









一、基本内容
requests.get( )方法
1.至少有一个参数。(接口的地址)
2.有返回值的方法。返回值就是本次请求的服务器响应结果
二、发送一个不带参数的Get请求
案例代码:
#导包
import requests
#构造get请求
res=requests.get("http://www.baidu.com")
#设置字符编码
res.encoding="utf-8"
#打印输出
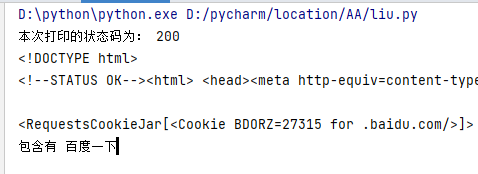
print("本次打印的状态码为:",res.status_code)
print(res.text)
print(res.cookies)
#断言
exp="百度一下"
if exp in res.text:
print("包含有",exp)
else:
print("不存在")
运行结果:
三、发送一个带参数的Get/Post请求
1.构造参数值;
2.获取和输出各种响应值
构造一个参数表,必须是字典形式
构造请求:
res=requests.get(‘请求地址’,params=构造参数)
res=requests.post(‘请求地址’,data=构造参数)
案例代码(百度翻译):
import requests
#设置接口地址
url="http://api.fanyi.baidu.com/api/trans/vip/translate"
#以字典形式的请求数据和参数
data={
'q':'apple', #需要翻译的文本
'from':'auto',
'to':'zh', #翻译成中文
'appid':'20200211000382774',
'salt':'202002',
'sign':'11678af9bf6f90efff2dd377832c6317'
}
#构造并发送请求
res=requests.post(url,data=data)
res.encoding='utf-8'
#输出文本内容
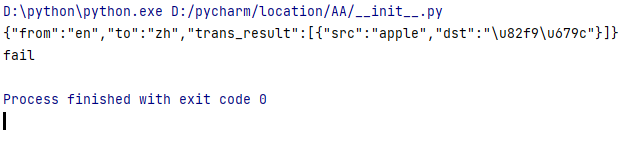
print(res.text)
#断言
exp='apple'
if exp in res:
print('pass')
else:
print("fail")
运行结果:
四、结果json化响应
将结果转化为json的格式
requests中response.json()方法等同于json.loads(response.text)方法。
如果是对象(字典):键值对的方式去阅读
例(tra_result=result[‘trans_result’])
如果是数组:可以使用下标的方式去查找元素并阅读
例(tra_result=result[1])
案例代码:
import requests
url="http://api.fanyi.baidu.com/api/trans/vip/translate"
data={
'q':'apple',
'from':'auto',
'to':'zh',
'appid':'20200211000382774',
'salt':'202002',
'sign':'11678af9bf6f90efff2dd377832c6317'
}
res=requests.post(url,data=data)
#未对结果进行json化
print(res.text)
#对结果json化
print(res.json())
#json化
rj=res.json()
#打印输出
print(rj)
print(rj['trans_result'][0]['dst'])
#断言
'''
exp='apple'
if exp in res:
print('pass')
else:
print("fail")
'''
运行结果:
五、实战案例(百度翻译,输入文本直接输出译文)
import hashlib
import random
import requests
encodings='utf-8'
#MD5编码函数
def getmd5(be_sign):
m2=hashlib.md5()
m2.update(be_sign.encode(encodings))
return m2.hexdigest()
#翻译函数
def tra_baidu():
url='http://api.fanyi.baidu.com/api/trans/vip/translate'
appid='20200211000382774'
key='b1imCNk_EdXIHM0zX2bD'
salt=str(random.randint(1000,9999))
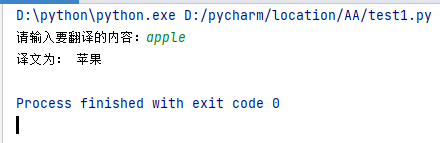
q=input('请输入要翻译的内容:')
tra_from='auto'
tra_to = 'zh'
be_sign=appid+q+salt+key
sign=getmd5(be_sign)
data={
'q':q,
'from':tra_from,
'to':tra_to,
'appid':appid,
'salt':salt,
'sign':sign
}
res=requests.post(url,data=data)
result=res.json()
#只输出译文
tra_result=result['trans_result'][0]['dst']
print('译文为:',tra_result)
#执行翻译体函数
tra_baidu()
运行结果:














 1810
1810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









