






若是有想从事软件测试岗的朋友,面试前可以准备如下资料。
一、准备自我介绍
这个我理解是通用的,不管你是要面试开发、产品、测试,还是说其它岗位。提前背熟一下自己的基本情况:如专业、毕业学校、就职过的公司、以前熟悉的测试类型等;另外,若是面试的对英语有要求,建议用英文写好自我介绍的内容,然后背熟。其次,有时间的话可以设想一下面试官用英文提问的内容用英文作答写好背熟。
二、基础知识-SQL语句
增删改查,详细内容也可参考另一篇SQL的文章。
1、查询记录(查)
语法 select,如下:
SQL:关系型数据库的结构化查询语言(structured query language)
select ----需看什么
* ----字段或全部
from ------从哪看
database.table ------------数据库.数据表
实例:取出user_class表中的所有字段的所有记录,并按照age倒排序
select * from user_class ORDER BY age desc;
2、插入(增)-增加记录:
INSERT VALUES 的语法格式为:
INSERT INTO <表名> [ <列名1> [ , … <列名n>] ]
VALUES (值1) [… , (值n) ];
use dewi_practice
insert into Employee
values(002,'王子行','男','26'),
(001,'王子','男','26');
3、update(改)-修改记录
UPDATE [LOW_PRIORITY] [IGNORE] tbl_name
SET col_name1=expr1 [, col_name2=expr2 ...]
[WHERE where_definition]
[ORDER BY ...]
[LIMIT row_count]
#需要增加薪水的,更新语句
update salaries set
salary = salary*1.1
where to_date='9999-01-01'
and emp_no in(
select emp_no
from emp_bonus
)
5、DELETE(删)
语句删除数据的通用语法:
DELETE FROM <表名> [WHERE 子句][ORDER BY 子句][LIMIT 子句]
- <表名>:指定要删除数据的表名;
- ORDER BY 子句:可选项。表示删除时,表中各行将按照子句中指定的顺序进行删除;
- WHERE 子句:可选项。表示为删除操作限定删除条件,若省略该子句,则代表删除该表中的所有行;
- LIMIT 子句:可选项。用于告知服务器在控制命令被返回到客户端前被删除行的最大值。
- 【根据条件删除数据】
- 在test表中,删除Name为王发林的记录,SQL如下
- DELETE FROM test WHERE NAME = "王发林";
另外,数据库操作删除的几个方法和不同点:
【TRUNCATE 】
TRUNCATE关键字用于完全清空一个表。语法如下
TRUNCATE [TABLE] 表名
使用TRUNCATE语句清空 test表中的记录,SQL如下
TRUNCATE TABLE test;
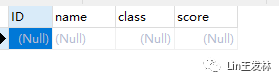
DELETE关键词和TRUNCATE的区别
- DELETE关键词是属于DML语句;TRUNCATE关键词属于DDL语句。但是它们的作用都用来清空数据表中的数据;
- DELETE关键词是逐条记录一条一条的删除记录;而TRUNCATE是直接删除原来的表,然后再重新创建一个字段结果完全一样的新表格,执行数据比DELETE快;
- DELETE删除数据后,可以找回数据;但是TRUNCATE不支持回滚,删除数据后无法找回;
- DELETE可以通过WHERE子句指定条件来删除部分数据;而TRUNCATE只能删除整体;
- DELETE会返回删除数据的行数,但是TRUNCATE只会返回 0,没有任何意义。
当不需要该表时,用DROP;当仍要保留该表,但要删除所有记录时,用TRUNCATE;当要删除部分记录时,用DELETE。
所以权限大小:DROP > TRUNCATE > DELETE
6、联表查询
另外,就是连表查询。这个在另一篇有详细说明。如left join on 规则:
左连接,左表全部展示,
左表中的第一行与右表的每一行依次对比,符合条件的保留下来,
左表中的第二行与右表的每一行依次对比,符合条件的保留下来,
......
右表有值的展示,(对应左表的可能多条),右表轮询后无对应的值时显示null(一条)
三、基础知识-测试案例的设计方法
1、黑盒测试用例设计方法
1)等价类划分法
这里不详细展开,直接举例:
如:输入值是学生成绩,范围是0~100;如下图,可以测试3条用例:一个有效等价类,2个无效等价类

