









0.前言,
随着网络安全的深入发展,传统的HTTP协议传送网络数据信息是以明文的方式发送数据,这样传输的信息很容易被技术手段拦取,直接获得数据信息,使得互联网上的交易或者信息传送过程中很不安全。从而就使用TLS对HTTP数据进行加密通信。
HTTP
HTTP发展历史
-
HTTP 1.0: GET + 请求的文件路径,服务端收到请求后返回一个以 ASCII 字符流编码的 HTML 文档。
-
HTTP 1.0:支持最基本的 GET、POST 方法、引入 header、传输的数据不局限于纯文本
-
HTTP 1.1:增减缓存策略、支持长连接、支持断点续传,状态码 206、支持新的方法 PUT,DELETE 等,可用于 Restful API
-
HTTP 2.0:数据通过二进制协议传输、支持压缩 header,减少体积、多路复用,一次 TCP 连接中可以多个 HTTP 并行请求、服务端推送,2015 年正式发布的 HTTP/2 默认不再使用 ASCII 编码传输,而是改为二进制数据,来提升传输效率。

HTTP 2.0 多路复用数据帧传输 -
2018 年 HTTP/3 将底层依赖的 TCP 改成 UDP,从而彻底解决了这个问题。UDP 相对于 TCP 而言最大的特点是传输数据时不需要建立连接,可以同时发送多个数据包,所以传输效率很高,缺点就是没有确认机制来保证对方一定能收到数据。
总结
| 协议版本 | 解决的核心问题 | 解决方式 |
|---|---|---|
| 0.9 | HTML 文件传输 | 确立了客户端请求、服务端响应的通信流程 |
| 1.0 | 不同类型文件传输 | 设立头部字段 |
| 1.1 | 创建/断开 TCP 连接开销大 | 建立长连接进行复用 |
| 2 | 并发数有限 | 二进制分帧 |
| 3 | TCP 丢包阻塞 | 采用 UDP 协议 |
HTTP 报文组成部分
http报文:由请求报文和响应报文组成
请求报文:由请求行、请求头、空行、请求体四部分组成
响应报文:由状态行、响应头、空行、响应体四部分组成
- 请求行:包含http方法,请求地址,http协议以及版本
- 请求头/响应头:就是一些key:value来告诉服务端我要哪些内容,要注意什么类型等,请求头/响应头每一个字段详解
- 空行:用来区分首部与实体,因为请求头都是key:value的格式,当解析遇到空行时,服务端就知道下一个不再是请求头部分,就该当作请求体来解析了
- 请求体:请求的参数
- 状态行:包含http协议及版本、数字状态码、状态码英文名称
- 响应体:服务端返回的数据
HTTP 请求方法(9种)
HTTP1.0:GET、POST、HEAD
》
HTTP1.1:PUT、PATCH、DELETE、OPTIONS、TRACE、CONNECT
| 方法 | 描述 |
|---|---|
| GET | 获取资源 |
| POST | 传输资源,通常会造成服务器资源的修改 |
| HEAD | 获得报文首部 |
| PUT | 更新资源 |
| PATCH | 对PUT的补充,对已知资源部分更新 菜鸟 |
| DELETE | 删除资源 |
| OPTIONS | 列出请求资源支持的请求方法,用来跨域请求 |
| TRACE | 追踪请求/响应路径,用于测试或诊断 |
| CONNECT | 将连接改为管道方式用于代理服务器(隧道代理下面有讲) |
GET 和 POST 的区别
- GET在浏览器回退时是无害的,而POST会再次发起请求
- GET请求会被浏览器主动缓存,而POST不会,除非手动设置
- GET请求参数会被安逗保留在浏览器历史记录里,而POST中的参数不会被保留
- GET请求在URL中传递的参数有长度限制(浏览器限制大小不同),而POST没有限制
- GET参数通过URL传递,POST放在Request body中
- GET产生的URL地址可以被收藏,而POST不可以
- GET没有POST安全,因为GET请求参数直接暴露在URL上,所以不能用来传递敏感信息
- GET请求只能进行URL编码,而POST支持多种编码方式
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制
- GET产生一个TCP数据包,POST产生两个数据包(Firefox只发一次)。GET浏览器把 http header和data一起发出去,响应成功200,POST先发送header,响应100 continue,再发送data,响应成功200
常见 HTTP 状态码
1xx: 指示信息——表示请求已接收,继续处理
2xx: 成功——表示请求已被成功接收
3xx: 重定向——表示要完成请求必须进行进一步操作
4xx: 客户端错误——表示请求有语法错误或请求无法实现
5xx: 服务端错误——表示服务器未能实现合法的请求
常见状态码:
| 状态码 | 描述 |
|---|---|
| 200 | 请求成功 |
| 206 | 已完成指定范围的请求(带Range头的GET请求),场景如video,audio播放文件较大,文件分片时 |
| 301 | 永久重定向 |
| 302 | 临时重定向 |
| 304 | 请求资源未修改,可以使用缓存的资源,不用在服务器取 |
| 400 | 请求有语法错误 |
| 401 | 没有权限访问 |
| 403 | 服务器拒绝执行请求,场景如不允许直接访问,只能通过服务器访问时 |
| 404 | 请求资源不存在 |
| 500 | 服务器内部错误,无法完成请求 |
| 503 | 请求未完成,因服务器过载、宕机或维护等 |
1. 普通代理(中间人代理)

