







数据结构复习题
- (一)简答题
- 1.已知一棵完全二叉树共有n个节点,试求:(要求写出求解过程)
- 2.在利用链式结构(单链表、双链表、单循环链表及双循环链表)进行数据的访问中,能否从当前节点出发访问到任一节点?为什么?请给出你的分析的理由,描述出单、双链表的结构及对应的循环链表的特点。
- 3.请分析在顺序查找、折半查找、分块查找中,若查找元素时以等概论计算,这些查找方案各自的ASL为多少?给出结论及求解过程。
- 4.对于n个顶点的无向图和有向图(均为不带权图),当采用邻接矩阵和邻接表表示时,如何求解以下问题:
- 5. 一棵满二叉树,若是操作仅限于进行元素的查找(包括查找孩子结点、双亲结点、兄弟结点),最佳的存储方案是?说明理由。
- 6.在直接插入排序、希尔排序、冒泡排序、简单选择排序、快速排序、堆排序和基数排序方法中
- 7.将一个顺序表中所有的元素实现逆置,算法的空间复杂度尽量保持为O(1),请用文字描述出你的方案。
- 8.含有n个结点的3叉树的最小高度是多少?
- 9.已知完全二叉树的第8层有8个节点,则其分支结点数是多少?(请给出求解过程)
- 10.请描述对于线性表的顺序存储和链式存储结构的优缺点。举例说明在什么样的情况下选用顺序存储,什么情况下选用链式结构存储?
- 11.试各举一个实例,简要说明栈和队列在程序设计中所起的作用。
- (二)编程题
- (三)选择题常用性质
(一)简答题
1.已知一棵完全二叉树共有n个节点,试求:(要求写出求解过程)
完全二叉树的相关公式
因为完全二叉树中,叶子结点的数量比度为二的结点的数量多1。
若总结点数为999这样的奇数,999/2 = 499.5 ,那么叶子结点就有500个,度为2的节点为499个,度为1的节点为0个。
若总结点数为1500这样的偶数,1500/2 = 750 ,那么叶子节点就有750个,度为2的节点就有749个,度为1的节点为1个
左孩子等于父节点×2,右孩子等于左孩子+1
- 树的高度;
[logn]+1(中括号代表取整) - 叶子节点数;

- 单支节点数
0或者1个。
假设N0=a个(叶子节点),N1=b个(只有可能为0或1),N2=c个(双分支节点),N0=N2+1,N=N0+N1+N2;
式中,N1为单支节点数,N为节点总数。 - 第3层第3个结点的编号,以及它的孩子结点的编号为什么?(默认根结点的编号为1)。
答:第三层第一个是2的n-1次方,即=4,那么第三个等于6.左孩子为2n=12,右孩子为2n+1=13;
2.在利用链式结构(单链表、双链表、单循环链表及双循环链表)进行数据的访问中,能否从当前节点出发访问到任一节点?为什么?请给出你的分析的理由,描述出单、双链表的结构及对应的循环链表的特点。
答:单链表不行,其他都可以。因为单链表是单向的,每个节点的指针指向的是下一个节点,没有指向前驱的指针而无法访问前驱节点。所以从任意节点出发,只能访问该节点的下一节点。
3.请分析在顺序查找、折半查找、分块查找中,若查找元素时以等概论计算,这些查找方案各自的ASL为多少?给出结论及求解过程。
答:log2的b+1次方-1+(s+1)/2
ASL(关键字的平均比较次数)

-
对于顺序查找:1/n*(1+2+3+…+n)=(n+1)/2.
