







Windows本地Hadoop环境及Idea调试
前提需要
所需要的文件
1.Hadoop
2.Java
3.替换文件
本机用的Hadoop是hadoop2.7.2,Java是1.8.0_202
替换文件下载地址:https://github.com/cdarlint/winutils
百度云盘:Hadoop
Java环境安装在本地D:\software\Java\jdk1.8.0_202
Hadoop环境安装在本地D:\Hadoop\hadoop
配置环境变量
搜索栏搜索环境变量,并双击打开

Hadoop和Java的环境变量配置

完成之后在配置path变量
找到path双击或编辑

弹出以下窗口,将Hadoop下的sbin和bin目录,以及Java的bin和Java的jre下的bin添加到path变量

完成之后点击确定
打开cmd,依次输入java -version和hadoop version查看安装版本号,即完成好了Java和Hadoop的安装

替换文件
将下载下来的替换文件进行替换操作

找到与之对呀的hadoop版本号,将bin目录下的所有文件CTRL+A全部选中,CTRL+C全部选中之后复制,

进入你所安装的Hadoop的bin目录,将刚刚复制好的文件全部粘贴覆盖到自己安装的Hadoop下的bin目录下,选择替换目标中的文件

修改配置文件

同理,进入Hadoop下的etc/hadoop目录下,修改hadoop-env.cmd文件

接下来就是配置Hadoop相关文件了
core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml三个文件
路径按照自己实际情况来改
core-site.xml文件内容如下
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/Hadoop/hadoop/tmp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/D:/Hadoop/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml文件内容如下
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/Hadoop/hadoop/data</value>
</property>
</configuration>mapred-site.xml文件内容如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>yarn-site.xml文件内容如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>以上步骤完成之后,打开cmd窗口,执行hadoop namenode -format进行对namenode格式化,只需要进行一次格式化,后面就不需要了
格式化完成之后就可以执行:start-dfs.cmd命令启动Hadoop了,会启动几个进程窗口

打开浏览器输入:localhost:50070打开web界面
 进入idea进行本地环境调试
进入idea进行本地环境调试
创建maven工程项目,编辑pom.xml下载Hadoop相关依赖包
编写Java代码,这里编写的是mapreduce的单词计数进行测试
WordCount.java代码如下
package WordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
class MyMapper extends Mapper <LongWritable, Text,Text, IntWritable>{
Text word = new Text();
IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key,Text value,Context context)
throws IOException,InterruptedException {
//1
String line = value.toString();
//2
String[] words = line.split(" ");
//3
for (String s : words) {
word.set(s);
context.write(word, one);
}
}
}
class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//1
Integer counter = 0;
//2
for (IntWritable value : values) {
counter += value.get();
}
context.write(key, new IntWritable(counter));
}
}
public class WordCount {
public static void main(String[] args) throws Exception{
if (args == null || args.length < 2){
throw new Exception("参数不足,需要两个参数!");
}
//1
Configuration conf = new Configuration();
// conf.set("fs.defaultFS","hdfs://localhost:9000"); /*如果是本地的话,就需要将此行注释*/
//2
Job job= Job.getInstance(conf,"WordCount");
job.setJarByClass(WordCount.class);
//3
Path inPath = new Path(args[0]);
FileInputFormat.addInputPath(job,inPath);
//4
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6
Path outPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outPath);
//7
System.out.println("程序运行完成!\n输出文件保存至当前目录下的output目录下");
System.exit(job.waitForCompletion(true) ? 0: 1);
}
}设置文件的输入输出路径
 这里我设置的输入文件在当前工作环境目录的input目录,输出目录为output目录
这里我设置的输入文件在当前工作环境目录的input目录,输出目录为output目录
 然后点击ok,再当前工作目录下新建input目录,再在input下创建一个word.txt文件,写入一些内容
然后点击ok,再当前工作目录下新建input目录,再在input下创建一个word.txt文件,写入一些内容


同理,然后在新建的input目录右键,new新建一个文件


然后在word.txt文件随便写入内容,文件名可以自己随意取,建议命名见名知意
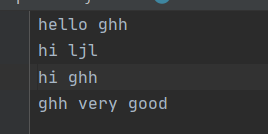
word.txt文件内容
然后点击run运行程序
程序运行完成之后会在刚刚设置的输出目录下生成输出文件

写在最后
我将Hadoop和Java已经完成好的文件上传至百度云盘,如有需要的,提供了百度云盘下载链接可以直接下载使用
链接:https://pan.baidu.com/s/1TJwLyz9MGAkyJhqB_RelgQ?pwd=0000
提取码:0000
使用说明:
本人使用的Hadoop是安装在D盘下的Hadoop,Java是安装在D盘的software下的Java
建议下载的压缩包直接解压至D盘根目录即可,就无需更改里面的配置,也无需进行格式化操作,只要将环境变量配置到自己的电脑上就可以直接使用了,然后直接使用cmd终端使用启动命令就可以了
如果下载之后Hadoop安装在不同位置的,需要根据自己的情况去更改一些配置
比如要更改hadoop-cmd,hadoop-env.cmd,core-site.xml,hdfs-site.xml,mapred-site.xml和yarn-site.xml
















 2637
2637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











