







Part -1 前置算法
- 了解图的存储,本文使用邻接表来存储图。
Part 1 最小生成树
什么是最小生成树?《算法导论》给了我们一个很好的解释

最小生成树在许多领域都有它的作用。譬如网络的连接,每一个节点(计算机)断网后,最小生成树就会重新计算,所以算法的速度还是不容忽视的。
最小生成树其实是最小权重生成树的简称。
——百度百科
Part 2 prim
接下来要介绍的prim算法就是用来生成最小生成树的。
prim是一种贪心算法。
过程
初始化
变量名解释
Dis,表示到整棵树的距离。
Path,路径,节点的父节点。
Mark,标记,为true则表示该点遍历过。
初始化
将dis全部初始化为无限。
将path全部初始化为0。
将mark初始化为false。
dis[s] = 0; // 自己到自己为0
循环
遍历n次:
从没有遍历的节点中找到一个从树到节点最近的节点i
在mark中标记i:mark[i] = true;
遍历节点i的路径:
(为表达清楚,设路径另一端为j)
当 路径长度 < dis[j]记录的长度:
dis[j] = 路径长度
path[j] = i更新父节点为自己
伪代码
下面为《算法导论》中的英文伪代码。
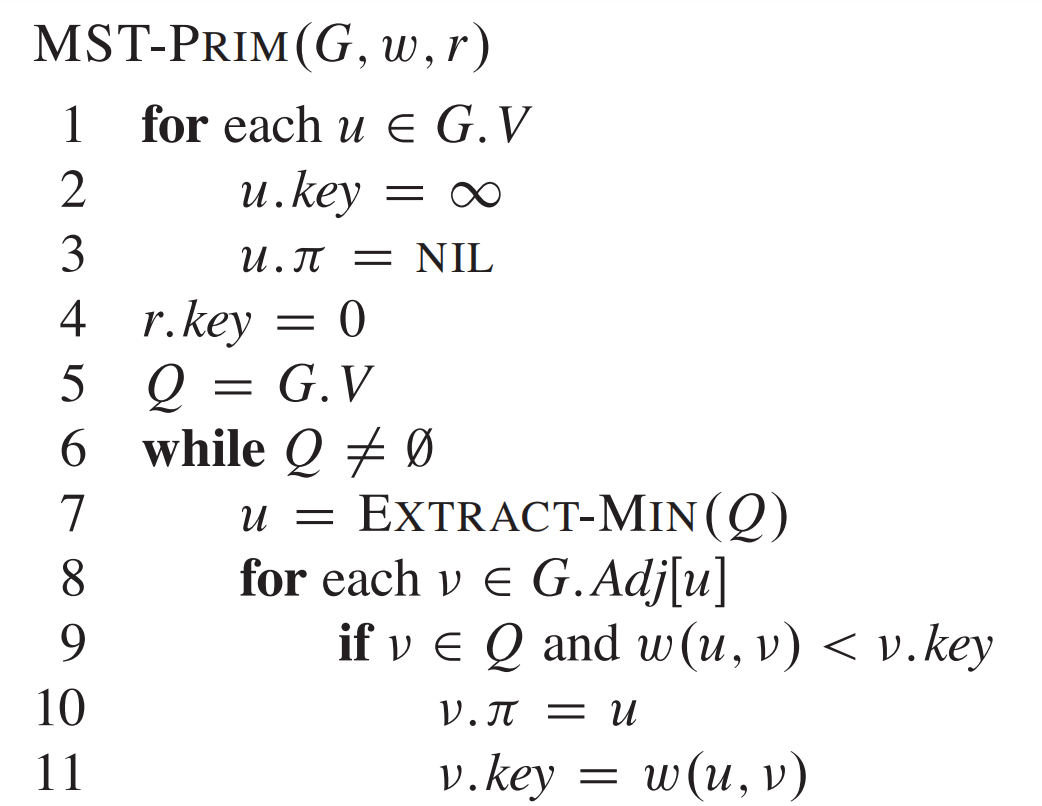
比较
通过比较过程与代码,我们发现prim和dijkstra十分相似。
