









标题:Intellij IDEA 设置JDK版本,同时安装Java11,1.8,1.6
补充 jdk、jre版本不一致出现的问题,正常是不会出现的(可以不看)
这里以安装jdk1.6为例子
一、下载、安装jdk
注:如果只是想切换在idea中切换jdk的话,可以不用修改 系统的中环境变量,也就是下载安装jdk、jre即可。
如下:这是我的jdk安装包路径
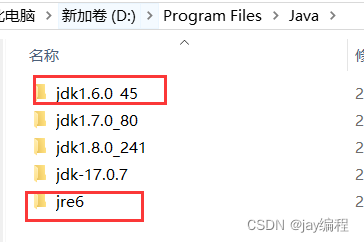
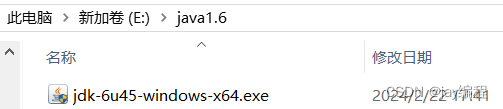 这是我的jdk、jre实际安装路径
这是我的jdk、jre实际安装路径
二、在idea中配置jdk的路径

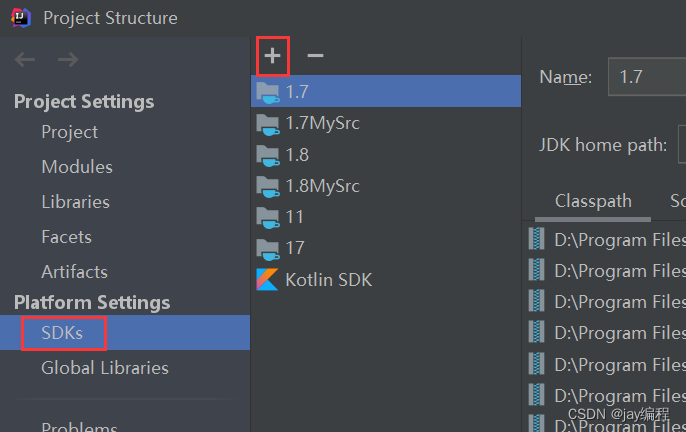

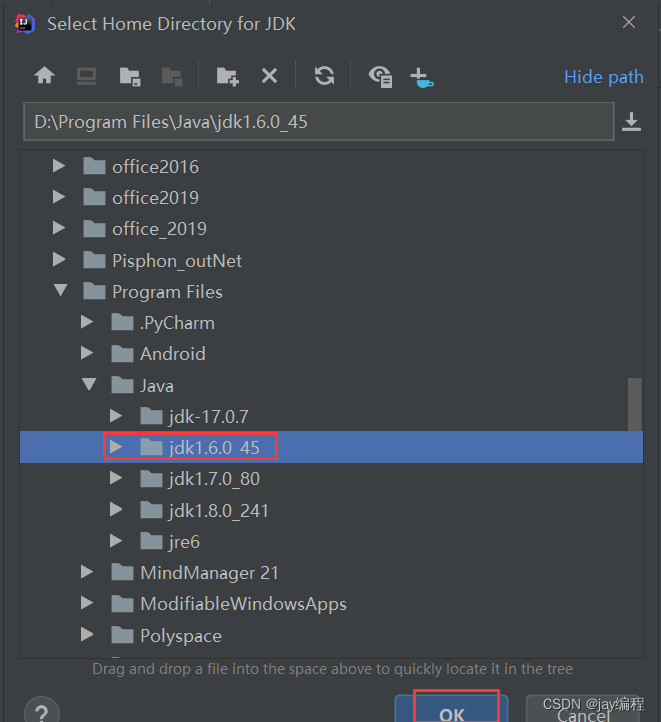
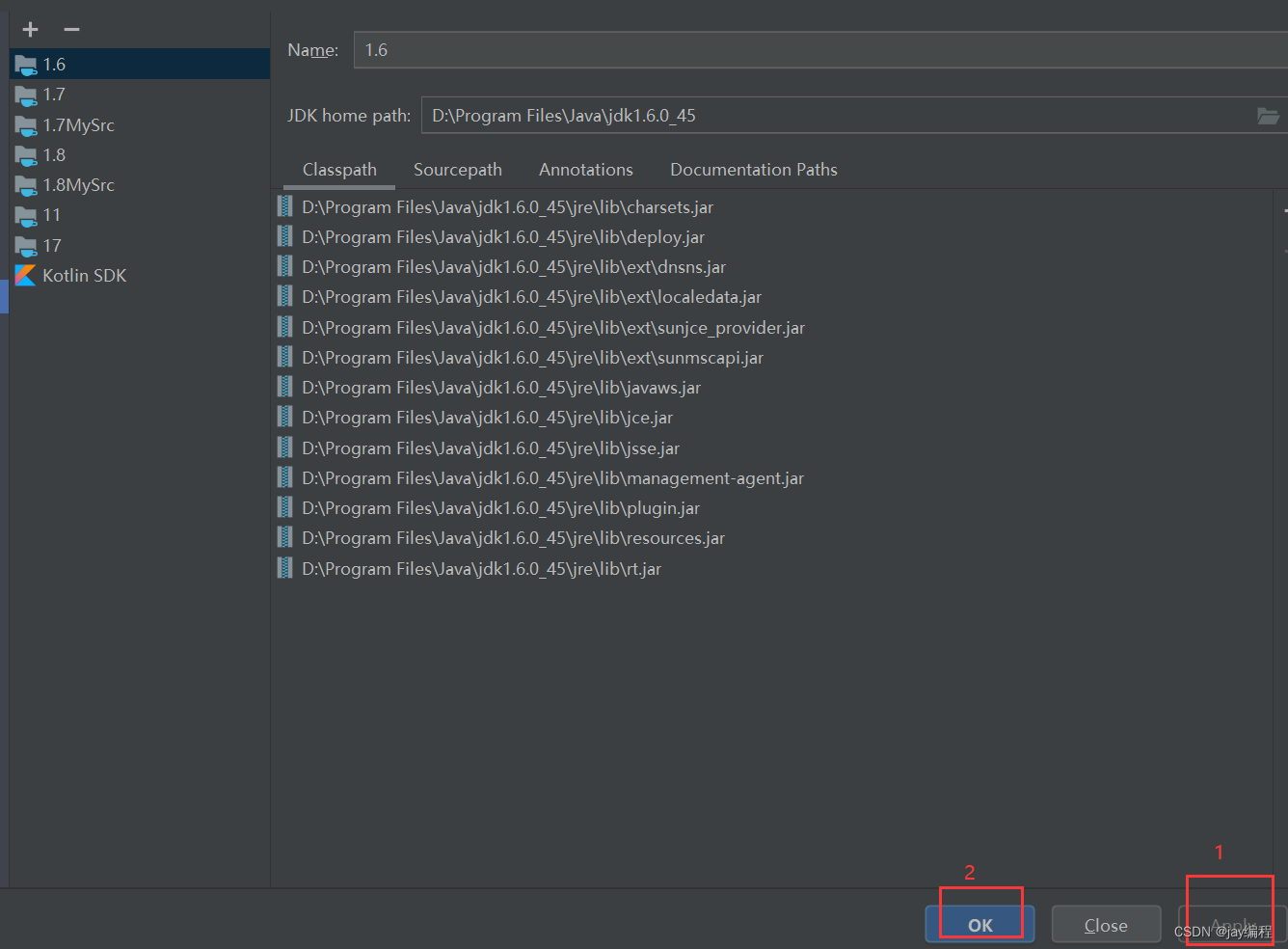
此时,jdk1.6 在idea中已经配置好了
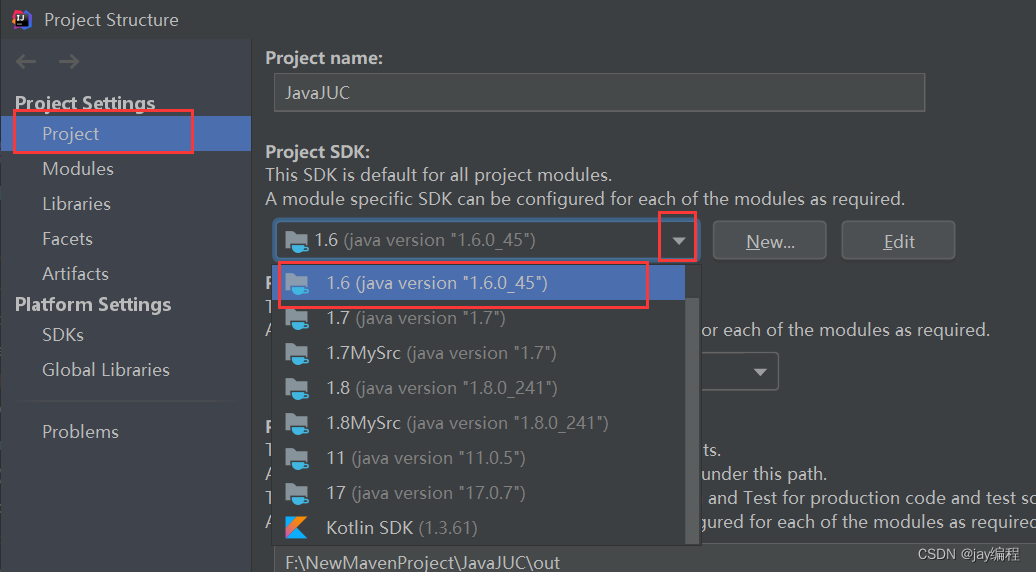
三、选择你需要使用的jdk
如下,我可以选择我想要的jdk版本

















 3394
3394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