-
对于折半查找:将所要查找的序列,放入一棵树,那么总的查找次数就是每一层的节点数乘以第几层。
-
第i层的节点个数为2的i-1次方,那么该层的查找次数为i.将i从1求和到n 最后答案为log2的n+1次方-1。
-
对于分块查找,通过折半查找查找索引表,然后再通过顺序查找。 一共n个元素,每个块s个,那么有n/s块=b。
4.对于n个顶点的无向图和有向图(均为不带权图),当采用邻接矩阵和邻接表表示时,如何求解以下问题:
-
图中有多少条边;
答:①对于邻接矩阵表示的无向图,图的边数等于邻接矩阵数组中为1的元素个数除以2;
②对于邻接表表示的无向图,图中的边数等于边结点的个数除以2;
③对于邻接矩阵表示的有向图,图中的边数等于邻接矩阵数组中为1的元素个数;
④对于邻接表表示的有向图,图中的边数等于边结点的个数; -
任意两个顶点之间i和j是否有边相连;
答:①对于邻接矩阵g表示的无向图,邻接矩阵数组元素g。Edges[i][j]为1表示它们有边相连。
② 如果邻接矩阵g表示的有向图,Edges[i][j]为1表示i到j有边相连。Edges[j][i]表示j到i有边相连。
③对于邻接表表示的无向图G,如果G->adjlist[i]的单链表中找到编号为j的边节点,表示它们有边相连;否则为无边相连。
④对于邻接表G表示的有向图G,如果G->adjlist[i]的单链表中找到编号为j的边节点,则i与j相连。如果G->adjlist[j]的单链表中找到编号为i的边节点,表示j到i有边。 -
任意一个顶点的度是多少。
①对于邻接矩阵表示的无向图,顶点i对应的度是第i行元素为1的个数;
②对于邻接矩阵表示的有向图,顶点i对应的出度是第i行元素为1的个数,入度是第i列对应的元素为1的个数。
③对于邻接表G表示的无向图,顶点i对应的度,是G->adjlist[i]为头节点的单链表中边节点的个数;
④对于邻接表G表示有向图,顶点i对应的出度,是G->adjlist[i]为头节点的单链表中边节点的个数。入度需要遍历所有边节点,若G->adjlist[j]为头结点的单链表中存在编号为i的边节点,则顶点i的入度增加1,顶点i的度等于入度和出度之和。
5. 一棵满二叉树,若是操作仅限于进行元素的查找(包括查找孩子结点、双亲结点、兄弟结点),最佳的存储方案是?说明理由。
顺序表存储,用顺序表存储利用率是100%。用顺序表可以方便查到子节点,父节点和兄弟节点。查兄弟节点就将index加一或减一。父节点=index/2,左孩子节点为index *2,右孩子节点为index *2+1.
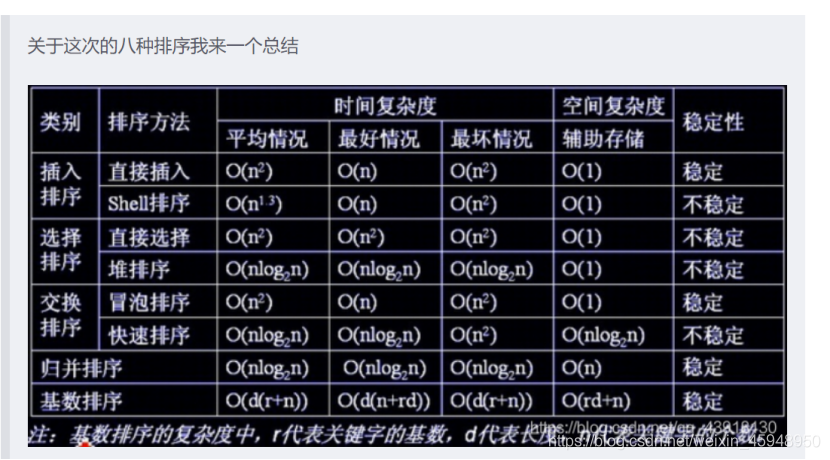
6.在直接插入排序、希尔排序、冒泡排序、简单选择排序、快速排序、堆排序和基数排序方法中
- 不需要进行关键字比较的是哪些?
答:基数排序 - 关键字比较的次数与记录的初始排列次序无关的是哪些?
答:选择排序 - 上面各种排序算法的平均时间效率分别为什么?