如下图,出去第一行只有两行不同
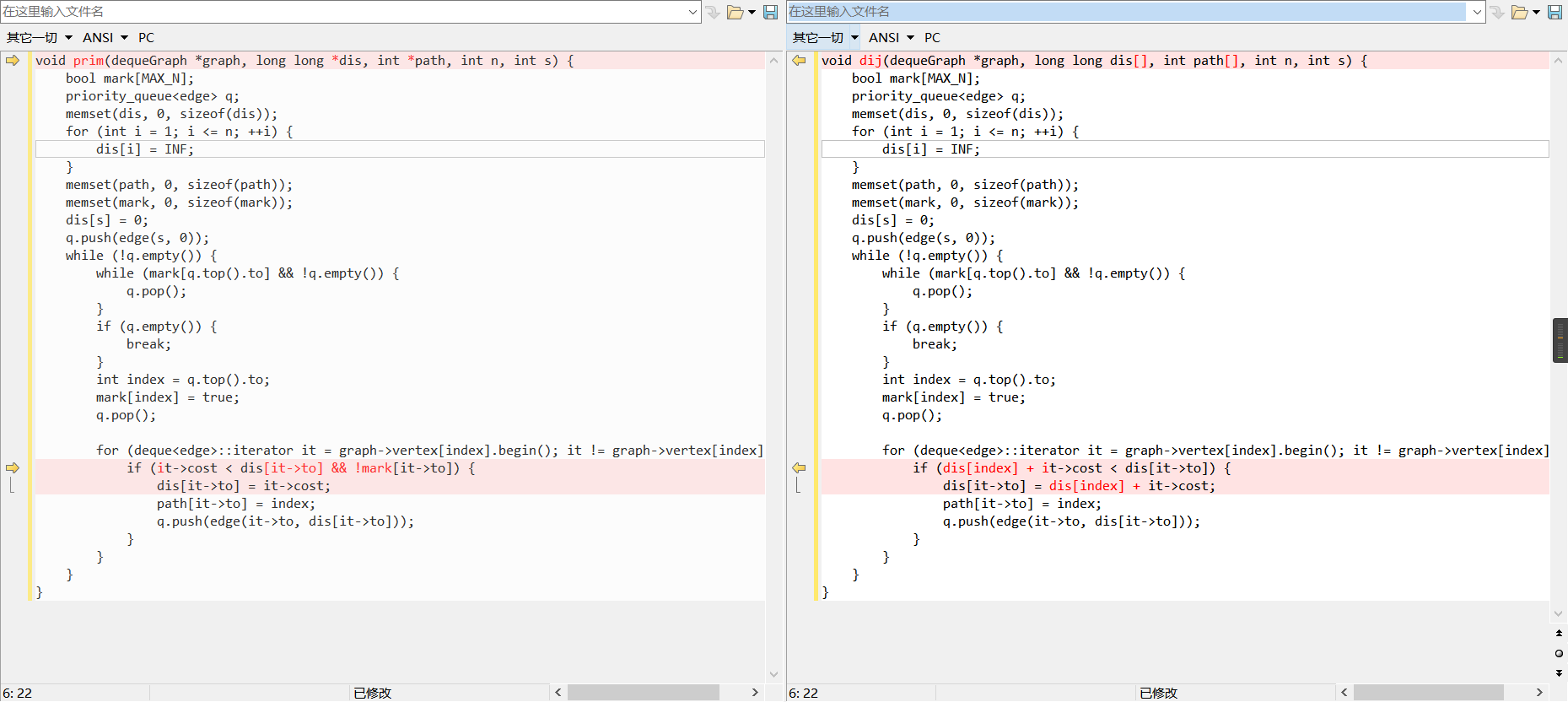
dij的距离是需要叠加的,而prim不需要,只需要单条路径的距离。
Part 3 堆优化
既然和dijkstra这么像,那么dijkstra的堆优化prim自然也可以。
priority_queue<edge> q;
q.push(edge(s, 0));
while (!q.empty()) {
将起点push到q中,然后开始循环。
while (mark[q.top().to] && !q.empty()) {
q.pop();
}
if (q.empty()) {
break;
}
int index = q.top().to;
mark[index] = true;
q.pop();
上面的翻译下就是
如果 队列头被访问过了 而且 队列不空:
将队列头pop掉
如果 队列空了
退出
将index赋值为队列头
将index标记为访问过了
队列头已经取出来了,pop掉。
for (deque<edge>::iterator it = graph->vertex[index].begin(); it != graph->vertex[index].end(); it++< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









