






以下操作先切换到root用户下面
关闭防火墙
** 查看防火墙状态命令**
systemctl status firewalld
** 关闭防火墙**
systemctl stop firewalld
** 开机禁用防火墙**
systemctl disable firewalld
windows下的防火墙也要关闭
修改静态ip
1.修改ens33文件
1.1打开文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
1.2添加以下内容
IPADDR=192.168.1.101
NETMASK=255.255.255.0
GATEWAY=192.168.1.2
DNS1=114.114.114.114
DNS2=8.8.8.8
1.3修改成static
BOOTPROTO="static"

(2)修改linux下网络配置信息




(3)修改windows下面的网路配置信息


每台虚拟机都要修改静态ip,不要忘了重启网络哦
== *==
重启网络的命令
service network restart
修改主机名字
hostnamectl set-hostname master
修改静态ip,不要忘了重启网络哦
以上操作弄完,虚拟机关机重启即可
创建普通用户
如果你已经有了,就不用创建
useradd hadoop
修改普通用户的密码
passwd hadoop

给普通用户root权限
1.进入到root用户下面
su root
2.进入到/etc/sudoers下面
vim /etc/sudoers
3.在里面添加一下内容
注意:要是有了 root ALL=(ALL) ALL 就不用添加,只添加后面的就好了
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL

配置网络地址与主机名的对应关系
1.进入到 /etc/hosts
vim /etc/hosts
2.在最后,添加以下内容
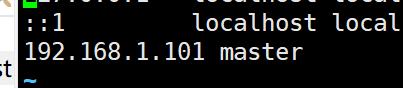
IP地址1 主机名1
IP地址2 主机名2
IP地址3 主机名
如:
java的安装和测试
1.创建文件夹java

2.利用xftp把tar包上传到/data/java下面


3.把压缩包解压到 /usr/local/lib下面
sudo tar -zxvf ./jdk-8u212-linux-x64.tar.gz -C /usr/local/lib
如何查看已经解压成功


4.编辑环境变量
cd ~
打开~/.bashrc文件
vim ~/.bashrc
在文件里面添加
export JAVA_HOME=/usr/local/lib/jdk1.8.0_212
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
5.生效配置的环境变量文件
source ~/.bashrc
6.Java环境测试
java -version

安装hadoop
进入apache官网,查看hadoop的版本,下载tar包(这里使用的是2.7.2版本)
也可以进入国内开源镜像网站下载tar包
上传hadoop包



解压hadoop包
1.解压hadoop包到 /usr/local里面
sudo tar -zxf hadoop-2.7.7.tar.gz -C /usr/local

2.进入到 /usr/local里面,修改名字为hadoop
cd /usr/local/
sudo mv ./hadoop-2.7.7/ ./hadoop

3.授权当前用户hadoop拥有该文件夹的所有者权限。
sudo chown -R hadoop:hadoop ./hadoop

本地安装后的测试,这里利用单词计数
1.创建文本wc.txt
touch wc.txt
2.编辑文本
vim wc.txt
内容如下
hadoop
java is good
hadoop
hadoop
hadoop
java
hadoop
hello wold

3.执行单词计数的命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /usr/local/hadoop/wc.txt wcout

4.查看是否生成文件

5.查看单词的个数

测试完成后,查看以下链接配置伪分布式
https://blog.csdn.net/weixin_45955039/article/details/120921026















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









