







 本文详细介绍了DM数据库中索引的特点,包括优点(如提高检索速度,降低IO成本)和缺点(如降低增删改效率,占用空间)。文章探讨了不同类型的索引,如单值、组合、主键、唯一和全文索引,并讨论了如何根据需求创建、修改和删除索引。此外,还提到了位图连接索引在数据仓库中的应用。创建索引的原则包括在经常用于查询、连接、排序和范围搜索的列上创建,但要注意避免索引失效的情况,如LIKE查询以%开头、违背最左匹配原则、使用函数和全表扫描更优的情况。
本文详细介绍了DM数据库中索引的特点,包括优点(如提高检索速度,降低IO成本)和缺点(如降低增删改效率,占用空间)。文章探讨了不同类型的索引,如单值、组合、主键、唯一和全文索引,并讨论了如何根据需求创建、修改和删除索引。此外,还提到了位图连接索引在数据仓库中的应用。创建索引的原则包括在经常用于查询、连接、排序和范围搜索的列上创建,但要注意避免索引失效的情况,如LIKE查询以%开头、违背最左匹配原则、使用函数和全表扫描更优的情况。
索引,是建立在数据库中的用于快速查询,快速定位与检索数据的数据结构。索引表是一组数据的集合,它将数据按照一定规则组织起来,形成一个可操作的整体,是对大量数据进行有效组织和管理的手段之一。
特点介绍
利用DM 数据库,我们可以验证与得出一系列索引相关特点,包括优缺点,类型等。
优点
- 检索速度快,大大减少了检索数据所需的数据量,降低数据库IO成本(这是建立索引最主要的原因)
示例:- 我们先创建一个包含三个整型的表,然后添加10000条随机生成的行:

- 进行一次数据检索:

耗时4ms:
- 随后创建唯一索引(当然也可以插入数据之前就创建,这点之后会讲),因为c3唯一,所以以c3为唯一索引:


- 随后搜索同样条件的列,但是筛选条件的顺序需要改一改(涉及到查询优化,之后也会讲):
耗时1ms
- 可以看到,使用索引情况下,通过适当优化可以大大加快检索的速度,降低IO成本(数据存储在磁盘等设备,查询的量减少,IO成本降低),这也是建立索引最重要的目的。
- 我们先创建一个包含三个整型的表,然后添加10000条随机生成的行:
-
索引建的好还可以简化很多操作,比如连接操作时使用索引连接。连接操作主要有嵌套连接、哈希连接、索引连接等,在建立合适的索引的情况下可以大大提高连接效率。
-
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。(被索引的列会自动进行排序,对应order by语句效率更高)
以上文例子为例,将c3进行排序:
没有索引时:
创建索引时:
缺点
当然,索引的存在也有缺点与代价:
-
在增删改场合更多的场景下,因为需要动态维护,反而可能降低效率
以插入为例:- 以上表为基础,这次我们随机生成100000行的数据并插入,在没有创建索引的情况下:
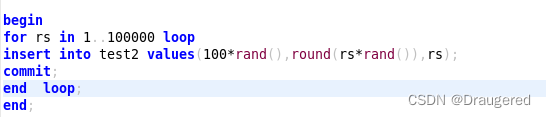
时间为23s417ms:
- 之后,我们创建一个索引,随后再插入数据:
先清空表:
删除之前的索引再重新创建:
再插入数据:
花费24s381ms - 发现花费时间多了快1s,之所以不大是因为在实际运用中,数据的数量、列的数量与类型、索引的数量都要比上述例子的规模大得多,复杂得多。
- 如果我们扩大规模,新增两个字符串列,将插入的数据数量增加到300000,同时改为聚簇唯一索引,新增一个复合索引:
未建立索引情况下时间:
建立索引的情况下:
经过多次尝试,后者相比前者平均多了2.5s 。
- 以上表为基础,这次我们随机生成100000行的数据并插入,在没有创建索引的情况下:
-
占用空间,特别是聚簇索引,占用很大的空间。聚簇索引,就是索引节点即包含了该数据项的全部信息,相比非聚簇索引需要占用更多的空间。
-
建立非聚簇索引并插入相同数量的数据,根据suo查看索引占用的空间:
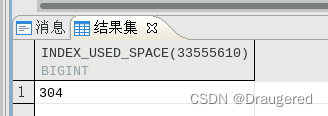
-
再建立聚簇索引,根据索引ID查看占用索引空间:

-
-
创建了索引之后,遇到数据的增删改时候,也要进行相应维护,所以维护需要占用额外的时间。
在第一点中,如果我们选择先插入数据再建立索引,那么索引在创建的时候,就需要花费更多时间,随数据的增大而增大。-
在100000行已有数据的情况下建立聚簇唯一索引,花费217ms:
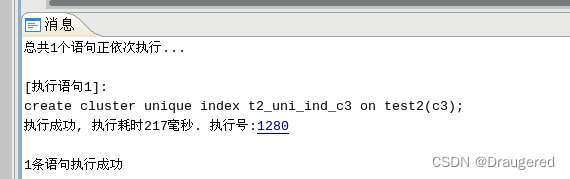
-
在200000行已有数据的情况下建立聚簇唯一索引,花费394ms:
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









