







待爬取网站:

此爬虫程序大致分为以下步骤:
1. 获取官网页面
2. 提取各新闻的链接
3. 提取各板块的新闻标题
4. 发送到 QQ 邮箱
1. 首先使用 Requests 库获取官网页面:
import requests
def get_html(url):
print("正在获取页面……")
headers = {
'Cookie': "UM_distinctid=17101abc69635b-0e556116b0f673-f313f6d-144000-17101abc6973c8; JSESSIONID=3178C10CD6DE2F5EA6033F90566F562C; wzws_cid=7a15963ee9210949b0d09b2f2889a0907ed8418df0e1e8b8122cd34a54d6be425da4ae3433c5ca7b3146755fc4cfcc31069f2f47f9468431388ba3ddfcac6c9f875fc30f80771a437b1ce7a07185b1d9",
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
}
try:
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
if r.status_code == 200:
print("获取页面成功!")
except Exception as e:
print("获取页面失败,原因是:%s" % e)
return r.text
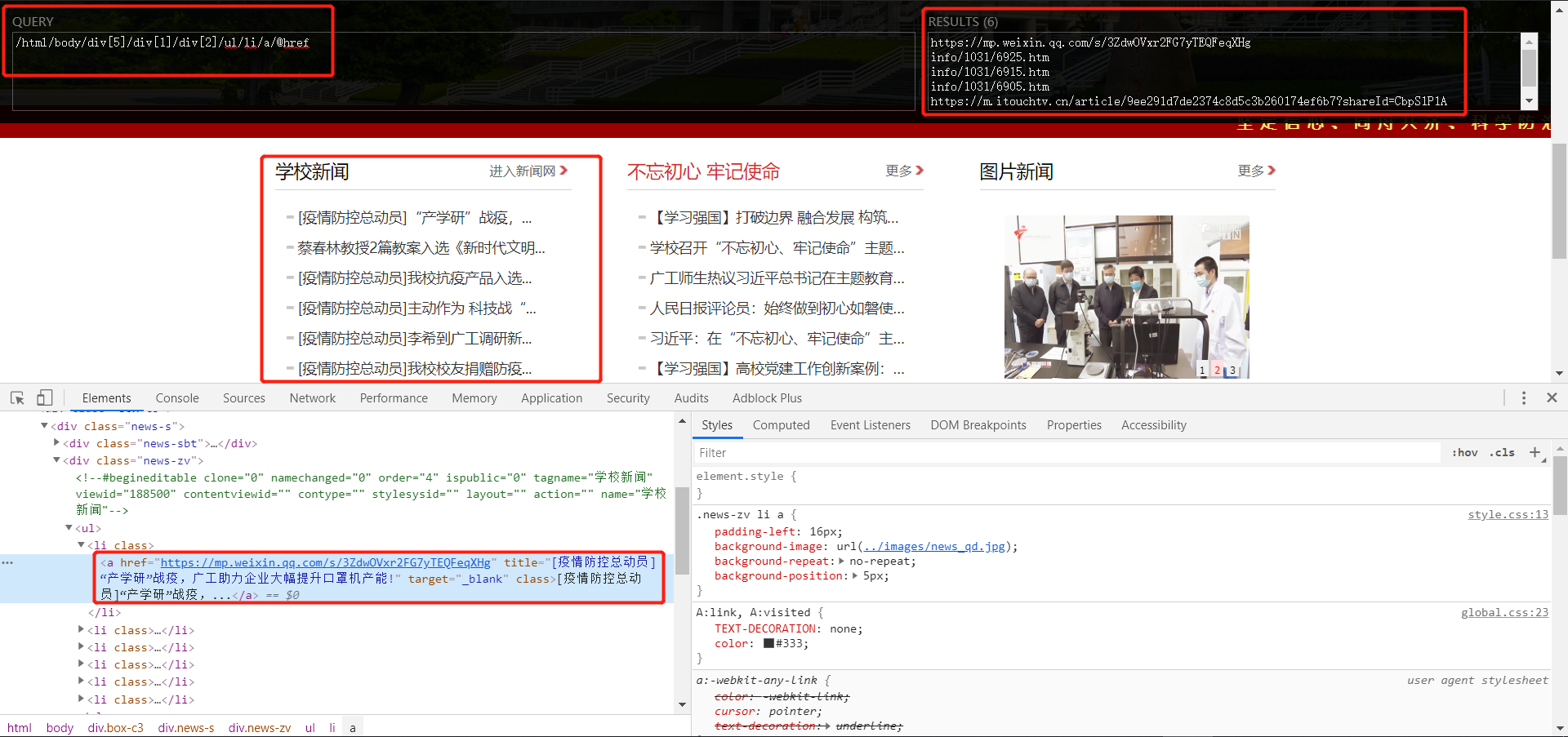
2. 提取各新闻的链接
此处利用 XPath Helper 和 Chrome 的开发者工具抓包:
XPath Helper 安装教程:https://blog.csdn.net/weixin_45961774/article/details/104534166
from lxml import etree
def get_url():
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
}
url = "http://old.gdut.edu.cn/"
r = requests.get(url, headers=headers)
html = etree.HTML(r.text)
link1 = html.xpath(
"/html/body/div[@class='box-c3']/div[@class='news-s']/div[@class='news-zv']/ul/li/a/@href")
link2 = html.xpath(
"/html/body/div[@class='box-c']/div[@class='news-s']/div[@class='news-zv']/ul/li/a/@href")
link3 = html.xpath(
