






内容简介
纪念毕设,同时弥补了上个遗传算法的漏洞,虽然这次没有优化遗传算法的性能,但是遗传算法的思想和功能表现出来了。毕设做的是多起送点,多目标的配送路线优化,硬时间窗,三种货物或以下。目标函数追求:1总体花费时间最短,2总的发车价格、油费与冷藏车电费最少,1与2之间有权值并可以更改。
代码可更改的范围较大,在此说明:需求点与起送点可以自己确定,也可以依靠下方代码收集;目标函数可更改,在代码前提供了参数的设定,两目标之间的权值可更改,也可以舍弃其中一些目标追求,比如不想要发车价格最少这一追求,把发车价格调整为0即可,不想要电费,将电费调整为0即可;油费单价、电费单价可更改;车辆载重可更改;每个需求点的服务时间可更改;工作的起始时间可更改,若设置为None,那么计划车辆在第一个需求点的最早服务时间到达;时间成本可更改,在代码中有说明。
遗传算法是手撸的,性能不好,每次结果不一定一样,需要迭代比较多的次数才能获得更好的结果。
谨此留念。
1)首先,获取需求地址及相关信息
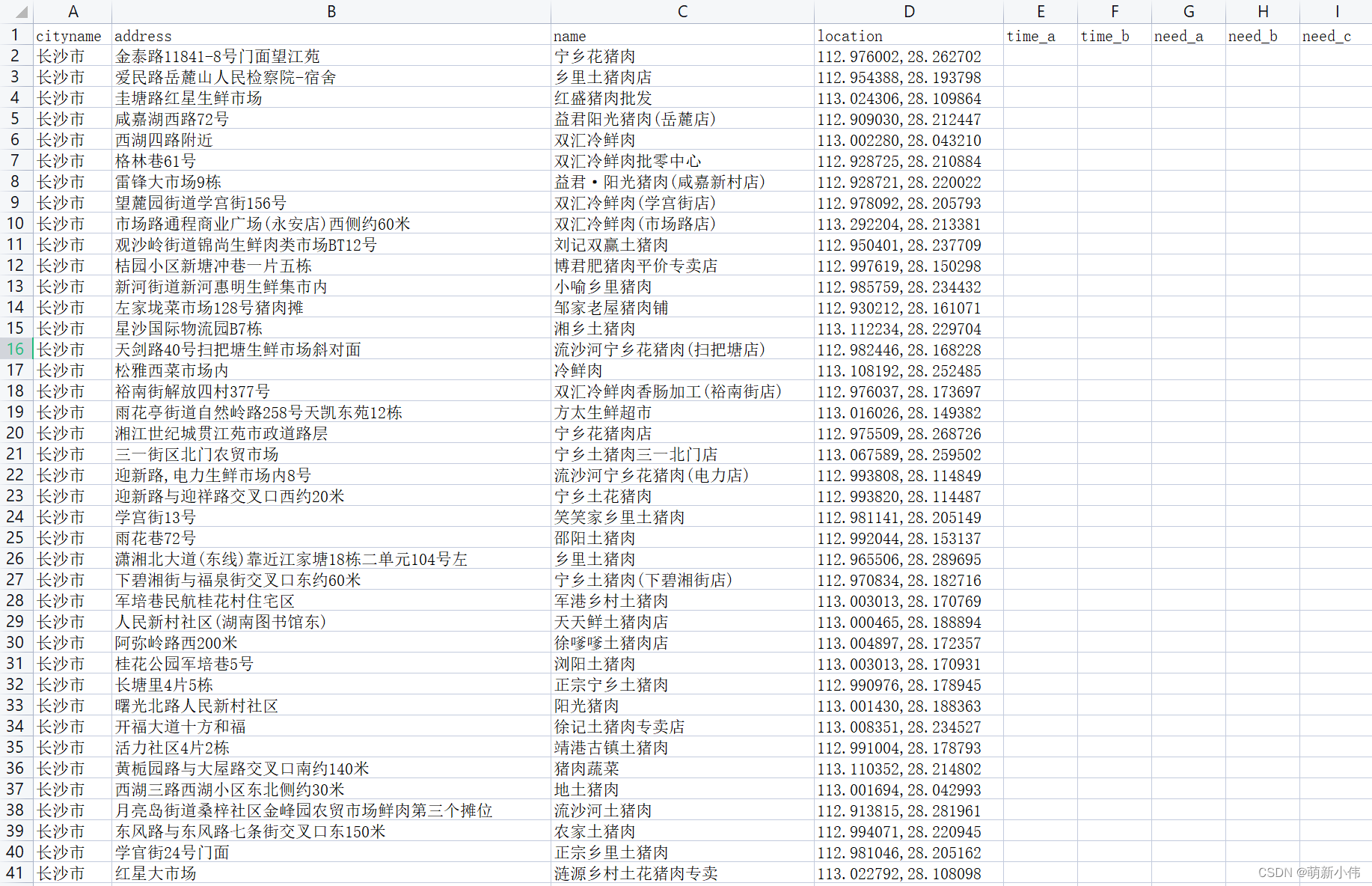
利用python的一些模块和高德API,如代码的最后,获取到了长沙市,与猪肉相关的地址信息,type类型为农副产品市场(这个type是高德API规定的,如果不了解但是想使用这段代码,这个参数就写空字符:‘’)。
使用代码告知:这段代码针对的是没有需求点信息而想要获取需求点信息的朋友,如果你的手上已经有需求点信息,就可以自己编辑excel文件,不过需要注意,数据格式需要如下方图片一致,其中location一定要正确,他指的是经纬度,后面要使用,可以自己查询。如果使用代码,代码中有两行api_url,其中有参数为:key=自己的key,这里的key需要自己去高德API官网申请,很容易得到。还有倒数第六行中保存文件的路径需要更改为自己想要的路径,f’C:\Users\86909\Desktop\{name}.xlsx这是我的桌面路径。改C:\Users\86909\Desktop这一部分就可以。最后三行中,第一行是获取你想要的城市的有关词句的地址信息,第三行是保存的文件名,自己根据需要改。
import json
import requests
import openpyxl
# 收集数据并返回一个数组,数组格式:(城市,地址,小区名,location)
def get_communities(city, type, key_word):
# 获得总共的数据量count和页数pages
api_url = f'https://restapi.amap.com/v3/place/text?key=自己的key&city={city}&citylimit=true&extentions=base&types={type}&keywords={key_word}&output=json'
r = requests.get(api_url)
r = r.text
jsonData = json.loads(r)
count = int(jsonData['count'])
pages = int((count / 20)) + 1
# 将数据装入一个数组
array_communities = []
for page in range(pages):
api_url = f'https://restapi.amap.com/v3/place/text?key=自己的key&city={city}&citylimit=true&extentions=base&types={type}&keywords={key_word}&page={page + 1}&output=json'
r = requests.get(api_url)
r = r.text
jsonData = json.loads(r)
communities = jsonData['pois']
for index in range(len(communities)):
array_communities.append((communities[index]['cityname'], communities[index]['address'],
communities[index]['name'], communities[index]['location']))
return array_communities
# 将数组内容写入xlsx
def write_xlsx(array_communities, name):
count = len(array_communities)
workbook_newWrite = openpyxl.Workbook()
worksheet = workbook_newWrite.create_sheet(name)
worksheet.cell(1, 1).value = 'cityname'
worksheet.cell(1, 2).value = 'address'
worksheet.cell(1, 3).value = 'name'
worksheet.cell(1, 4).value = 'location'
worksheet.cell(1, 5).value = 'time_a'
worksheet.cell(1, 6).value = 'time_b'
worksheet.cell(1, 7).value = 'need_a'
worksheet.cell(1, 8).value = 'need_b'
worksheet.cell(1, 9).value = 'need_c'
for index in range(count):
worksheet.cell(index + 2, 1).value = str(array_communities[index][0])
worksheet.cell(index + 2, 2).value = str(array_communities[index][1])
worksheet.cell(index + 2, 3).value = str(array_communities[index][2])
worksheet.cell(index + 2, 4).value = str(array_communities[index][3])
workbook_newWrite.remove(workbook_newWrite.worksheets[0])
workbook_newWrite.save(f'C:\\Users\\86909\\Desktop\\{name}.xlsx')
# 获取地址数据
arr = get_communities('长沙', '农副产品市场', '猪肉')
# 写入xlsx文件
write_xlsx(arr, '猪肉市场')
最后,在我的桌面上形成了一个excel文件,为:猪肉市场.xlsx,内容格式为:
2)获取各需求地址之间的距离和时间
同样利用高德API,获取各个需求点之间的距离和时间,并保存到上面代码形成的文件之中。
使用代码告知:代码中有一行key和两行文件路径,key用自己申请的key,如果没有使用上面的代码,自己定义的需求点信息,那么文件路径改成自己的文件路径,如果使用了上面的代码,文件路径用上面代码中形成的文件路径。
import openpyxl
import requests
import json
# 定义求距离与时间的方法,返回格式是(距离,时间)
def get_road(address_1, address_2):
api_url = f'https://restapi.amap.com/v3/direction/driving?key=自己的key&origin={address_1}&destination={address_2}'
r = requests.get(api_url)
r = r.text
jsonData = json.loads(r)['route']['paths'][0]
distance_duration = jsonData['distance'] + ',' + jsonData['duration']
return distance_duration
# 获取工作sheet
work_book = openpyxl.load_workbook('C:\\Users\\86909\\Desktop\\猪肉市场.xlsx')
work_sheet = work_book.worksheets[0]
# 创建要写入的工作表
new_sheet = work_book.create_sheet('距离与行驶时间_处理专用')
# 获取sheet最大行
rows = work_sheet.max_row
# 读取数据并且保存到字典,用数字编号
dic = {}
for i in range(rows - 1):
dic[i + 1] = str(work_sheet.cell(i + 2, 3).value) + ':' + str(work_sheet.cell(i + 2, 4).value)
# 按字典逐个处理
for i in range(1, len(dic) + 1):
list_origin = dic[i].split(':')
origin_name = list_origin[0]
origin_location = list_origin[1]
for j in range(1, len(dic) + 1):
if j <= i:
pass
else:
list_destination = dic[j].split(':')
destination_name = list_destination[0]
destination_location = list_destination[1]
list_dis_dur = get_road(origin_location, destination_location).split(',')
