







参照书籍:《大数据技术原理与应用》
准备工作:
1.找到所在路径,启动hadoop,启动hive
$ cd usr/local/hadoop
$ ./sbin/start-dfs.sh //启动hadoop
$ hive //启动hive
2.准备两个txt文件,为词频统计准备数据
$ cd
$ mkdir hivetest //创建hivetest文件夹
$ cd hivetest //到hivetest文件夹
$ echo "hello world" > file1.txt
$ echo "hello hadoop" > file2.txt
进入hive命令行界面,编写HiveQL语句,实现WordCount算法:
3.建表t_e用if not exists判断–>我已经创建过t_e表了没有这句话会报错
$ hive
hive >create table if not exists t_e(line string); //line属性,类型string
4.导入两个文件的数据到t_e表中,可以在Shell窗口用命令pwd查看当前路径
hive >load data local inpath '/home/hadoop/hivetest/file1.txt' into table t_e;
hive >load data local inpath '/home/hadoop/hivetest/file2.txt' into table t_e;
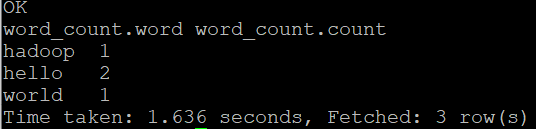
5.进行计算词频统计,word_count表包含单词和单词出现的次数这两个字段。
hive > create table word_count as //统计出来的结果放在word_count表中
> select word,count(1) as count from //写入这两个字段,并重新命名名为count列
> (select explode(split(line,' '))as word from t_e) w //扫描t_e表后,把行行拿进来以后对它进行单词的(split)拆分,最终写入w文件
> group by word //根据word进行分组-->相同的单词排在一起
> order by word; //按照字母的升序排序
6.查看结果
hive > select * from word_count;















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