"/html/body/div[@class='box-c3']/div[@class='news-g']/div[@class='news-zv2']/ul/li/a/@href")
link4 = html.xpath(
"/html/body/div[@class='box-c']/div[@class='news-g']/div[@class='news-zv2']/ul/li/a/@href")
link5 = html.xpath(
"/html/body/div[@class='box-c']/div[@class='news-x']/div[@class='news-zv3']/ul/li/a/@href")
return link1, link2, link3, link4, link5
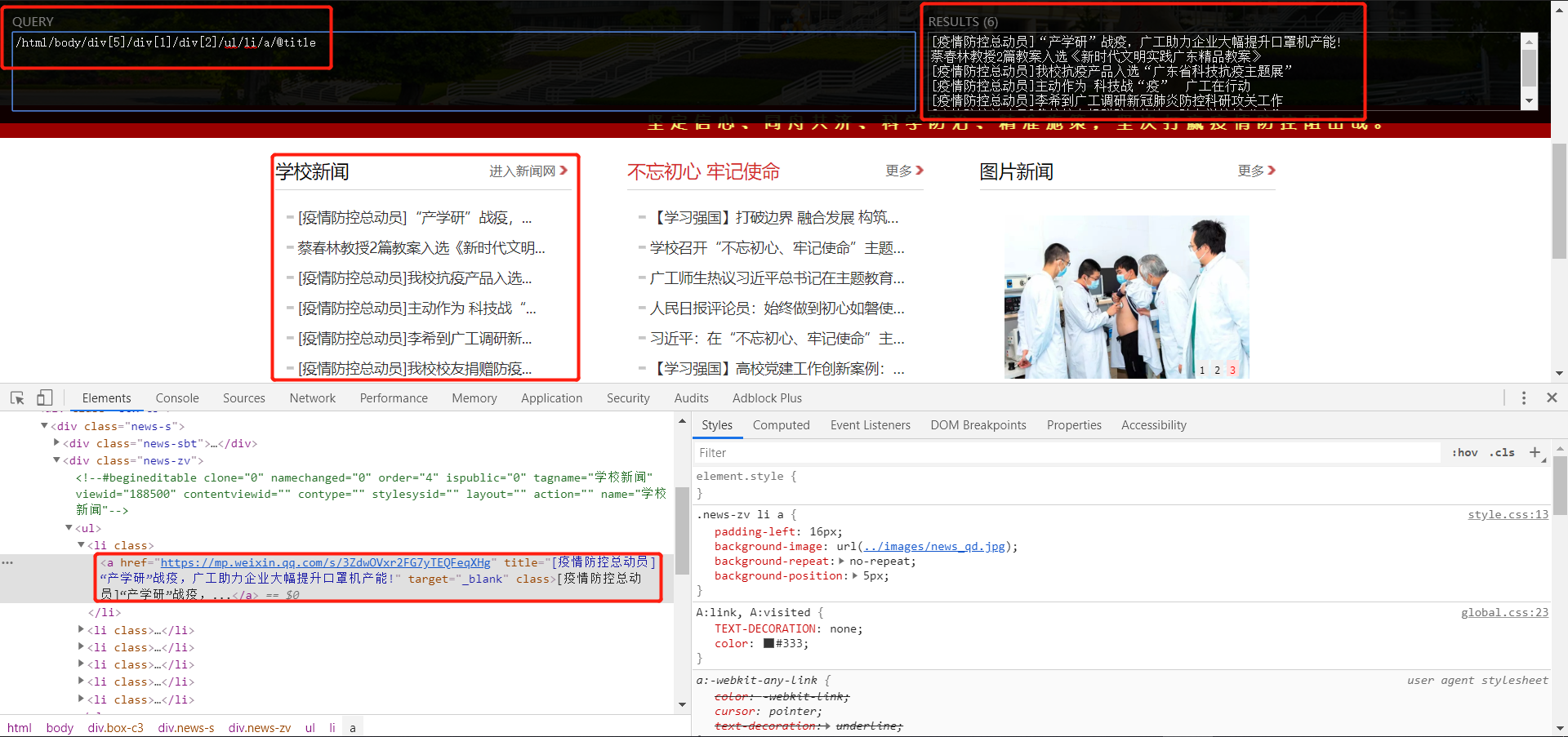
3. 提取各板块的新闻标题
def parse_html(html):
print("正在解析页面……")
html = etree.HTML(html)
gdut_news = html.xpath(
"/html/body/div[@class='box-c3']/div[@class='news-s']/div[@class='news-zv']/ul/li/a/@title")
gdut_media = html.xpath("/html//div[6]/div[1]/div[2]/ul/li/a/@title")
bwcx_fdsz = html.xpath("/html//div[5]/div[2]/div[2]/ul/li/a/@title")
Academic_Notice = html.xpath(
"/html/body/div[6]/div[2]/div[2]/ul/li/a/@title")
stu_work = html.xpath("/html/body/div[6]/div[3]/div[2]/ul/li/a/@title")
print("解析页面成功!")
for i in range(5):
gdut_news[i] = gdut_news[i] + " 详情点击:" + get_url()[0][i]
gdut_media[i] = gdut_media[i] + " 详情点击:" + get_url()[1][i]
bwcx_fdsz[i] = bwcx_fdsz[i] + " 详情点击:" + get_url()[2][i]
Academic_Notice[i] = Academic_Notice[i] + " 详情点击:" + get_url()[3][i]
stu_work[i] = stu_work[i] + " 详情点击:" + get_url()[4][i]
all_news = '\n'.join(gdut_news) + '\n' + '\n'.join(
gdut_media) + '\n' + '\n'.join(bwcx_fdsz) + '\n' + '\n'.join(