代理服务器相当于一个中间人,帮我们过滤、缓存、负载均衡(多台服务器共用一台代理情况下)等一些处理
注意,实际场景中客户端和服务器之间可能有多个代理服务器。
2. 隧道代理
客户端通过CONNECT方法请求隧道代理创建一个可以到任意目标服务器和端口号的TCP连接,创建成功之后隧道代理只做请求和响应数据的转发,中间它不会做任何处理

为什么需要隧道代理呢?
我们都知道https服务是需要网站有证书的,而代理服务器显然没有,所以浏览器和代理之间无法创建TLS,所以就有了隧道代理,它把浏览器的数据原样透传,这样就实现了通过中间代理和服务端进行TLS握手,然后进行加密传输。
代理服务器,到底有什么好处呢?
- 突破访问限制:如访问一些单位或集团内部资源,或用国外代理服务器(翻墙),就可以上国外网站看片等
- 安全性更高:上网者可以通过这种方式隐藏自己的IP,免受攻击。还可以对数据过滤,对非法IP限流等
- 负载均衡:客户端请求先到代理服务器,而代理服务器后面有多少源服务器,IP是多少,客户端是不知道的。因此,代理服务器收到请求后,通过特定的算法(随机算法、轮询、一致性hash、LUR(最近最少使用) 算法这里不细说了)把请求分发给不同的源服务器,让各个源服务器负载尽量均衡
- 缓存代理:将内容缓存到代理服务器(这个下面一节详细说)
代理最常见的请求头
Via
是一个能用首部,由代理服务器添加,适用于正向和反向代理,在请求和响应首部均可出现,这个消息首部可以用来追踪消息转发情况,防止循环请求,还可以识别在请求或响应传递链中消息发送者对于协议的支持能力,详情请看MDN
via: 1.1vegur
via: HTTP/1.1 GWA
via: 1.0 fred,1.1 p.example.net
X-Forwarded-For
记录客户端请求的来源IP,每经过一级代理(匿名代理除外),代理服务器都会把这次请求的来源IP追加进去
X-Forwarded-For: client,proxy1,proxy2
注意:与服务器直连的代理服务器的IP不会被追加进去,该代理可能过TCP连接的Remote Address字段获取到与服务器直连的代理服务器IP
X-Real-IP
一般记录真实发出请求的客户端的IP,还有X-Forwarded-Host和X-Forwarded-Proto分别记录真实发出请求的客户端的域名和协议名
代理中客户端IP伪造问题以及如何预防?
X-Forwarded-For是可以伪造的,比如一些通过X-Forwarded-For获取到客户端IP来限制刷票的系统就可以通过伪造该请求头达到刷票的目的,如果客户端请求显示指定了
XForwarded-For:192.168.1.108
那么服务端收到的这个请求头,第一个IP就是伪造的
预防
- 在对外Nginx服务器上配置
location / {
proxy_set_header X-Forwarded-For $remote_addr
}
这样第一个IP就是从TCP连接客户端的IP,不会读取伪造的
- 从右到左遍历X-Forwarded-For的IP,排除已知代理服务器IP和内网IP,获取到第一个符合条件的IP就可以了
正向代理和反向代理
正向代理
工作在客户端的代理为正向代理。使用正向代理的时候,需要在客户端配置需要使用的代理服务器,正向代理对服务端透明。比如抓包工具Fiddler、Charles以及访问一些外网网站的代理工具都是正向代理