一般取最坏时间复杂度或平均情况为平均时间复杂度。希尔排序的平均时间复杂度是O(n^1.3)。
7.将一个顺序表中所有的元素实现逆置,算法的空间复杂度尽量保持为O(1),请用文字描述出你的方案。
扫描顺序表中的前半部分,即N/2个元素,然后将这些元素,与后半部分对应的元素交换位置。对于L.data[i]与后面的L.data[L.length-i-1]交换。
8.含有n个结点的3叉树的最小高度是多少?
答:二叉树具有n个结点的m次树的最小高度: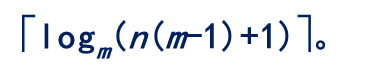
9.已知完全二叉树的第8层有8个节点,则其分支结点数是多少?(请给出求解过程)
答:如果第8层不是最底层,那么第8层的节点数为2的7次方,显然是大于8,所以,第8层是最底层。因为是完全二叉树,所以第7层的叶子节点个数为2的7次方减去8/2.然后求出总的节点区,减去叶子节点数。
10.请描述对于线性表的顺序存储和链式存储结构的优缺点。举例说明在什么样的情况下选用顺序存储,什么情况下选用链式结构存储?
答:①空间的比较:顺序表开辟的是一段连续的空间,然后进行数据的增删改查。而单链表则是一次开辟一个节点的空间,用来存储当前的数据和指向下一个节点的指针。
②时间的比较:访问顺序表中的元素,采用下标进行访问,时间复杂度为O(1),而访问链表中的某一元素,需要遍历整个链表,直到找到元素为止。因此单链表的平均时间复杂度为O(n)。
但是在删除和插入元素时,因为顺序表是连续的,所以需要把被删除或插入的元素后面的元素全部后移或者前移,时间花销很大。而单链表在插入或删除元素时,只需要改变前驱节点的指针就可以了。因此顺序表插入删除元素的平均时间为0(n),而链表的时间复杂度为O(1)。
使用情况:
查询操作使用的比较频繁时,使用顺序表会好一些;在插入、删除操作使用的比较频繁时,使用单链表会好一些。
11.试各举一个实例,简要说明栈和队列在程序设计中所起的作用。
答:栈的特点是后进先出,所以在解决实际问题涉及到后进先出的情况时,可以考虑使用栈。例如:表达式的括号配对问题。设置一个栈,将读到的左括号入栈,每读入一个右括号,判断栈顶是否为左括号,若是,则出栈;否则,表示不匹配。
** 队列的特点是先进后出**。例如:在电商秒杀的场景中,许多请求发送到后台系统中,无数线程同时运行。如果最终的结果是要处理每一个请求,那么就将请求进行先后次序排序,输入到队列中,先输入的请求就先处理,凡是需要处理的请求都从队尾进入。
(二)编程题
1.能写出顺序表、单链表、双链表、单循环链表、双循环链表、顺序栈、顺序队、链栈、链队的结构体。
1.顺序表:
Typedef struct {
Elemtype data[maxsize];
int length;
}Sqlist;
2.单链表:
Typedef struct Lnode{
Elemtype data;
Struct Lnode *next;
} Linknode;
3.双链表:
Typedef struct Lnode{
Elemtype data;
Struct Lnode *prior;
Struct Lnode *next;
}Dlinknode;
4.单循环链表:
Typedef struct node{
ListData data;
struct node* link;
}ListNode, *ListLink;
5.顺序栈:
Typedef struct {
Elemtype data;
Int top;
}Sqstack;
6.链栈:
Typedef struct linkNode{
Elemtype data;
Struct linknode * next;
}LinkStnode;
7.顺序队:
Tyedef struct {
Elemtype data[Maxsize];
Int front,rear;
}Sqque;
8.链队:
Typedef struct qnode{
Elemtype data;
Struct qnode *next;
}Datanode;
9.双循环链表
双向链表的每个结点需要连接前一个结点和后一个结点,所以需要定义两个指针域,分别指向前一个结点和后一个结点。
typedef struct tagNode
{
int data;
struct tagNode *pre,*next;
}Node,*LinkList;
2.写出折半查找的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
typedef int KeyType;//定义关键字类型为int
typedef struct
{
KeyType key;//关键字项
InfoType data;//其他数据项,类型为InfoType
}RecType; //查找元素的类型
int BinSearch(RecType R[], int n, KeyType k)//折半查找算法
{
int low=0,high=n-1,mid;//当前区间存在元素时循环
while (low<=high)
{
mid=(low+high)/2;
if (R[mid].key==k) //查找成功返回
return mid+1;