distance = list_dis_dur[0]
duration = list_dis_dur[1]
str_write = distance + ',' + duration
# 写入新建sheet
new_sheet.cell(i, j).value = str_write
# 保存
work_book.save('C:\\Users\\86909\\Desktop\\猪肉市场.xlsx')
内容格式为:
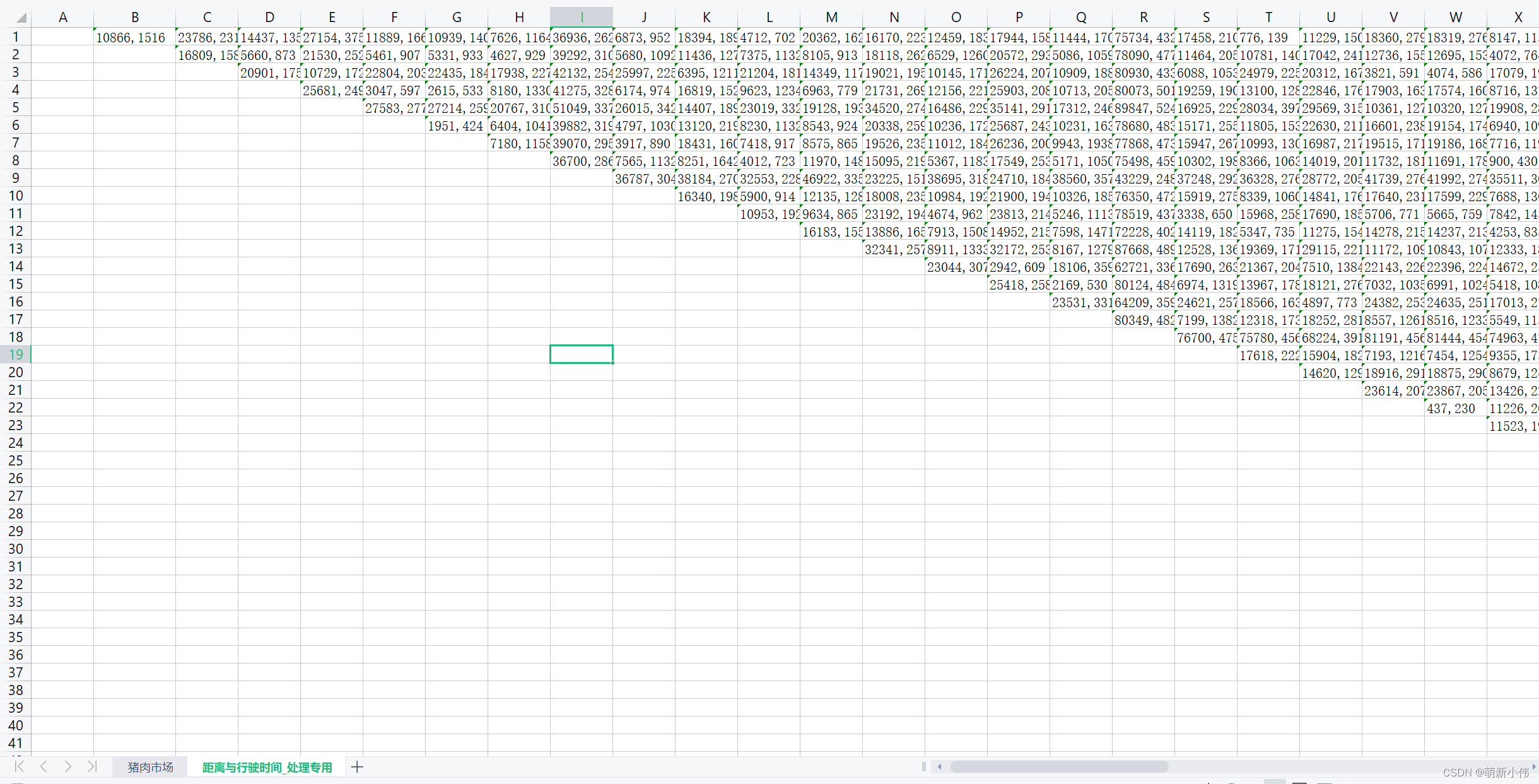
每一个单元格保留了两个内容,逗号前是两点之间的距离,单位为米,逗号之后是两点之间的预计行驶时间,单位为秒。
3)随机生成时间窗上下限,还有三种货物的需求量
因为没有具体的时间窗和货物需求量,我随机生成了时间窗和需求量,当然你可以根据自己的内容更改,不一定使用这部分代码。注意数据格式一致。
使用代码告知:代码中有两行文件路径,改成上面的文件路径。
import openpyxl
import random
# 获取小区数量
workbook = openpyxl.load_workbook('C:\\Users\\86909\\Desktop\\猪肉市场.xlsx')
worksheet = workbook.worksheets[0]
row_num = worksheet.max_row
# 每行单独处理
for i in range(1, row_num):
# 时间窗上限
time_a = random.randint(4, 14) + int(random.random() * 10) / 10
# 时间窗下限
time_b = time_a + 4 + int(random.random() * 10) / 10
# 需求量
require1 = int(random.random() + 0.6)
require2 = int(random.random() + 0.6)
require3 = int(random.random() + 0.6)
if require1 != 0:
require1 = random.randrange(20, 500)
if require2 != 0:
require2 = random.randrange(20, 500)
if require3 != 0:
require3 = random.randrange(20, 500)
# 写入每行
worksheet.cell(i + 1, 5).value = time_a
worksheet.cell(i + 1, 6).value = time_b
worksheet.cell(i + 1, 7).value = require1
worksheet.cell(i + 1, 8).value = require2
worksheet.cell(i + 1, 9).value = require3
# 保存数据
workbook.save('C:\\Users\\86909\\Desktop\\猪肉市场.xlsx')
内容格式为:
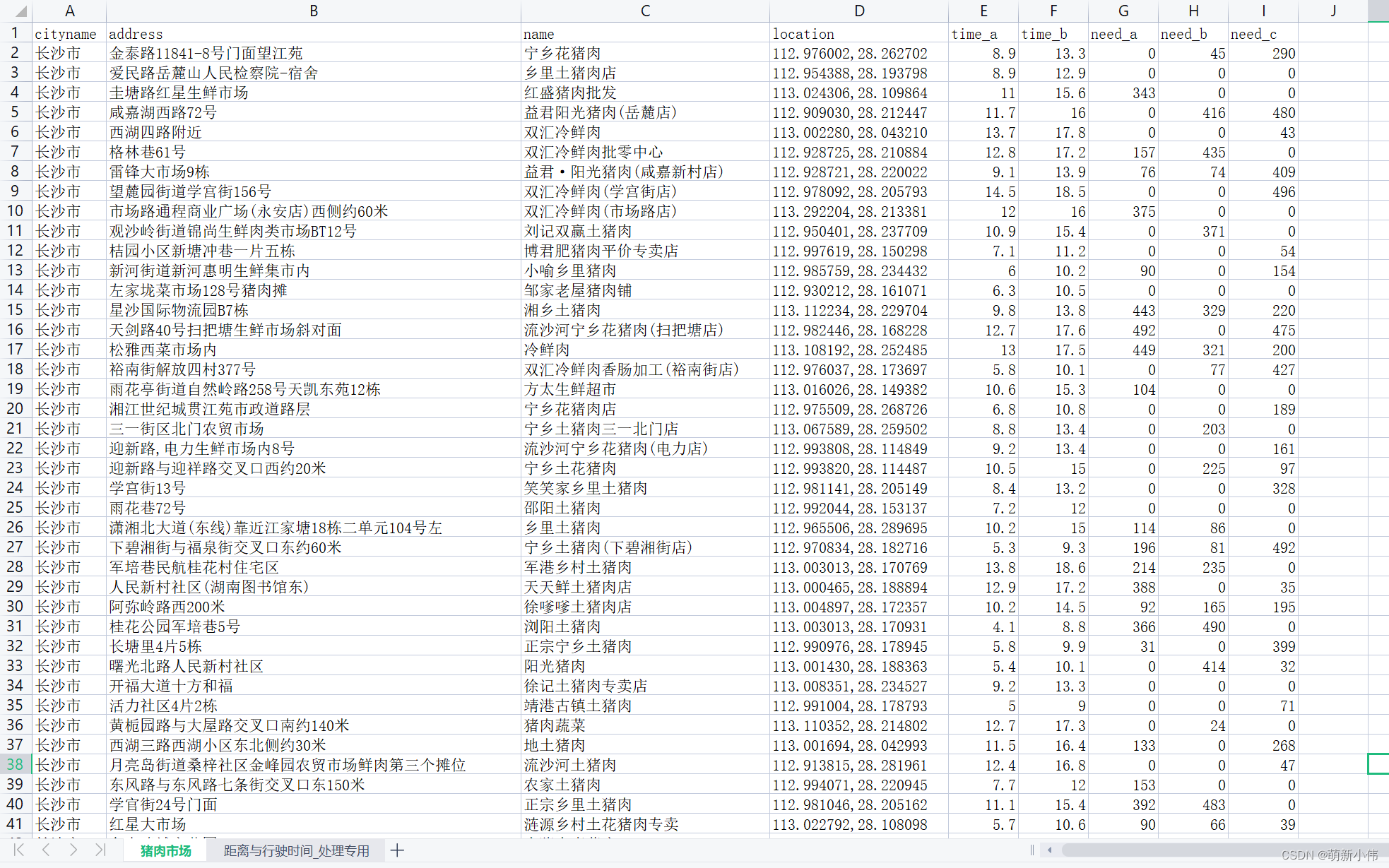
time_a表示最早到达,time_b表示最晚到达,8.9表示8点54分,need_a,need_b,need_c表示三种货物的需求量,单位为千克。
至此,需求点的信息已经收集完毕,接下来是起送点,以及起送点与需求点之间的信息
4)获取起送点的地址及相关信息
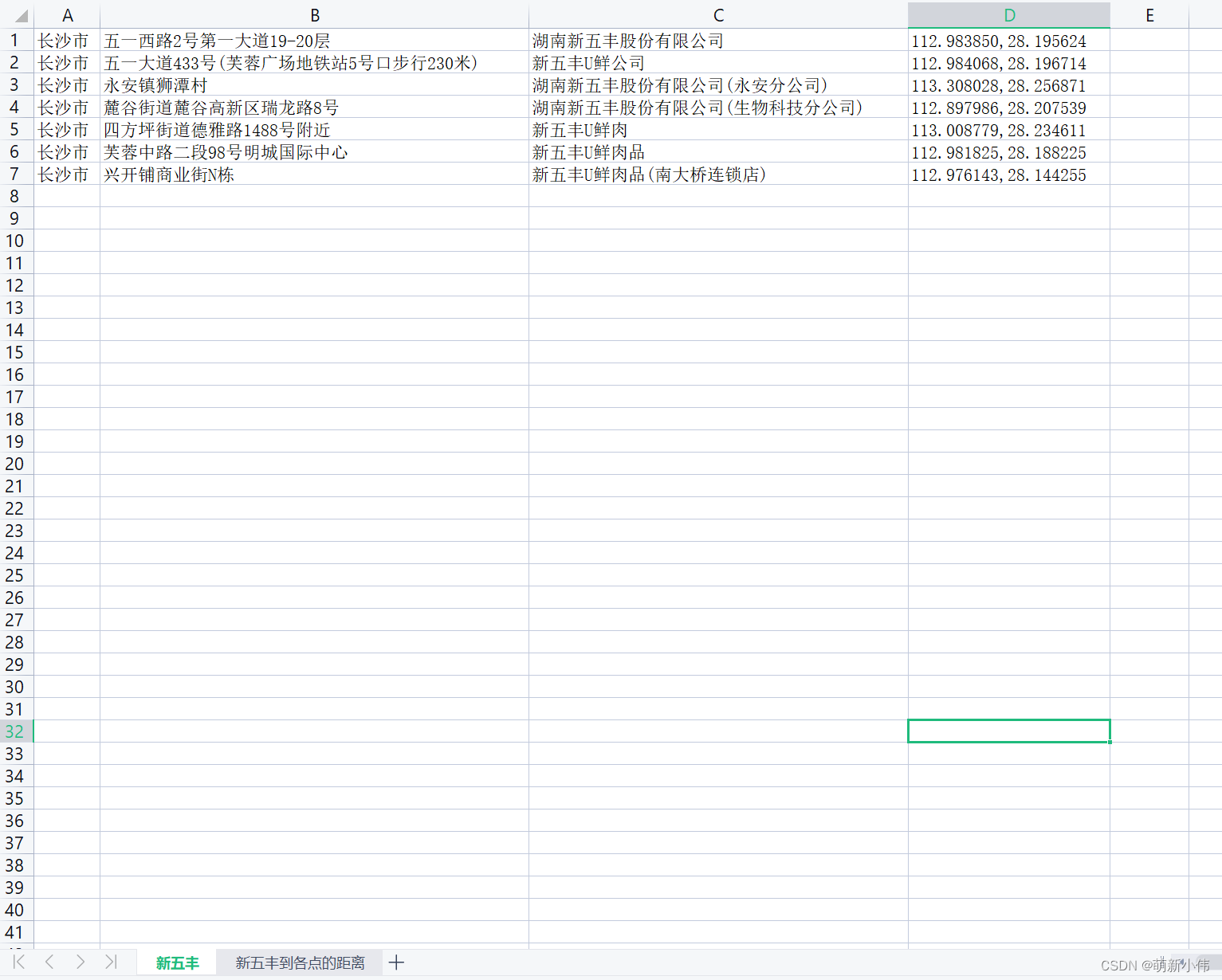
使用告知:代码中有两行key和一行文件路径,这里的文件路径是新的文件路径,是用来保存起送点数据的excel文件,注意不要和上面重复。同上,如果你有起送点的相关信息,就自己编辑,数据格式需要与下方图片一致,location一定要正确。起送点数量>=1。
import json
import requests
import openpyxl
# 收集数据并返回一个数组,数组格式:(城市,地址,小区名,location)
def get_communities(city, type, key_word):
# 获得总共的数据量count和页数pages
api_url = f'https://restapi.amap.com/v3/place/text?key=自己的key&city={city}&citylimit=true&extentions=base&types={type}&keywords={key_word}&output=json'
r = requests.get(api_url)
r = r.text
jsonData = json.loads(r)
count = int(jsonData['count'])
pages = int((count / 20)) + 1
# 将数据装入一个数组
array_communities = []
for page in range(pages):
api_url = f'https://restapi.amap.com/v3/place/text?key=自己的key&city={city}&citylimit=true&extentions=base&types={type}&keywords={key_word}&page={page + 1}&output=json'
r = requests.get(api_url)
r = r.text
jsonData = json.loads(r)
communities = jsonData['pois']
for index in range(len(communities)):
array_communities.append((communities[index]['cityname'], communities[index]['address'],
communities[index]['name'], communities[index]['location']))
return array_communities
# 将数组内容写入xlsx
def write_xlsx(array_communities, name):
count = len(array_communities)
workbook_newWrite = openpyxl.Workbook()
worksheet = workbook_newWrite.create_sheet(name)
for index in range(count):
worksheet.cell(index + 1, 1).value = str(array_communities[index][0])
worksheet.cell(index + 1, 2).value = str(array_communities[index][1])
worksheet.cell(index + 1, 3).value = str(array_communities[index][2])
worksheet.cell(index + 1, 4).value = str(array_communities[index][3])
workbook_newWrite.remove(workbook_newWrite.worksheets[0])
workbook_newWrite.save(f'C:\\Users\\86909\\Desktop\\{name}.xlsx')
# 获取小区数据
arr = get_communities('长沙', '', '新五丰')
# 写入xlsx文件
write_xlsx(arr, '新五丰')
内容格式为:
5)获取起送点到需求点之间的距离和时间
使用告知:代码中有一行key和三行文件路径,根据顺序,第一个文件路径是起送点文件,第二个文件路径是需求点即一开始的那个文件,最后一个是起送点文件,会将起送点到需求点的距离与时间保存在起送点文件中。
import openpyxl
import requests
import json
# 定义求距离与时间的方法,返回格式是(距离,时间)
def get_road(address_1, address_2):
api_url = f'https://restapi.amap.com/v3/direction/driving?key=自己的key&origin={address_1}&destination={address_2}'
r = requests.get(api_url)
r = r.text
jsonData = json.loads(r)['route']['paths'][0]
distance_duration = jsonData['distance'] + ',' + jsonData['duration']
return distance_duration
# 获取工作sheet
work_book1 = openpyxl.load_workbook('C:\\Users\\86909\\Desktop\\新五丰.xlsx')
work_book2 = openpyxl.load_workbook('C:\\Users\\86909\\Desktop\\猪肉市场.xlsx')
work_sheet_xinwufeng = work_book1.worksheets[0]
work_sheet_zhurou = work_book2.worksheets[0]
# 创建要写入的工作表
new_sheet = work_book1.create_sheet('新五丰到各点的距离')
# 获取sheet最大行
rows1 = work_sheet_xinwufeng.max_row
rows2 = work_sheet_zhurou.max_row