正向代理通常用于
- 缓存
- 屏蔽某些不健康的网站
- 通过代理访问原本无法访问的网站
- 上网认证,对用户访问进行授权
反向代理
工作在服务端的代理称为反向代理。使用反向代理的时候,不需要在客户端进行设置,反向代理对客户端透明。如Nginx就是反向代理

反向代理通常用于:负载均衡、服务端缓存、流量隔离、日志、金丝雀发布
代理中的长连接
在各个代理和服务器、客户端节点之间是一段一段的TCP连接,客户端通过代理访问目标服务器也叫逐段传输,用于逐段传输的请求头叫逐段传输头。
逐段传输头会在每一段传输的中间代理中处理掉,不会传给下一个代理
标准的逐段传输头有:Keep-Alive、Transfer-Encoding、TE、Connection、Trailer、Upgrade、Proxy-Authorization、Proxy-Authenticate。
Connection头决定当前事务完成后是否关闭连接,如果该值为keep-alive,则连接是持久连接不会关闭,使得对同一服务器的请求可以继续在该连接上完成
说一下 HTTP 缓存及缓存代理
关于http缓存在这篇文章里详细介绍 为什么第二次打开页面快?五步吃透前端缓存,让页面飞起
缓存代理就是让代理服务器接管一部分的服务端的http缓存,客户端缓存过期之后就近到代理服务器的缓存中获取,代理缓存过期了才请求源服务器,这样流量大的时候能明显降低源服务器的压力
注意响应头字段
- Cache-Control: 值有public时,表示可以被所有终端缓存,包括代理服务器、CDN。值有private时,只能被终端浏览器缓存,CDN、代理等中继服务器都不可以缓存。
HTTPS
HTTPS 是超文本传输安全协议,即HTTP + SSL/TLS。说白了就是 HTTP Plus

SSL/TLS
一张图让你理解SSL和TLS的关系

如图,TLS是SSL的升级版,而且TLS1.2版本以下都已废弃,目前主要用的是TLS 1.2和TLS 1.3。而OpenSSL则是开源版本。
那么它到底是个啥呢?
浏览器和服务器通信之前会先协商,选出它们都支持的加密套件,用来实现安全的通信。常见加密套件
随便拿出一个加密套件举例,如:RSA-PSK-AES128-GCM-SHA256,就是长这样,代表什么意思呢,我们看图

- RSA:表示握手时用RSA算法交换密钥
- PSK:表示使用PSK算法签名
- AES128-GCM:表示使用AES256对称加密算法通信,密钥长度128,分组模式GCM。TLS 1.3中只剩下称加密算法有AES和CHACHA20,分组模式只剩下GCM和POLY1305
- SHA256:表示使用SHA256算法验证信息完整性并生成随机数。TLS 1.3中哈希摘要算法只剩下SHA256和SHA384了
为什么需要用到这么多算法呢?
为了保证安全,TLS需要保证信息的:机密性、可用性、完整性、认证性、不可否认性,每一种算法都有其特定的用处
HTTPS 中 TLS 的加密算法
TLS实际用的是两种算法的混合加密。通过 非对称加密算法 交换 对称加密算法 的密钥,交换完成后,再使用对称加密进行加解密传输数据。这样就保证了会话的机密性。过程如下
- 浏览器给服务器发送一个随机数client-random和一个支持的加密方法列表
- 服务器把另一个随机数server-random、加密方法、公钥传给浏览器
- 浏览器又生成另一个随机数pre-random,并用公钥加密后传给服务器
- 服务器再用私钥解密,得到pre-random
- 浏览器和服务器都将三个随机数用加密方法混合生成最终密钥
这样即便被截持,中间人没有私钥就拿不到pre-random,就无法生成最终密钥。
可又有问题来了,如果一开始就被DNS截持,我们拿到的公钥是中间人的,而不是服务器的,数据还是会被窃取,所以数字证书来了,往下看,先简单说一下摘要算法
摘要算法
主要用于保证信息的完整性。常见的MD5算法、散列函数、哈希函数都属于这类算法,其特点就是单向性、无法反推原文
假如信息被截取,并重新生成了摘要,这时候就判断不出来是否被篡改了,所以需要给摘要也通过会话密钥进行加密,这样就看不到明文信息,保证了安全性,同时也保证了完整性
如何保证数据不被篡改?签名原理和证书?
数字证书(数字签名)
它可以帮我们验证服务器身份。因为如果没有验证的话,就可能被中间人劫持,假如请求被中间人截获,中间人把他自己的公钥给了客户端,客户端收到公钥就把信息发给中间人了,中间人解密拿到数据后,再请求实际服务器,拿到服务器公钥,再把信息发给服务器
这样不知不觉间信息就被人窃取了,所以在结合对称和非对称加密的基础上,又添加了数字证书认证的步骤,让服务器证明自己的身份
数字证书需要向有权威的认证机构(CA)获取授权给服务器。首先,服务器和CA机构分别有一对密钥(公钥和私钥),然后是如何生成数字证书的呢?
- CA机构通过摘要算法生成服务器公钥的摘要(哈希摘要)
- CA机构通过CA私钥及特定的签名算法加密摘要,生成签名
- 把签名、服务器公钥等信息打包放入数字证书,并返回给服务器
服务器配置好证书,以后客户端连接服务器,都先把证书发给客户端验证并获取服务器的公钥。
证书验证流程:
- 使用CA公钥和声明的签名算法对CA中的签名进行解密,得到服务器公钥的摘要内容
- 再用摘要算法对证书里的服务器公钥生成摘要,再把这个摘要和上一步得到的摘要对比,如果一致说明证书合法,里面的公钥也是正确的,否则就是非法的
证书认证又分为单向认证和双向认证
单向认证:服务器发送证书,客户端验证证书
双向认证:服务器和客户端分别提供证书给对方,并互相验证对方的证书
不过大多数https服务器都是单向认证,如果服务器需要验证客户端的身份,一般通过用户名、密码、手机验证码等之类的凭证来验证。只有更高级别的要求的系统,比如大额网银转账等,就会提供双向认证的场景,来确保对客户身份提供认证性
解决上述身份验证问题的关键是确保获取的公钥途径是合法的,能够验证服务器的身份信息,为此需要引入权威的第三方机构CA(如沃通CA)。CA 负责核实公钥的拥有者的信息,并颁发认证"证书",同时能够为使用者提供证书验证服务,即PKI体系(PKI基础知识)。
基本的原理为,CA负责审核信息,然后对关键信息利用私钥进行"签名",公开对应的公钥,客户端可以利用公钥验证签名。CA也可以吊销已经签发的证书,基本的方式包括两类 CRL 文件和 OCSP。CA使用具体的流程如下:

- 服务方S向第三方机构CA提交公钥、组织信息、个人信息(域名)等信息并申请认证;
- CA通过线上、线下等多种手段验证申请者提供信息的真实性,如组织是否存在、企业是否合法,是否拥有域名的所有权等;
- 如信息审核通过,CA会向申请者签发认证文件-证书。 证书包含以下信息:申请者公钥、申请者的组织信息和个人信息、签发机构CA的信息、有效时间、证书序列号等信息的明文,同时包含一个签名; 签名的产生算法:首先,使用散列函数计算公开的明文信息的信息摘要,然后,采用CA的私钥对信息摘要进行加密,密文即签名;
- 客户端 C 向服务器 S 发出请求时,S 返回证书文件;
- 客户端 C 读取证书中的相关的明文信息,采用相同的散列函数计算得到信息摘要,然后,利用对应CA的公钥解密签名数据,对比证书的信息摘要,如果一致,则可以确认证书的合法性,即公钥合法;
- 客户端然后验证证书相关的域名信息、有效时间等信息;
- 客户端会内置信任CA的证书信息(包含公钥),如果CA不被信任,则找不到对应 CA的证书,证书也会被判定非法。
- 在这个过程注意几点:
- 申请证书不需要提供私钥,确保私钥永远只能服务器掌握;
- 证书的合法性仍然依赖于非对称加密算法,证书主要是增加了服务器信息以及签名;
- 内置 CA 对应的证书称为根证书,颁发者和使用者相同,自己为自己签名,即自签名证书(为什么说"部署自签SSL证书非常不安全")
- 证书=公钥+申请者与颁发者信息+签名;
免费获取CA证书的几种方式
- 从相关商业机构申请,以阿里云为例:

- 使用证书工具生成(Keytool或者Openssl): 详见实操部分
HTTPS 连接过程和优化
RSA握手
早期的TLS密钥交换法都是使用RSA算法,它的握手流程是这样子的
- 浏览器给服务器发送一个随机数client-random和一个支持的加密方法列表
- 服务器把另一个随机数server-random、加密方法、公钥传给浏览器
- 浏览器又生成另一个随机数pre-random,并用公钥加密后传给服务器
- 服务器再用私钥解密,得到pre-random,此时浏览器和服务器都得到三个随机数了,各自将三个随机数用加密方法混合生成最终密钥
然后开始通信
TLS 1.2 版
TLS 1.2版的用的是ECDHE密钥交换法,看图

