










初识爬虫,需要有一定的网络知识
import requests #没有的话就直接下载,pip install requests
url = "你想爬取的网页"
headers ={"User-Agent":"在你浏览器用开发者模式查看NetWork然后刷新网页再在Headers中找寻"}
如图 ,格式要注意,User-Agent中间的是冒号,
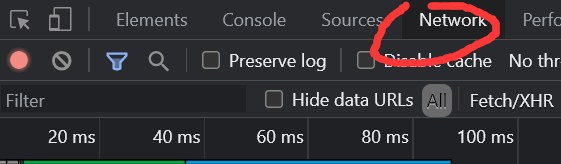
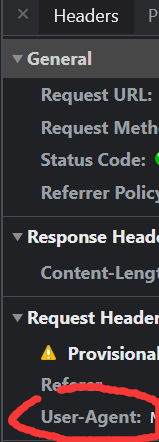
User-Agent也可直接网页搜到。
# 获取响应体
rep = requests.get(url=url,headers=headers)
html = rep.text # 拿到了网页
之后就需要对网页数据处理了















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