# 读取数据并且保存到字典,用数字编号
dic1 = {}
dic2 = {}
for i in range(1, rows1 + 1):
dic1[i] = str(work_sheet_xinwufeng.cell(i, 4).value)
for i in range(2, rows2 + 1):
dic2[i - 1] = str(work_sheet_zhurou.cell(i, 4).value)
# 按字典逐个处理
for i in range(1, len(dic1) + 1):
origin_location = dic1[i]
for j in range(1, len(dic2) + 1):
destination_location = dic2[j]
list_dis_dur = get_road(origin_location, destination_location).split(',')
distance = list_dis_dur[0]
duration = list_dis_dur[1]
str_write = distance + ',' + duration
# 写入新建sheet
new_sheet.cell(i, j).value = str_write
# 保存
work_book1.save('C:\\Users\\86909\\Desktop\\新五丰.xlsx')
内容格式为:
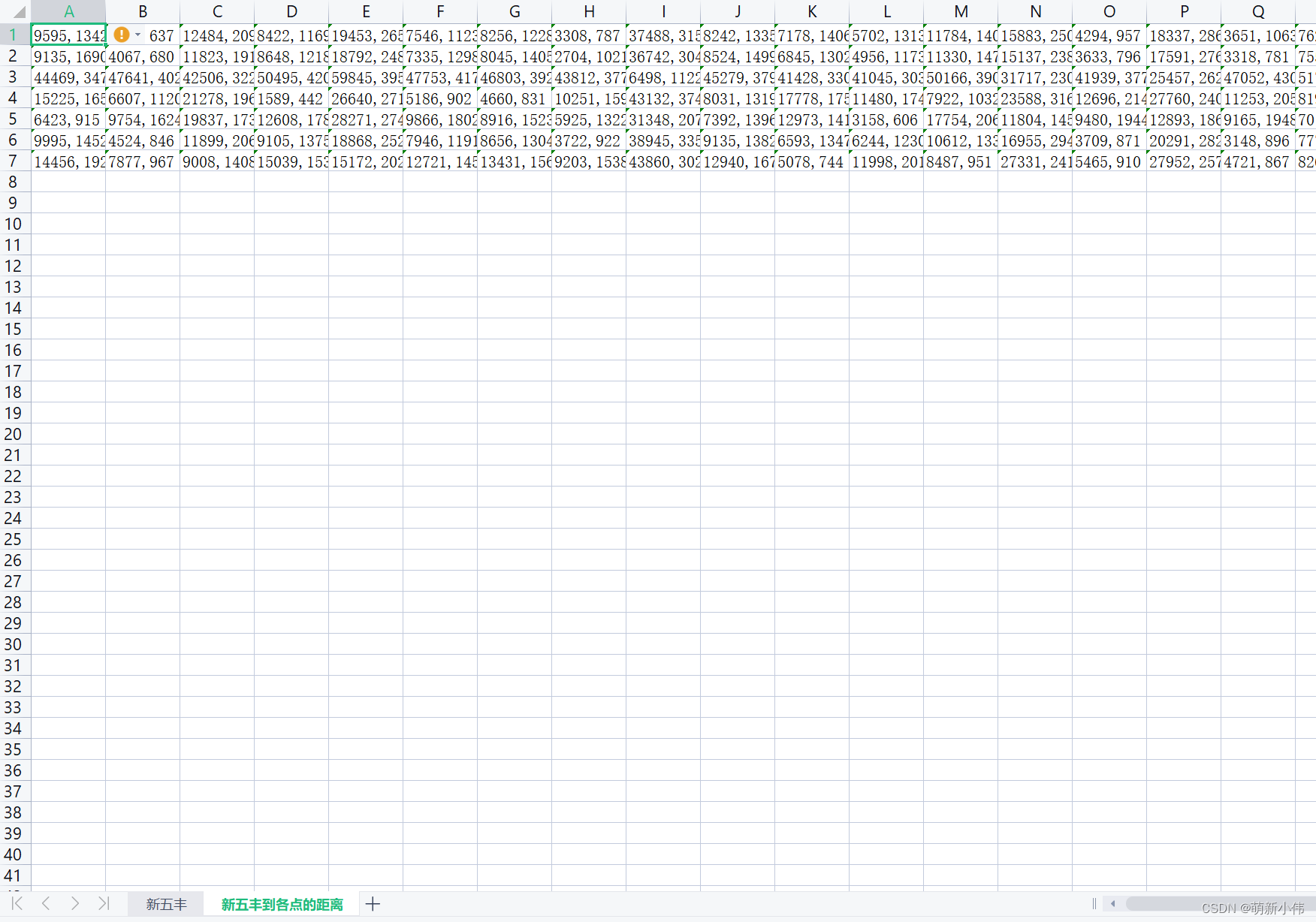
逗号前是距离,单位为米,逗号后是预计行驶时间,单位为秒。
信息收集完毕,开始遗传算法
6)遗传算法
我将分成几段展示,但都属于一个py文件,复制使用时记得按顺序放到一起
A)前文,一些可更改的参数,根据需要自己改
from time import sleep
import openpyxl
import random
import matplotlib.pyplot as plt
# 预先设置的参数======这些数都可以按照注释自定义===================
# 车辆发车单价,单位:元
price = 300
# 时间成本,用来权衡最小成本和最高时效的量级,将时间追求转化为成本追求,单位是:元/小时
tprice = 300
# 权重,目标模型是:(1-w) * 时间最短 + w * 成本最低
w = 0.7
# 车辆装载能力(kg)
can = 3000
# 单位千克鲜肉(need_a)、冷却肉(need_b)、冷冻肉(need_c)每小时对应所耗费的电费
x1 = 0.01
x2 = 0.02
x3 = 0.05
# 每米所耗油费
oil = 0.001686
# 服务单个点的时间,单位:秒
serve_time = 360
# 超市驾驶员上班时间,如果上班时间没有固定,即满足最早到达第一个点的最早时间窗,那就设置为None
work_start = 0
# 迭代次数
times = 10000
B)类与方法定义,这一部分不要更改
# ==================================================
# 存储配送点信息的类
class Place:
def __init__(self):
self.id = 0
self.name = ''
self.location = ''
self.address = ''
self.time_a = 0
self.time_b = 0
# 货物1
self.need_a = 0
# 货物2
self.need_b = 0
# 货物3
self.need_c = 0
# 被服务完成以及车辆离开的时间
self.time_served = 0
# 自身装载总重量
def load(self):
sm = self.need_a + self.need_b + self.need_c
return sm
# 存储车辆信息的点
class Car:
def __init__(self):
self.id = 0
# 负责运输的点的队列
self.array_places = []
# 返回路线上配送点的数量
def get_places_len(self):
return len(self.array_places)
# 下一次服务的起始时间
def time_next_start(self):
return self.array_places[self.get_places_len() - 1].time_served
# 返回货物1装载重量
def get_load_need_a(self):
load = 0
for index in range(self.get_places_len()):
load += self.array_places[index].need_a
return load
# 返回货物2装载重量
def get_load_need_b(self):
load = 0
for index in range(self.get_places_len()):
load += self.array_places[index].need_b
return load
# 返回货物3装载重量
def get_load_need_c(self):
load = 0
for index in range(self.get_places_len()):
load += self.array_places[index].need_c
return load
# 根据行驶过了几个点,获取剩下的need_a货物的重量,n=0代表还没有服务任何一个点,n=2代表已经服务过两个点,此时车辆上的货物应减少
def get_load_need_a_by_time(self, n):
load = 0
for index in range(n, self.get_places_len()):
load += self.array_places[index].need_a
return load
# 根据行驶过了几个点,获取剩下的need_b货物的重量
def get_load_need_b_by_time(self, n):
load = 0
for index in range(n, self.get_places_len()):
load += self.array_places[index].need_b
return load
# 根据行驶过了几个点,获取剩下的need_c货物的重量
def get_load_need_c_by_time(self, n):
load = 0
for index in range(n, self.get_places_len()):
load += self.array_places[index].need_c
return load
# 返回所有货物重量
def get_load_all(self):
return self.get_load_need_a() + self.get_load_need_b() + self.get_load_need_c()
# 输出该车会走过的里程(不包括起始点出发和回起始点的距离),单位:米
def get_mileage_places(self):
if self.get_places_len() == 0:
return 0
else:
arr = self.array_places
temp = 0
for index in range(self.get_places_len() - 1):
temp += get_mileage(arr[index], arr[index + 1])
return temp
# 输出该车路径上点的信息
def output(self):
for index in self.array_places:
print("id=", index.id, " name:", index.name, " time_a:", index.time_a, " time_b:", index.time_b,
" need_a:", index.need_a, " need_b:", index.need_b, " need_c:", index.need_c, " time_served:",
index.time_served)
# 获得尾部place
def get_last_place(self):
return self.array_places[self.get_places_len() - 1]
# 存储起送点信息的类
class Origin:
def __init__(self):
self.id = 0
self.name = ''
self.location = ''
self.address = ''
self.arr_cars = []
self.paint = []
# 检测自己的车队是否合格,无超载、满足时间窗,合格的就更新相关信息,如果函数返回True,那么整条链都更新成功
def is_legal(self):
flag = True
for car in self.arr_cars:
if len(car.array_places) == 0:
continue
else:
if car.get_load_all() > can:
flag = False
# print(self.id, "号出发点", "car", car.id, "超载,目前", car.get_load_all(), "kg")
return flag
else:
arr = car.array_places
length = car.get_places_len()
if not time_is_legal(arr[0], self):
flag = False
return flag
else:
get_new_time_served(arr[0], self)
for index in range(length - 1):