- 浏览器给服务器发送一个随机数client-random、TLS版本和一个支持的加密方法列表
- 服务器生成一个椭圆曲线参数server-params、随机数server-random、加密方法、证书等传给浏览器
- 浏览器又生成椭圆曲线参数client-params,握手数据摘要等信息传给服务器
- 服务器再返回摘要给浏览器确认应答
这个版本不再生成椭圆曲线参数cliend-params和server-params,而是在服务器和浏览器两边都得到server-params和client-params之后,就用ECDHE算法直接算出pre-random,这就两边都有了三个随机数,然后各自再将三个随机加密混合生成最终密钥
- 要保证传输的密钥只能被服务器解密,就得保证用于加密密钥的公钥一定是服务器下发的,绝对不可能被第三方篡改过;
- 如果没有证书验证,下面的劫持就很有可能发生。
HTTPS中间人攻击示意图:
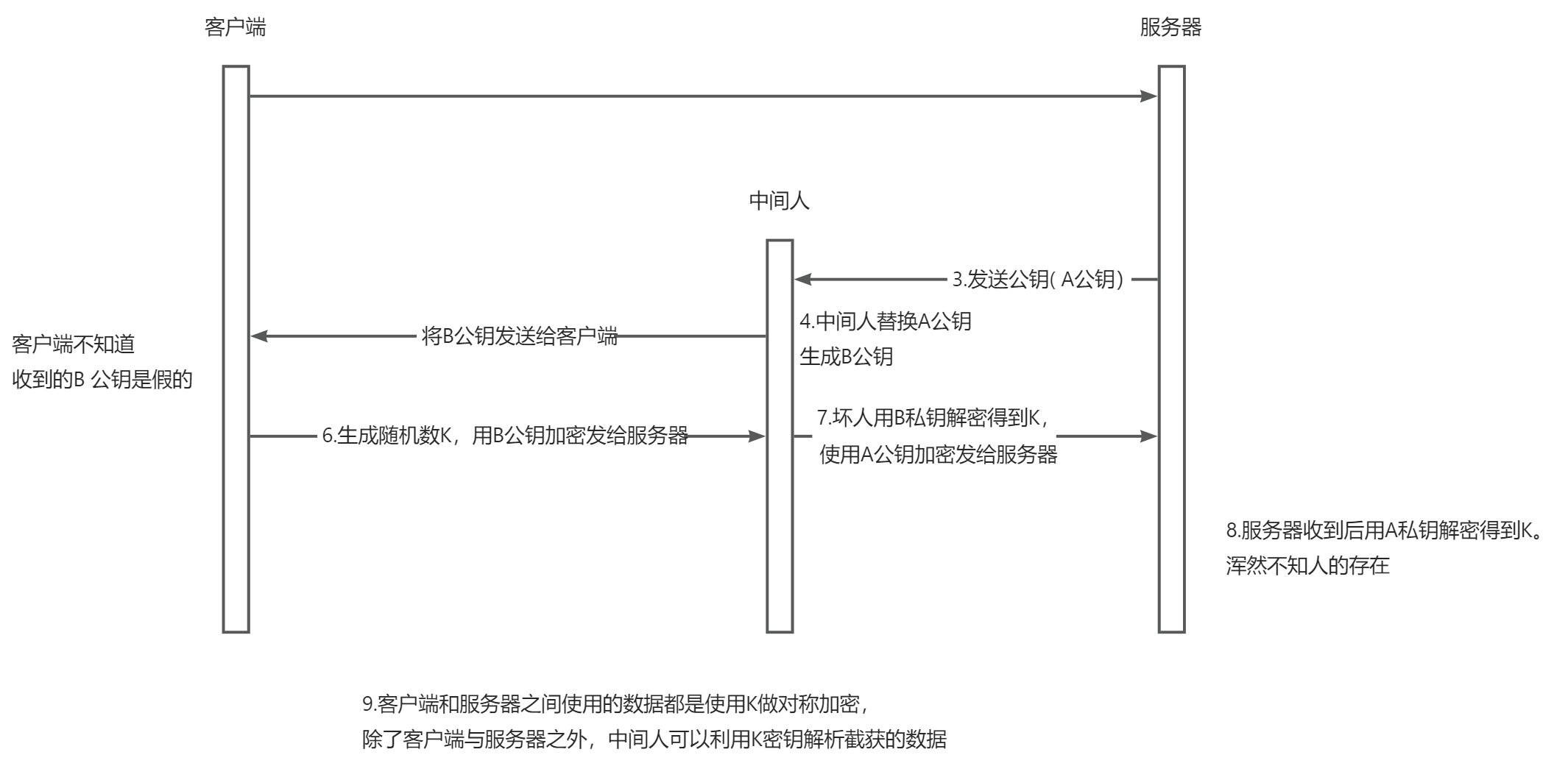
(现在阿里云CA证书认证免费,基本上大多数网站都有认证证书。)
实验分析TLS v1.2握手
抓包验证:

Wireshark流量图展示效果。


上下图对照即可进行数据流的分析。
TLS 1.3版
在TLS1.3版本中废弃了RSA算法,因为RSA算法可能泄露私钥导致历史报文全部被破解,而ECDHE算法每次握手都会生成临时的密钥,所以就算私钥被破解,也只能破解一条报文,而不会对之前的历史信息产生影响,,所以在TLS 1.3中彻底取代了RSA。目前主流都是用ECDHE算法来做密钥交换的
TLS1.3版本中握手过程是这样子的 
- 浏览器生成client-params、和client-random、TLS版本和加密方法列表发送给服务器
- 服务器返回server-params、server-random、加密方法、证书、摘要等传给浏览器
- 浏览器确认应答,返回握手数据摘要等信息传给服务器
简单说就是简化了握手过程,只有三步,把原来的两个RTT打包成一个发送了,所以减少了传输次数。这种握手方式也叫1-RTT握手
这种握手方还有优化空间吗?
有的,用会话复用
会话复用
会话复用有两种方式:Session ID 和 Session Ticket
Session ID:就是客户端和服务器首次连接手各自保存会话ID,并存储会话密钥,下次再连接时,客户端发送ID过来,服务器这边再查找ID,如果找到了就直接复用会话,密钥也不用重新生成
可是这样的话,在客户端数量庞大的时候,对服务器的存储压力可就大了
所以出来了第二种方式 Session Ticket:就是双方连接成功后服务器加密会话信息,用Session Ticket消息发给客户端存储起来,下次再连接时就把这个Session Ticket解密,验证有没有过期,如果没有过期就复用会话。原理就是把存储压力分给客户端。
这样就万无一失了吗?
No,这样也存在安全问题。因为每次要用一个固定的密钥来解密Session Ticket,一旦密钥被窃取,那所有历史记录也就被破解了,所以只能尽量避免这种问题定期更换密钥。毕竟节省了不少生成会话密钥和这些算法的耗时,性能还是提升了嘛
那刚说了1-RTT,那能不能优化到0-RTT呢
还真可以,做法就是发送Session Ticket的时候带上应用数据,不用等服务端确认。这种方式被称为PSK(Pre-Shared Key)
这样万无一失了吗?
尴了个尬,还是不行。这PSK要是被窃取,人家不断向服务器重发,就直接增加了服务器被攻击的风险
虽然不是绝对安全,但是现行架构下最安全的解决文案了,大大增加了中间人的攻击成本
HTTPS优缺点
优点
- 内容加密,中间无法查看原始内容
- 身份认证,保证用户访问正确。如访问百度,即使DNS被劫持到第三方站点,也会提醒用户没有访问百度服务,可能被劫持
- 数据完整性,防止内容被第三方冒充或篡改
- 虽然不是绝对安全,但是现行架构下最安全的解决文案了,大大增加了中间人的攻击成本
缺点
- 要钱,功能越强大的证书费用越贵
- 证书需要绑定IP,不能在同一个IP上绑定多个域名
- https双方加解密,耗费更多服务器资源
- https握手更耗时,降低一定用户访问速度(优化好就不是缺点了)
HTTP 和 HTTPS 的区别
- HTTP是明文传输,不安全的,HTTPS是加密传输,安全的多
- HTTP标准端口是80,HTTPS标准端口是443
- HTTP不用认证证书免费,HTTPS需要认证证书要钱
- 连接方式不同,HTTP三次握手,HTTPS中TLS1.2版本7次,TLS1.3版本6次
- HTTP在OSI网络模型中是在应用层,而HTTPS的TLS是在传输层
- HTTP是无状态的,HTTPS是有状态的
本次学习内容鸣谢:
1.HTTP发展史
2. HTTP成长史
3. 20分钟助你拿下HTTP和HTTPS,巩固你的HTTP知识体系
4. PKI(HTTPS)体系详解 PKI是什么















 2327
2327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









