







以下内容是自己学习北京邮电大学鲁鹏教授计算机视觉与深度学习课程(A02)的一些笔记,笔者能力有限,如有错误还望各位大佬在评论区批评指正 。
先贴一下课程的官网:CV-XUEBA
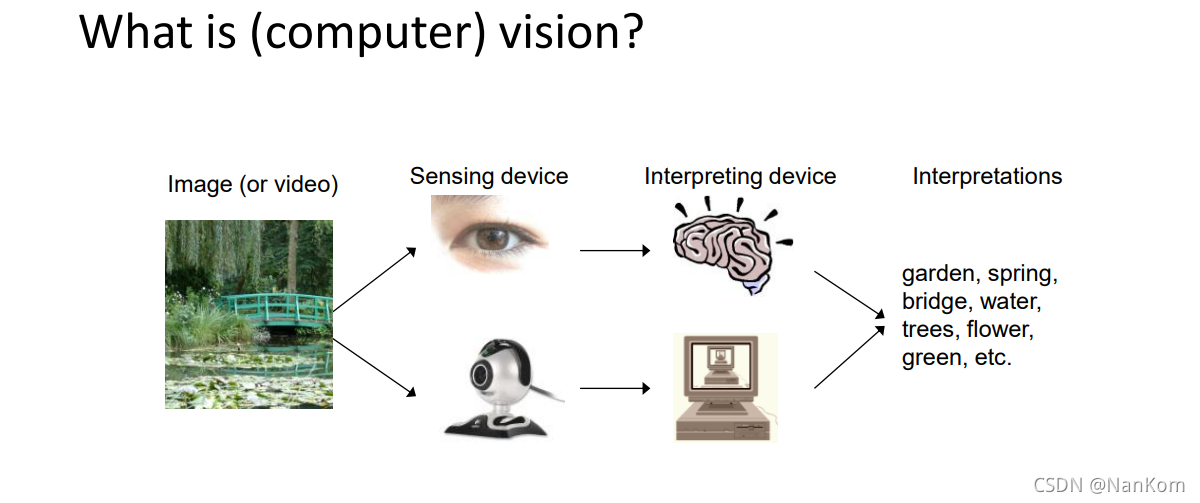
1、什么是计算机视觉?
计算机视觉(computer vision)是一门研究如何使机器“看”的科学,也就是通过摄像头的捕获,再经过计算机处理,输出解释。计算机视觉最重要的是摄像头对采集图像的理解。
2、计算机视觉的目标(难点)
如下图,人能很快的看出图中有火车,楼梯,而且火车是倾倒的,从图中信息可以得出这显然是一场灾难。但是在机器看来这是一些数据矩阵,既然我们要让机器像人一样能够理解图像,我们就要让机器能看到图像中的组成元素,从而理解图像要表达的含义。也就是说,计算机视觉的目标是跨越“语义鸿沟”建立像素到语义的映射。
例如一张300*400的灰度图,每个像素点都是0-255的数字所代表的色阶,对机器来说是12000个像素点,如果每个像素点用1byte表示就是12000byte,机器需要从这12000个byte中像人类一样理解这张图所表达的含义。这就是从byte到图像语义,计算机视觉的难点就在这。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