if not time_is_legal(arr[index + 1], arr[index]):
flag = False
# print("car", car.id, "时间窗要求不符合")
return flag
else:
get_new_time_served(arr[index + 1], arr[index])
return flag
# 输出指定车辆的路径信息
def output_byid(self, iid):
if iid > len(self.arr_cars):
print("没有该车辆,id大了")
else:
for index in self.arr_cars:
if index.id == iid:
index.output()
break
# 输出所有车辆的路径信息
def output_all(self):
print('\n\n', self.id, "号起点======================================================")
for index in range(self.get_car_number()):
print(index + 1, "号车>>>>>>>>>>>>>>>>>>>载重:", self.arr_cars[index].get_load_all(), "kg 里程:",
self.get_mileage_byid(index + 1), "m")
self.arr_cars[index].output()
# 返回车辆数量
def get_car_number(self):
return len(self.arr_cars)
# 返回指定车辆的载重
def get_load_byid(self, iid):
for car in self.arr_cars:
if car.id == iid:
return car.get_load_all()
return None
# 通过id得到车辆行程距离,包括起始点出发和回起始点的距离
def get_mileage_byid(self, iid):
if iid > self.get_car_number():
print("没有该车辆,id大了")
return None
else:
car = self.arr_cars[iid - 1]
temp = car.get_mileage_places() + get_mileage(car.array_places[0], self) + get_mileage(self,
car.get_last_place())
return temp
# 获取该起点出发的车辆的所有里程
def get_mileage_all(self):
sum_mileage = 0
for index in range(1, self.get_car_number() + 1):
sum_mileage += self.get_mileage_byid(index)
return sum_mileage
# 获取该起点出发的车辆的电费消耗
def get_electricity(self):
# 三种肉制品总重量×其行驶时间
sum_ele_1 = 0
sum_ele_2 = 0
sum_ele_3 = 0
for index in self.arr_cars:
sum_ele_1 += get_time(self, index.array_places[0]) * index.get_load_need_a_by_time(0)
sum_ele_2 += get_time(self, index.array_places[0]) * index.get_load_need_b_by_time(0)
sum_ele_3 += get_time(self, index.array_places[0]) * index.get_load_need_c_by_time(0)
for jndex in range(1, index.get_places_len()):
sum_ele_1 += (index.array_places[jndex].time_served - index.array_places[
jndex - 1].time_served) * index.get_load_need_a_by_time(jndex)
sum_ele_2 += (index.array_places[jndex].time_served - index.array_places[
jndex - 1].time_served) * index.get_load_need_b_by_time(jndex)
sum_ele_3 += (index.array_places[jndex].time_served - index.array_places[
jndex - 1].time_served) * index.get_load_need_c_by_time(jndex)
sum_ele = sum_ele_1 * x1 + sum_ele_2 * x2 + sum_ele_3 * x3
return sum_ele
def get_time_spend(self):
time_spend = 0
for index in self.arr_cars:
time_spend += get_time(self, index.array_places[0])
for jndex in range(index.get_places_len() - 1):
time_spend += get_time(index.array_places[jndex], index.array_places[jndex + 1])
time_spend += get_time(index.get_last_place(), self)
return time_spend
# 该类用来保存种群和其得分
class Population:
def __init__(self):
self.id = 0
self.arr = []
self.grades = 0
# 类定义结束============================================================
# 获取两点之间的距离
def get_mileage(place1, place2):
# place1是origin类
if is_contain_bylocation(arr_origin_info, place1):
return float(arr_relation_oTOp[place1.id - 1][place2.id - 1].split(',')[0])
elif is_contain_bylocation(arr_origin_info, place2):
return float(arr_relation_oTOp[place2.id - 1][place1.id - 1].split(',')[0])
# 两个都是place类
else:
if place1.id < place2.id:
return float(arr_relation_pTOp[place1.id - 1][place2.id - 1].split(',')[0])
else:
return float(arr_relation_pTOp[place2.id - 1][place1.id - 1].split(',')[0])
# 获取两点之间的时间
def get_time(place1, place2):
if is_contain_bylocation(arr_origin_info, place1):
return float(arr_relation_oTOp[place1.id - 1][place2.id - 1].split(',')[1]) / 3600
elif is_contain_bylocation(arr_origin_info, place2):
return float(arr_relation_oTOp[place2.id - 1][place1.id - 1].split(',')[1]) / 3600
else:
if place1.id < place2.id:
return float(arr_relation_pTOp[place1.id - 1][place2.id - 1].split(',')[1]) / 3600
else:
return float(arr_relation_pTOp[place2.id - 1][place1.id - 1].split(',')[1]) / 3600
# 判断place1能否加到place2点后面,时间是否合法
def time_is_legal(place1, place2):
# 没有固定工作起始时间
if work_start is None:
# place2是origin类
if is_contain_bylocation(arr_origin_info, place2):
return True
# 两个点都是place类
else:
if place2.time_served + get_time(place1, place2) + serve_time / 60 / 60 <= place1.time_b:
return True
else:
return False
# 有固定工作起始时间
else:
if is_contain_bylocation(arr_origin_info, place2):
if work_start + get_time(place1, place2) + serve_time / 60 / 60 <= place1.time_b:
return True
else:
return False
else:
if place2.time_served + get_time(place1, place2) + serve_time / 60 / 60 <= place1.time_b:
return True
else:
return False
# 根据一个点,获取后面一个点的time_served
def get_new_time_served(place_new, place_old):
# 老点是origin
if is_contain_bylocation(arr_origin_info, place_old):
# 工作时间不固定
if work_start is None:
place_new.time_served = place_new.time_a + serve_time / 60 / 60
else:
temp = work_start + get_time(place_old, place_new)
if temp <= place_new.time_a:
place_new.time_served = place_new.time_a + serve_time / 60 / 60
else:
place_new.time_served = temp + serve_time / 60 / 60
# 老点是place
else:
temp = place_old.time_served + get_time(place_old, place_new)
if temp <= place_new.time_a:
place_new.time_served = place_new.time_a + serve_time / 60 / 60
else:
place_new.time_served = temp + serve_time / 60 / 60
# 将place加入origin的运输计划中,并且更新place的time_served,删除已经添加的place,该方法也负责判断能否加入
def add_to_origin(place: Place, origin: Origin):
# 如果origin还没有一辆有计划的车,那么就判断,如果可以运送,就新增一辆车,将place加入该车的运输计划中
if origin.get_car_number() == 0:
# 如果时间合法,重量合法(当place作为第一个配送点,重量一定合法,因为一个配送点的需求默认不超过车辆载重)
if time_is_legal(place, origin):
car = Car()
car.id = 1
get_new_time_served(place, origin)
car.array_places.append(place)
origin.arr_cars.append(car)
arr_place_info.remove(place)
return True
else:
print("place", place.id, "加入失败")
return False
# 已经有运输车
else:
# 试图加入车辆计划中
for car in origin.arr_cars:
if time_is_legal(place, car.get_last_place()) and car.get_load_all() + place.load() <= can:
get_new_time_served(place, car.get_last_place())
car.array_places.append(place)
arr_place_info.remove(place)
return True
# 加入车辆计划失败,试图作为第一个配送点,增加配送车辆
if is_contain_bylocation(arr_place_info, place):
if time_is_legal(place, origin):
car = Car()
car.id = origin.get_car_number() + 1
get_new_time_served(place, origin)
car.array_places.append(place)
origin.arr_cars.append(car)
arr_place_info.remove(place)
return True
else:
return False
# 输出所有出发点的车辆信息
def output_cars_info(arr):
time_spend = 0
road = 0
for index in arr:
index.output_all()
time_spend += index.get_time_spend()
road += index.get_mileage_all()
print("总花费时间:", time_spend, "小时,总里程:", road, "米")
# 形成初始可行解,将place加入离他最近的origin中
def init():
index = 0
while len(arr_place_info) is not 0:
temp = arr_place_info[0]
# 逐个寻找该点最近的origin
min_ori = 0
min_mileage = 99999999
for jndex in range(len(arr_origin_info)):
if get_mileage(temp, arr_origin_info[jndex]) < min_mileage:
min_mileage = get_mileage(temp, arr_origin_info[jndex])
min_ori = jndex
if add_to_origin(temp, arr_origin_info[min_ori]):
index += 1
# print(index, "号点添加到", min_ori + 1, "点中")
else:
print(index, "号点添加失败")
if len(arr_place_info) == 0:
print("全部添加完成")
# 交叉、遗传等
def gene(arr):
# 随机一个行为:
# 1代表路径上的某段(或某个)place位置改变
# 2代表路径上的某段(或某个)place移动到别的路径上,可能是一条新的路径,也可能是已经存在的一条路径
# 3代表两个路径的某段(或某个)place交换
ran_do = random.randint(1, 3)
if ran_do == 1:
# print("做了do1")
gene_do1(arr)
elif ran_do == 2:
# print("做了do2")
gene_do2(arr)
elif ran_do == 3:
# print("做了do3")
gene_do3(arr)
return True
# ran_do == 1时的操作
def gene_do1(arr):
ran_ori = arr[random.randint(0, len(arr) - 1)]
# 如果随机到的起点没有车辆计划
if ran_ori.get_car_number() == 0:
return True
else:
ran_car = ran_ori.arr_cars[random.randint(0, ran_ori.get_car_number() - 1)]
# 如果车辆的places数小于等于1
if ran_car.get_places_len() <= 1:
return True
# 如果车辆的places大于1
else:
# 随机裁切一段数组
temp = get_arrays(ran_car.array_places)
# 获取剩下的places的长度
leng = ran_car.get_places_len()
# 如果剩下的places==0,那直接插入
if leng == 0:
ran_car.array_places.extend(temp)
return True
else:
# 找到随机的一个位置,将裁切下的数组插入
ran_from = random.randint(0, leng)
if ran_from == 0:
temp.extend(ran_car.array_places)
ran_car.array_places = temp
return True
elif ran_from == leng:
ran_car.array_places.extend(temp)
return True
else:
t1 = ran_car.array_places[0:ran_from]
t2 = ran_car.array_places[ran_from:ran_car.get_places_len()]
t1.extend(temp)
t3 = t1
t3.extend(t2)
ran_car.array_places = t3
return True
# ran_do == 2时的操作
def gene_do2(arr):
ran_ori_from = arr[random.randint(0, len(arr) - 1)]
# 如果随机到的点没有车辆计划
if ran_ori_from.get_car_number() == 0:
return True
else:
ran_car_from = ran_ori_from.arr_cars[random.randint(0, ran_ori_from.get_car_number() - 1)]
# 如果车辆的点数小于1
if ran_car_from.get_places_len() == 0:
return True
# 如果车辆计划的点数大于等于1
else:
# 随机裁切一段places。
temp = get_arrays(ran_car_from.array_places)
