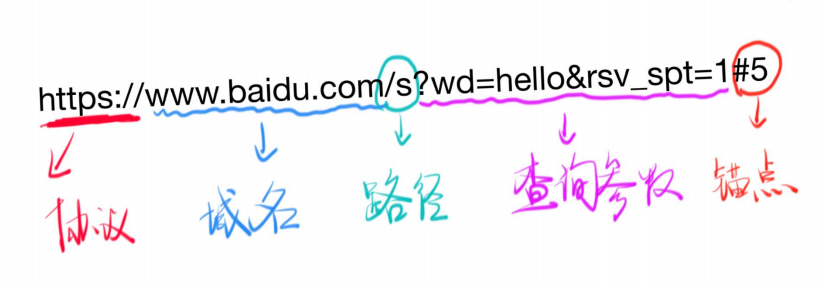
超文本传输协议(http)的统一资源定位符,将从因特网获取信息的五个基本元素,包括在一个简单的地址中;
- 路径没有必要有后缀
- URL的全称是统一资源定位符
- 锚点不支持中文,锚点不会传给服务器,无法在network面板看到
DNS
NDS就像是个翻译官,能够把baidu.com翻译成220.181.111.188 让机器理解。
DNS是用来做域名解析的,他会在你上网输入网址后,把它转换成IP,然后去访问服务器。
参考文档:https://www.cnblogs.com/weibanggang/p/9454581.html
参考文档:https://www.w3school.com.cn/tags/html_ref_httpmethods.asp
参考文档:https://www.cnblogs.com/an-wen/p/11180076.html














 1594
1594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









