







对于Inndb来说,判断是否是聚簇索引,看B+树是否存放完整的数据就行。
对于MyISAM来说,全部都是非聚簇索引,即二级索引。因为它的所有和树是分开的。
注意:下面都是针对InnoDB
聚簇索引:所有完整的用户记录都存放在B+树(索引)的叶子结点上
对于InnoDB来说,索引即数据,数据即索引。如何理解?
因为InnoDB根据索引的顺序对用户数据(MySQL表每一行完整的数据)进行排列,组织成为一个B+树,而这个B+也是实际存储用户完整数据的方式。
如果有设置主键,那么主键索引就是聚簇索引。如果没有主键,那么也会隐藏生成一个作为row_id。
非聚簇索引:非聚簇索引也叫做二级索引,因为它们存的都是主键值,不存完整用户数据。
除了主键索引之外,其他普通索引,唯一索引,联合索引等等都是属于二级索引。
所以,所以每次根据所以找到对应的主键值,在到聚簇索引中找到对应的数据行,这个过程也称为回表。
当然,回表操作肯定很耗时间,那么如何避免呢,可以用到聚簇索引。即索引的数据就包含了你要的数据,所以你也不需要回表了。
比如建立联合索引 index(c1,c2,c3),如果你只需要 select c1 那么你肯定不需要回表了。
前面介绍了两种索引,那么索引是怎么组织的呢?轮到B+树主角登场了。
B+树
MySQL的B+树是个"矮矮的大胖子",利用B+树可以快速定位到想要的数据,并且B+树层数一般不超过4层。
B+树其实就是多层级目录,叶子结点存放知识的数据,h减抗i下哦
要想了解B+树,就要先从数据页说起了。
数据页
MySQL中以页为最小存储单位,每次读取到内存一个或多个页,页一般大小是16KB。
当然,根据不同用途可分为很多类型,比如有FIL_PAGE_UNDO_LOG(undo日志页)、FIL_PAGE_INDEX(索引页,也就是我们的主角数据页,我们把存放记录的页叫做数据页)。
B+树的每个结点对应一个数据页。
当我们插入一条数据时,insert into page_demo values(1,100,'aaa'),对应的结构如下。
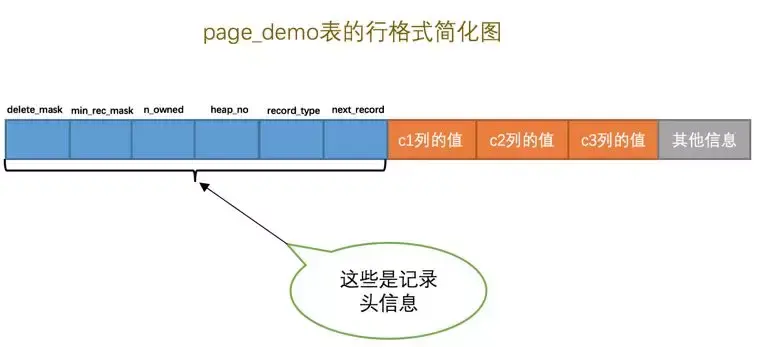
- next_record:就是下一条记录的指针,按主键顺序排列。
- record_type:当前记录的类型,一共4种类型,0表示普通记录,1表示B+树非叶子结点的目录下记录,2表示Infimum记录,3表示Supremum记录。
Infimum记录的是页面的最小记录,Supremum记录的是页面最大记录,当然,他们都不存储主键值,他们也因此成为虚拟记录。 - heap_no:InnoDB把User Record记录的机构成为堆,为了方便管理,把每一条记录在堆中的相对位置称为heap_no
- n_owned:表示该组内共有几条记录。(后面介绍)
- min_rec_mark:顾名思义,标记是否时最小记录。B+树中每层非叶子结点的最小记录项都会添加该标记。
- delete_mark:就是一个删除标记,当我们删除一条记录的时候,只需改变这个标记位即可,同时,把他的next_record指针置空。
这样做可以减少性能消耗,也方便了后面复用。但是,后面如何找到这块区域呢,删掉的记录会组成一个垃圾列表,记录在这个链表的空间成为可重用空间。
于是,当插入多条数据的时候,就变成下面的结构。
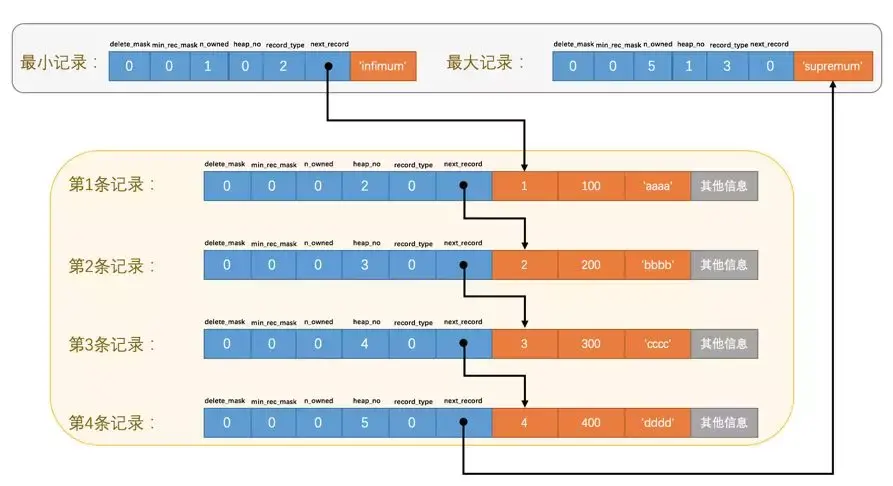
如何进行查找指定数据?
- 但是现在.如果要想找到主键值为3的记录,你是不是只能从第一条记录
Infimum开始遍历链表。于是我们,可以对这些记录进行分组。 - 我们把1和2分成一组,3和4分成一组,并把每组最大的主键值就叫做认作”大哥“,它的
n_owned就记录当前组有多少人。同组的其他”小弟“的n_owned就为0 - 将每组最后一条记录的地址偏移量按顺序放到靠近页尾的地方,这个地方就是Page Directory(页目录),也叫做槽(Slot),每个占两字节。页目录就是由多个槽组成。
注意每个分组的记录数也是有规定的,Infimum所在的分组只有有一条记录,Supremum所在的分组只能有1~8条记录,其他分组只能4-8条之间。
这样子,我们是不是就可以根据槽,按照二分法快速定位到想要的行记录。