# 判断car里面是否还有place,如果没有,删除car
if ran_car_from.get_places_len() == 0:
ran_ori_from.arr_cars.remove(ran_car_from)
# 随机抽取一个点,
ran_ori_to = arr[random.randint(0, len(arr) - 1)]
# 如果去往的place没有车辆计划
if ran_ori_to.get_car_number() == 0:
car = Car()
car.id = 1
car.array_places.extend(temp)
ran_ori_to.arr_cars.append(car)
return True
# 如果已有车辆计划
else:
# 随机一个数,判断是创建新的车队还是加入现有的车队
ran_do = random.randint(1, 2)
# 1的话创建新的车队
if ran_do == 1:
car = Car()
car.id = ran_ori_to.get_car_number() + 1
car.array_places.extend(temp)
ran_ori_to.arr_cars.append(car)
return True
# 2的话加入现有车队
else:
ran_car_to = ran_ori_to.arr_cars[random.randint(0, ran_ori_to.get_car_number() - 1)]
# 找到随机的一个位置,将裁切下的数组插入
leng = ran_car_to.get_places_len()
ran_from = random.randint(0, leng)
if ran_from == 0:
temp.extend(ran_car_to.array_places)
ran_car_to.array_places = temp
return True
elif ran_from == leng:
ran_car_to.array_places.extend(temp)
return True
else:
t1 = ran_car_to.array_places[0:ran_from]
t2 = ran_car_to.array_places[ran_from:ran_car_to.get_places_len()]
t1.extend(temp)
t3 = t1
t3.extend(t2)
ran_car_to.array_places = t3
return True
# ran_do == 3时的操作
def gene_do3(arr):
# 找到两个不一样的数字,以此找到两个不同的origin
random_1 = random.randint(0, len(arr) - 1)
random_2 = random.randint(0, len(arr) - 1)
while random_2 == random_1:
random_2 = random.randint(0, len(arr) - 1)
ran_ori_from = arr[random_1]
ran_ori_to = arr[random_2]
# 如果点的车辆数为0,就不作为
if ran_ori_from.get_car_number() == 0:
return True
if ran_ori_to.get_car_number() == 0:
return True
else:
ran_car_from = ran_ori_from.arr_cars[random.randint(0, ran_ori_from.get_car_number() - 1)]
ran_car_to = ran_ori_to.arr_cars[random.randint(0, ran_ori_to.get_car_number() - 1)]
temp_from = get_arrays(ran_car_from.array_places)
temp_to = get_arrays(ran_car_to.array_places)
# 先处理from到to
ran_from = random.randint(0, ran_car_to.get_places_len())
if ran_from == 0:
temp_from.extend(ran_car_to.array_places)
ran_car_to.array_places = temp_from
elif ran_from == ran_car_to.get_places_len():
ran_car_to.array_places.extend(temp_from)
else:
t1 = ran_car_to.array_places[0:ran_from]
t2 = ran_car_to.array_places[ran_from:ran_car_to.get_places_len()]
t1.extend(temp_from)
t3 = t1
t3.extend(t2)
ran_car_to.array_places = t3
# 再处理to到from
ran_from = random.randint(0, ran_car_to.get_places_len())
if ran_from == 0:
temp_to.extend(ran_car_from.array_places)
ran_car_from.array_places = temp_to
elif ran_from == ran_car_from.get_places_len():
ran_car_from.array_places.extend(temp_to)
else:
t1 = ran_car_from.array_places[0:ran_from]
t2 = ran_car_from.array_places[ran_from:ran_car_from.get_places_len()]
t1.extend(temp_to)
t3 = t1
t3.extend(t2)
ran_car_from.array_places = t3
return True
# 数组操作,将随机数组的一个或一段提取出来,原数组内容删除
def get_arrays(arr):
ran_from = random.randint(0, len(arr) - 1)
ran_to = random.randint(ran_from + 1, len(arr))
temp = arr[ran_from:ran_to]
for index in temp:
arr.remove(index)
return temp
# 数组操作,复制数组
def copy(arr):
temp = []
for index in arr:
t1 = Origin()
t1.id = index.id
t1.name = index.name
t1.address = index.address
t1.location = index.location
t1.paint = index.paint
for jndex in index.arr_cars:
t2 = Car()
t2.id = jndex.id
for kndex in jndex.array_places:
t3 = Place()
t3.id = kndex.id
t3.name = kndex.name
t3.address = kndex.address
t3.location = kndex.location
t3.time_served = kndex.time_served
t3.time_a = kndex.time_a
t3.time_b = kndex.time_b
t3.need_a = kndex.need_a
t3.need_b = kndex.need_b
t3.need_c = kndex.need_c
t2.array_places.append(t3)
t1.arr_cars.append(t2)
temp.append(t1)
return temp
# 数组操作,判断数组内是否包含该location
def is_contain_bylocation(arr_ori, arr_des):
for index in arr_ori:
if index.location == arr_des.location:
return True
return False
# 评分函数,用来筛选种群
def get_grades(arr):
# 里程
mileage_all = 0
# 车辆数
car_number = 0
# 电费
ele_cost = 0
# 时间花费,以小时为单位
time_spend = 0
for index in arr:
mileage_all += index.get_mileage_all()
car_number += index.get_car_number()
ele_cost += index.get_electricity()
time_spend += index.get_time_spend()
price_1 = car_number * price
price_2 = mileage_all * oil
price_3 = ele_cost
return w * (price_1 + price_2 + price_3) + (1 - w) * time_spend * tprice
# 合法函数,顾名思义,判断数组内origin的cars是否都合法,不合法全部拉黑
def is_legal(arr):
for index in arr:
if not index.is_legal():
return False
return True
C)一个其中有key的方法,这段要改key
这里面有一行key,用自己申请到的!