Academic_Notice) + '\n' + '\n'.join(stu_work)
return all_news
4. 发送到 QQ 邮箱
import smtplib
from email.mime.text import MIMEText
from email.header import Header
def sent_email(mail_body):
sender = '发送人邮箱'
receiver = '收信人邮箱'
smtpServer = 'smtp.qq.com' # 简单邮件传输协议服务器(这里是QQ邮箱的)
username = '用户名'
password = 'smtp授权码'
mail_title = '【广东工业大学官网通知】'
mail_body = mail_body
message = MIMEText(mail_body, 'plain', 'utf-8')
message["Accept-Language"] = "zh-CN"
message["Accept-Charset"] = "ISO-8859-1,utf-8"
message['From'] = sender
message['To'] = receiver
message['Subject'] = Header(mail_title, 'utf-8')
try:
smtp = smtplib.SMTP()
smtp.connect(smtpServer)
smtp.login(username, password)
smtp.sendmail(sender, receiver, message.as_string())
print('邮件发送成功!')
smtp.quit()
except smtplib.SMTPException:
print("邮件发送失败!")
PS:sender 是发送方,receiver 是接收方,username 是邮箱账号,但 password 不是邮箱密码,而是 smtp 授权码。
如何获取 smtp 授权码:https://blog.csdn.net/weixin_45961774/article/details/105040536
主函数:
if __name__ == '__main__':
url = 'http://old.gdut.edu.cn/'
html = get_html(url)
sent_email(mail_body=parse_html(html))
最后我们运行程序:

然后查看邮箱:

成功收到邮箱!
完整源代码:https://github.com/Giyn/PythonScraper/blob/master/GDUT/old_official_website.py















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