if (R[mid].key>k) //继续在R[low..mid-1]中查找
high=mid-1;
else
low=mid+1; //继续在R[mid+1..high]中查找
}
return 0;
}
最好时间复杂度:
最坏时间复杂度:
平均时间复度:
3.写出分块查找的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
#include <stdio.h>
#define MAXL 100 //数据表的最大长度
#define MAXI 20 //索引表的最大长度
typedef int KeyType;
typedef char InfoType[10];
typedef struct
{
KeyType key; //KeyType为关键字的数据类型
InfoType data; //其他数据
} NodeType;
typedef NodeType SeqList[MAXL]; //顺序表类型
typedef struct
{
KeyType key; //KeyType为关键字的类型
int link; //指向对应块的起始下标
} IdxType;
typedef IdxType IDX[MAXI]; //索引表类型
int IdxSearch(IDX I,int m,SeqList R,int n,KeyType k)
{
int low=0,high=m-1,mid,i;
int b=n/m; //b为每块的记录个数
while (low<=high) //在索引表中进行二分查找,找到的位置存放在low中
{
mid=(low+high)/2;
if (I[mid].key>=k)
high=mid-1;
else
low=mid+1;
}
//应在索引表的high+1块中,再在线性表中进行顺序查找
i=I[high+1].link;
while (i<=I[high+1].link+b-1 && R[i].key!=k) i++;
if (i<=I[high+1].link+b-1)
return i+1;
else
return 0;
}
int main()
{
int i,n=25,m=5,j;
SeqList R;
IDX I= {{14,0},{34,5},{66,10},{85,15},{100,20}};
KeyType a[]= {8,14,6,9,10,22,34,18,19,31,40,38,54,66,46,71,78,68,80,85,100,94,88,96,87};
KeyType x=85;
for (i=0; i<n; i++)
R[i].key=a[i];
j=IdxSearch(I,m,R,n,x);
if (j!=0)
printf("%d是第%d个数据\n",x,j);
else
printf("未找到%d\n",x);
return 0;
}
4.写出直接插入排序的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
#include <stdio.h>
#define MaxSize 20
typedef int KeyType; //定义关键字类型
typedef char InfoType[10];
typedef struct //记录类型
{
KeyType key; //关键字项
InfoType data; //其他数据项,类型为InfoType
} RecType; //排序的记录类型定义
void InsertSort(RecType R[],int n) //对R[0..n-1]按递增有序进行直接插入排序
{
int i,j;
RecType tmp;
for (i=1; i<n; i++)
{
tmp=R[i];
j=i-1; //从右向左在有序区R[0..i-1]中找R[i]的插入位置
while (j>=0 && tmp.key<R[j].key)
{
R[j+1]=R[j]; //将关键字大于R[i].key的记录后移
j--;
}
R[j+1]=tmp; //在j+1处插入R[i]
}
}
int main()
{
int i,n=10;
RecType R[MaxSize];
KeyType a[]= {9,8,7,6,5,4,3,2,1,0};
for (i=0; i<n; i++)
R[i].key=a[i];
printf("排序前:");
for (i=0; i<n; i++)
printf("%d ",R[i].key);
printf("\n");
InsertSort(R,n);
printf("排序后:");
for (i=0; i<n; i++)
printf("%d ",R[i].key);
printf("\n");
return 0;
5.写出冒泡排序的改进算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
#include <stdio.h>
#define MaxSize 20
typedef int KeyType; //定义关键字类型
typedef char InfoType[10];
typedef struct //记录类型
{