# 获取路线图
def paint(arr):
print()
print()
print("以下是静态概略图")
for index in arr:
if index.get_car_number() is not 0:
print(index.id, "号起点————", index.name)
for jndex in index.arr_cars:
string_name = ''
string = 'https://restapi.amap.com/v3/staticmap?traffic=1&key=自己的key&scale=2&location=' + index.location + '&paths=2,0x0000ff,1,,:' + index.location + ';'
for kndex in jndex.array_places:
string += kndex.location + ';'
string_name += kndex.name + ' -> '
string = string[:-1]
# 以下是添加标签
# string += "&labels=" + index.name.split('(')[0] + ",1,0,14,0x000FFF,0xFFFFFF:" + index.location + '|'
# for kndex in jndex.array_places:
# string += kndex.name.split('(')[0] + ",1,0,14,0xFFFFFF,0x008000:" + kndex.location + '|'
# string = string[:-1]
string += "&labels=" + str(0) + ",1,0,14,0x000FFF,0xFFFFFF:" + index.location + '|'
ttt = 1
for kndex in jndex.array_places:
string += str(ttt) + ",1,0,14,0xFFFFFF,0x008000:" + kndex.location + '|'
ttt += 1
string = string[:-1]
print(string_name)
print(string)
print()
print()
D)读取之前获取的数据,这段要改文件路径
这段代码头两行是读取数据的,这里第一个要换成需求点文件,第二个换成起送点文件。
# 读取数据
workbook_place = openpyxl.load_workbook('C:\\Users\\86909\\Desktop\\猪肉市场.xlsx')
workbook_origin = openpyxl.load_workbook('C:\\Users\\86909\\Desktop\\新五丰.xlsx')
# 各点的详细信息
ws_place_info = workbook_place.worksheets[0]
ws_origin_info = workbook_origin.worksheets[0]
# 最大行数
rows_place_info = ws_place_info.max_row
rows_origin_info = ws_origin_info.max_row
# 各点之间的距离,时间
ws_place_relation = workbook_place.worksheets[1]
ws_origin_relation = workbook_origin.worksheets[1]
# 存储各点详细信息的数组
arr_place_info = []
for i in range(2, rows_place_info + 1):
tmp = Place()
tmp.id = i - 1
tmp.name = ws_place_info.cell(i, 3).value
tmp.location = ws_place_info.cell(i, 4).value
tmp.address = ws_place_info.cell(i, 2).value
tmp.time_a = ws_place_info.cell(i, 5).value
tmp.time_b = ws_place_info.cell(i, 6).value
tmp.need_a = ws_place_info.cell(i, 7).value
tmp.need_b = ws_place_info.cell(i, 8).value
tmp.need_c = ws_place_info.cell(i, 9).value
arr_place_info.append(tmp)
# 存放起始点信息的数组
arr_origin_info = []