另外,每个数据页存储的内容也是有些的,所以需要多张这样的数据页,并且也不可能一次分配比较大的存储空间,所以每个页之间就用双向链表连接起来。用FIL_PAGE_PREV和FIL_PAGE_NEXT指针。
Page Header(页面头部)
记录数据页的各种状态信息,比如页里有多少条记录,有多少个槽。
File Header(文件头部)
描述了各种通用数据页的信息,比如该页的校验和(checksum),LSN(Log Sequence Number,日志序列号)
FILE TRAILER(文件尾部)
InnoDB存储引擎会把数据存储到磁盘,但磁盘速度太慢,所以需要以页为单位加载到内存中。如果页中的数据被修改了,那么还需要把数据刷新到磁盘中。如果刷新的时候断电了怎么办,岂不是很尴尬。于是在文件尾部加了File Trailer部分,共8个字节,分为2个部分
前4字节代表校验和。这个部分与File Header的校验和相对应,每个页面刷新前就先把校验和写到File Header中,并先刷新到磁盘中,完全写完后,再写到页尾。这样有出错比对页头页尾就知道了。
总结
InnDB会把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放再 Page Directory 中,一个槽占用2个字节。在一个页中根据主键查找记录是非常快,分为两步。
- 通过二分法确定该记录所在的槽,并找到该槽中所在分组主键最小的那条记录。
- 通过记录的 next_record 属性遍历该槽所在的组中的各个记录。
每个数据页的 File Header 部分都有上一页和下一页的编号,所有的数据页都会组成一个双向链表。
在将页从内存中刷新到磁盘时,为了保证页的完整性,页首和页尾都会存储页中数据的校验和,以及页面最后修改时对应的 LSN 值。如果页首和页尾的校验和以及 LSN 值校验不成功,说明刷新期间出了问题。
这也是当作我的学习笔记,有什么纰漏的地方,欢迎大家一起交流指正,大家一起进步。















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