KeyType key; //关键字项
InfoType data; //其他数据项,类型为InfoType
} RecType; //排序的记录类型定义
void BubbleSort1(RecType R[],int n)
{
int i,j,k,exchange;
RecType tmp;
for (i=0; i<n-1; i++)
{
exchange=0;
for (j=n-1; j>i; j--) //比较,找出最小关键字的记录
if (R[j].key<R[j-1].key)
{
tmp=R[j]; //R[j]与R[j-1]进行交换,将最小关键字记录前移
R[j]=R[j-1];
R[j-1]=tmp;
exchange=1;
}
printf("i=%d: ",i);
for (k=0; k<n; k++)
printf("%d ",R[k].key);
printf("\n");
if (exchange==0) //中途结束算法
return;
}
}
int main()
{
int i,n=10;
RecType R[MaxSize];
KeyType a[]= {0,1,7,2,5,4,3,6,8,9};
for (i=0; i<n; i++)
R[i].key=a[i];
printf("排序前:");
for (i=0; i<n; i++)
printf("%d ",R[i].key);
printf("\n");
BubbleSort1(R,n);
printf("排序后:");
for (i=0; i<n; i++)
printf("%d ",R[i].key);
printf("\n");
return 0;
}
6.写出希尔排序的算法,并分析其最好情况、最坏情况及平均情况下的时间复杂度。
#include <stdio.h>
#define MaxSize 20
typedef int KeyType; //定义关键字类型
typedef char InfoType[10];
typedef struct //记录类型
{
KeyType key; //关键字项
InfoType data; //其他数据项,类型为InfoType
} RecType; //排序的记录类型定义
void ShellSort(RecType R[],int n) //希尔排序算法
{
int i,j,gap;
RecType tmp;
gap=n/2; //增量置初值
while (gap>0)
{
for (i=gap; i<n; i++) //对所有相隔gap位置的所有元素组进行排序
{
tmp=R[i];
j=i-gap;
while (j>=0 && tmp.key<R[j].key)//对相隔gap位置的元素组进行排序
{
R[j+gap]=R[j];
j=j-gap;
}
R[j+gap]=tmp;
j=j-gap;
}
gap=gap/2; //减小增量
}
}
int main()
{
int i,n=11;
RecType R[MaxSize];
KeyType a[]= {16,25,12,30,47,11,23,36,9,18,31};
for (i=0; i<n; i++)
R[i].key=a[i];
printf("排序前:");
for (i=0; i<n; i++)
printf("%d ",R[i].key);
printf("\n");
ShellSort(R,n);
printf("排序后:");
for (i=0; i<n; i++)
printf("%d ",R[i].key);
printf("\n");
return 0;
}
(三)选择题常用性质
一、二叉树
1、普通树
①树中结点数等于所有节点度数+1
②度为m的数中第i层至多有m^(i-1)个节点
以上两个可以自己推
③高度为h的m叉树至多((m^h)-1)/(m-1)个节点
④具有n个节点的m叉树的最小高度为:
logm[n(m-1)+1] m是底数,向上取整
2、完全二叉树
①叶子节点数=度数为2的节点数+1
②有n个节点的完全二叉树的深度为log2(n+1) 向上取整
3、平衡二叉树
它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
二、图
1、无向图、有向图
①若有n个顶点,那么可以n(n-1)/2个无向图
②若有n个顶点,那么可以n(n-1)个有向图
③子图:点包含于原图的点;生成子图:点就是原图的点
④在无向图中,所有顶点的度的和是图中边的两倍
2、邻接矩阵(顺序存储)
所谓邻接就是点到点之间有几条边的关系,带权就写权,没有就写无穷
①无向图的边数是上三角或者下三角中非0元素的个数
②无向图的邻接矩阵是对称方阵
③对于点vi,其度数就是第i行的非零元素的个数
④有向图的邻接矩阵中,方向是行到列,也就是说,行是出度,列是入度(不为0的元素有几个,度就是几)
3、邻接表(链式存储)
①有向图的邻接表,在点后面还加了一个入度或者出度,所以有入度邻接表和出度邻接表。
请大家一起纠错,多多批评指正哦!
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