for i in range(1, rows_origin_info + 1):
tmp = Origin()
tmp.id = i
tmp.name = ws_origin_info.cell(i, 3).value
tmp.location = ws_origin_info.cell(i, 4).value
tmp.address = ws_origin_info.cell(i, 2).value
arr_origin_info.append(tmp)
# 存放点到点之间的距离、时间
col_place = ws_place_relation.max_column
col_origin = ws_origin_relation.max_column
rows_place_relation = ws_place_relation.max_row
rows_origin_relation = ws_origin_relation.max_row
arr_relation_pTOp = [[None] * col_place for i in range(rows_place_relation)]
arr_relation_oTOp = [[None] * col_origin for i in range(rows_origin_relation)]
for i in range(rows_place_relation):
for j in range(col_place):
arr_relation_pTOp[i][j] = ws_place_relation.cell(i + 1, j + 1).value
for i in range(rows_origin_relation):
for j in range(col_origin):
arr_relation_oTOp[i][j] = ws_origin_relation.cell(i + 1, j + 1).value
E)最后,这段不用改
# 存放路线图的
# 准备工作结束=====================================================================
init()
print("原始分数:", get_grades(arr_origin_info))
sleep(2)
output_cars_info(arr_origin_info)
print('开始迭代')
sleep(2)
# 运行
# ====================================
# 画目标函数图的坐标存放
pltx = []
plty = []
# ====================================
tt = copy(arr_origin_info)
for i in range(times):
gene(tt)
# 因为is_legal()函数也负责更新place的time_served,所以要更新一次,之前这里少了,找bug找了4个多小时
is_legal(tt)
com1 = float(get_grades(tt))
com2 = float(get_grades(arr_origin_info))
if is_legal(tt) and com1 < com2:
arr_origin_info = copy(tt)
pltx.append(i)
plty.append(com1)
print(com1)
else:
tt = copy(arr_origin_info)
if i == times - 1:
print("最终分数:", get_grades(arr_origin_info))
output_cars_info(arr_origin_info)
paint(arr_origin_info)
# 绘目标函数图
plt.plot(pltx, plty, 'c-')
plt.show()
代码结束!
运行完毕后,会输出一个目标函数值的变化曲线。
如:
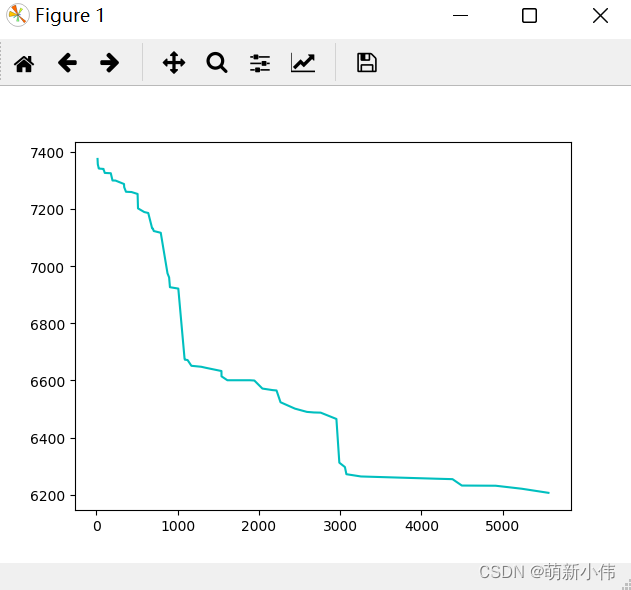
关闭这个,会有结果在控制台输出:
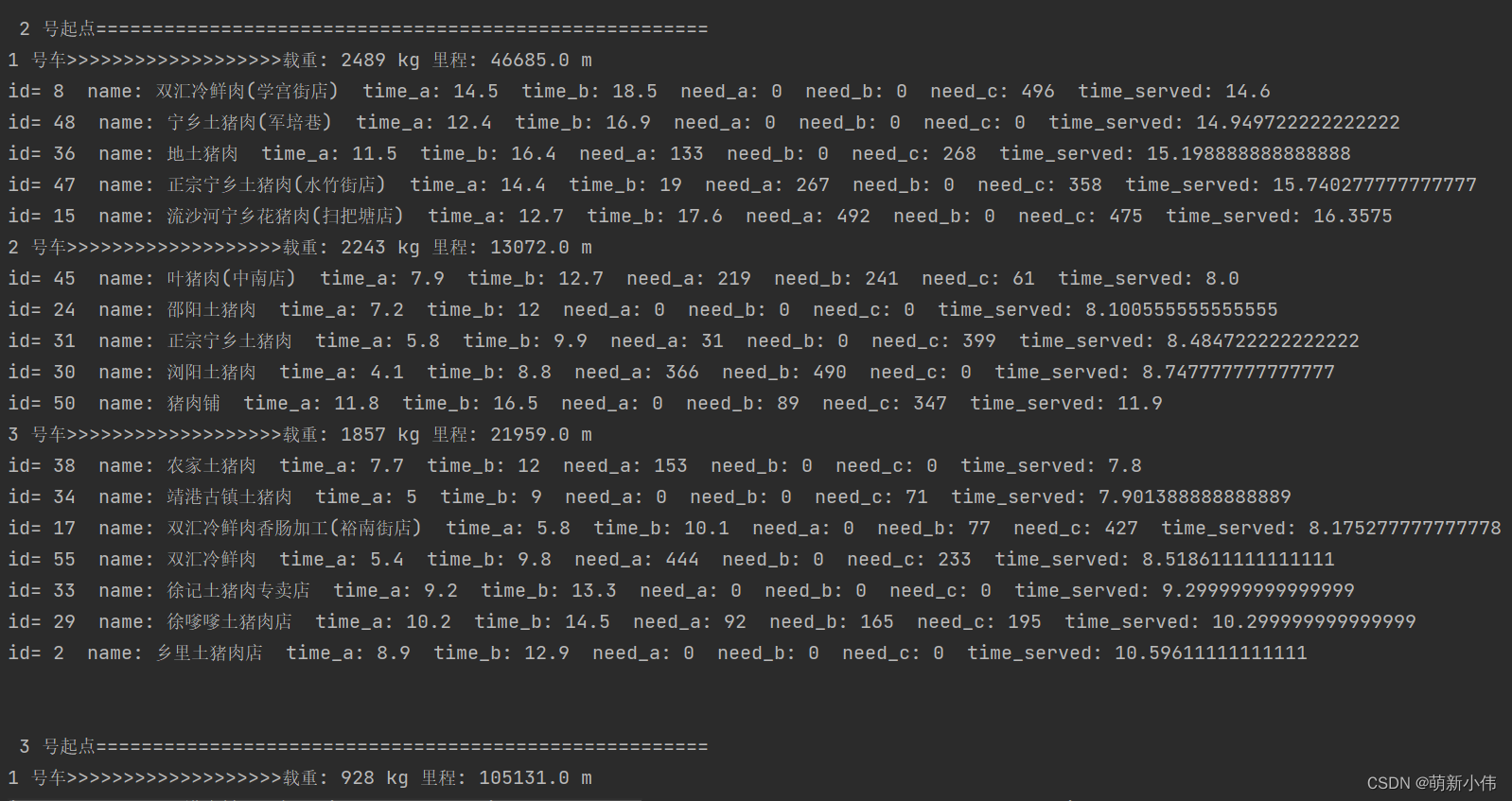
这一部分是详细信息,是每个起点的车辆具体运输安排。
然后是这段输出:
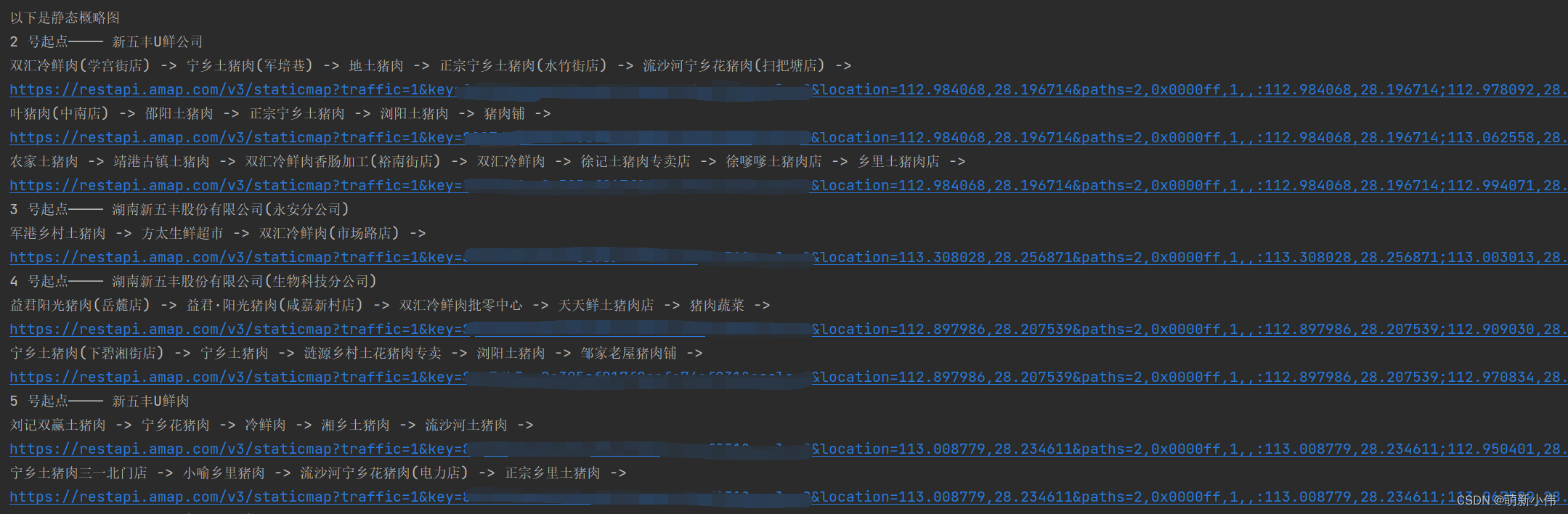
每个链接对应一个路线规划,点开就可以获取详细信息,数字是顺序,0是起点(当时是用的每个点的名称,但是字太大了,会挡到线)
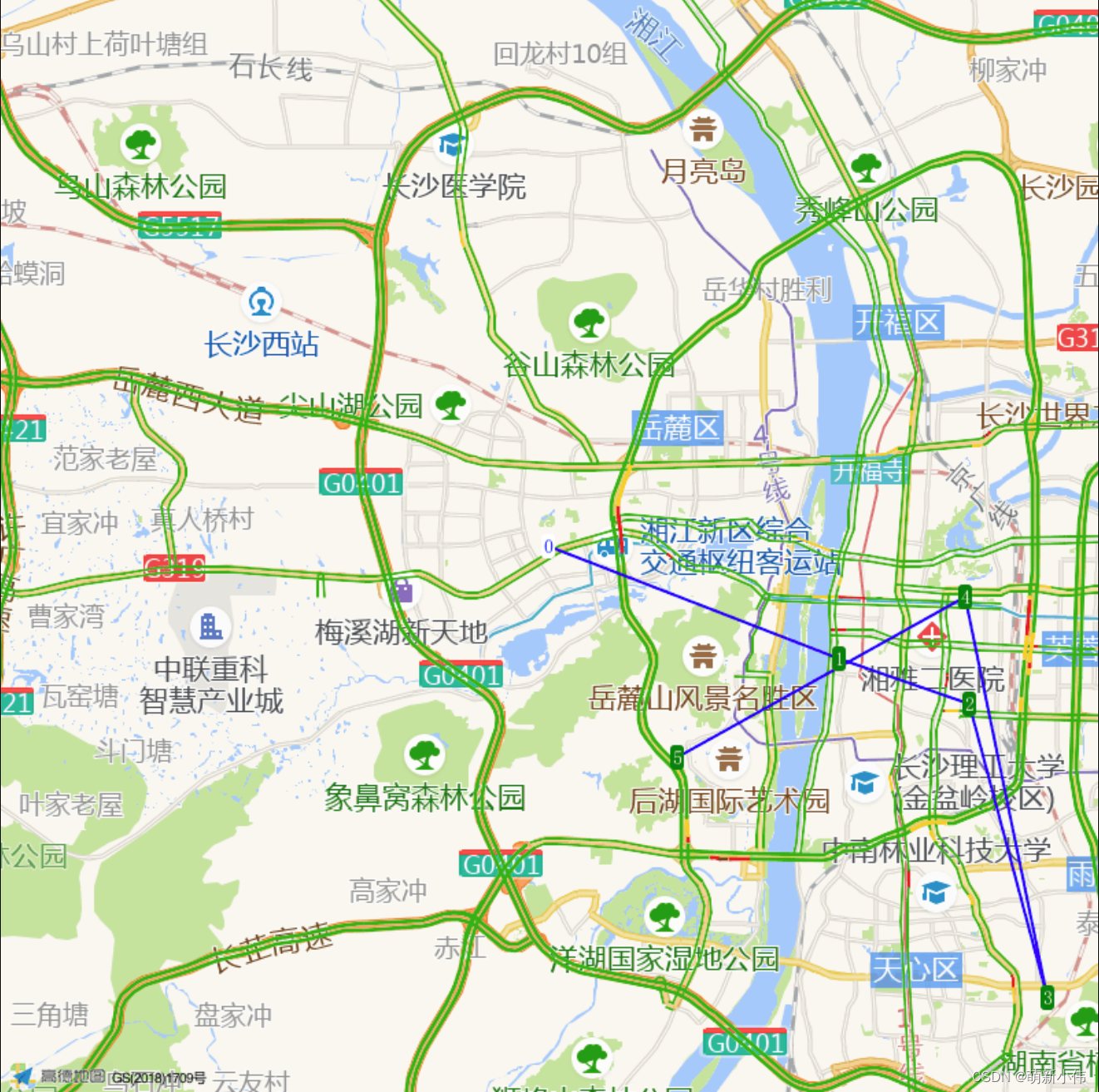
学术垃圾完成。














 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