2)边界值分析法
例如某页面最多可配置10张图片,这样可以测试边界值9,10,11
配置不同的图片检查展示结果。
3)错误推测法
例如,测试手机终端的通话功能,可以设计各种通话失败的情况来补充测试用例:
a) 无SIM 卡插入时进行呼出(非紧急呼叫)
b) 插入已欠费SIM卡进行呼出
c) 射频器件损坏或无信号区域插入有效SIM卡呼出
d) 网络正常,插入有效SIM卡,呼出无效号码(如1、888、333333、不输入任何号码等)
e) 网络正常,插入有效SIM卡,使用“快速拨号”功能呼出设置无效号码的数字
4)因果图法
一般步骤:分析需求,画出因果图,有无约束条件,整理表格,设计测试用例
实例:自动售货机
有一个处理单价为5角钱的饮料的自动售货机软件测试用例的设计。其规格说明如下:若投入5角钱或1元钱的硬币,押下〖橙汁〗或〖啤酒〗的按钮,则相应的饮料就送出来。若售货机没有零钱找,则一个显示〖零钱找完〗的红灯亮,这时在投入1元硬币并押下按钮后,饮料不送出来而且1元硬币也退出来;若有零钱找,则显示〖零钱找完〗的红灯灭,在送出饮料的同时退还5角硬币。
a) 分析这一段说明,列出原因和结果
原因:
1——售货机有零钱找
2——投入1元硬币
3——投入5角硬币
4——押下橙汁按钮
5——.押下啤酒按钮
结果:
21——售货机〖零钱找完〗灯亮
22——退还1元硬币
23——退还5角硬币
24——送出橙汁饮料
25——送出啤酒饮料
b) 画出因果图,如图所示。所有原因结点列在左边,所有结果结点列在右边。建立中间结点,表示处理的中间状态。中间结点:
11—— 投入1元硬币且押下饮料按钮
12——押下〖橙汁〗或〖啤酒〗的按钮
13——应当找5角零钱并且售货机有零钱找
14——钱已付清

c) 转换成判定表:

d) 在判定表中,阴影部分表示因违反约束条件的不可能出现的情况,删去。第16列与第32列因什么动作也没做,也删去。最后可根据剩下的16列作为确定测试用例的依据。
5)场景图法
基本流和备选流:
主要是通过基本流和备选流来测试。这个对于业务逻辑很实用。
如下图所示,图中经过用例的每条路径都用基本流和备选流来表示,直黑线表示基本流,是经过用例的最简单的路径。备选流用不同的色彩表示,一个备选流可能从基本流开始,在某个特定条件下执行,然后重新加入基本流中(如备选流1和3);也可能起源于另一个备选流(如备选流2),或者终止用例而不再重新加入到某个流(如备选流2和4)。

其它像功能图法、正交试验法、判定表驱动法也可以同步学习一下,这里不一一介绍了。
2、白盒测试用例设计方法
笔者工作中没有实际用到就不详细讲了。主要方法如下:
1)代码检查法
2)静态结构分析法
3)逻辑覆盖法
4)基本路径测试法
3、接口测试设计方法
其实黑盒测试设计方法也适用于接口测试。另外,设计接口测试用例需要考虑以下几个方面:
a、是否满足前提条件
有些接口需要满足前置条件,才可成功获取数据。常见的,需要登陆Token。
逆向用例:
针对是否满足前置条件(假设为n个条件),设计0~n条用例
b、是否携带默认值参数
正向用例:
带默认值的参数都不填写、不传参,必填参数都填写正确且存在的“常规”值,其它不填写,设计1条用例;
c、业务规则、功能需求
这里根据实际情况,结合接口参数说明,可能需要设计n条正向用例和逆向用例
d、参数是否必填
逆向用例:
针对每个必填参数,都设计1条参数值为空的逆向用例
e、参数之间是否存在关联
有些参数彼此之间存在相互制约的关系
逆向用例:
根据实际情况,可能需要设计0~n条用例
f、参数数据类型限制
逆向用例:
针对每个参数都设计1条参数值类型不符的逆向用例
g、参数数据类型自身的数据范围值限制
四、自动化测试相关问题
1、selenium 如何做到支持多浏览器
用驱动不同
2、使用try…except 可以抛出异常如何实现
例子:
try: driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[1]/div/ul/section/li[3]/div[2]/ul/section/li[2]/div[1]/i' ).click() except Exception as msg: print("点击营销中心异常:%s"%msg)
3、expected_conditions作用
事先判断
是selenium的一个模块,可以对网页上元素进行判断,一般配合WebDriverWait使用。
4,显式等待和隐式等待的作用和区别
1)显式等待:用于等待某个条件发生,然后再继续执行后续代码。显式等待是等元素加载
from selenium.webdriver.support.wait import WebDriverWait #显示等待
cancel_btn = driver.find_element_by_xpath('/html/body/div[7]/div[2]/div/div/div[3]/div/button[2]/span') #超时时间10秒,每1秒查询一次,只到元素存在 locate = WebDriverWait(driver,1,1).until(EC.visibility_of(cancel_btn))
2)隐式等待:
b,相当于设置全局的等待,在定位元素时,对所有元素设置超时时间。
d,隐式等待是等页面加载,而不是元素加载(隐式等待就是针对页面的,显式等待是针对元素的)缺点就是:我们在定位元素时,有时页面中用到的元素已经加载完毕,但是任然还在等待,需要等待全部加载完毕才能下一步;
#隐式等待,等待页面的加载 driver.implicitly_wait(10)
c,隐性等待,最长时间10s,在这个时间加载完毕后会立即进行下一步,超出这个时间抛出异常
a,对driver 起作用,只有设置一次,不用到处设置
3)强制等待
即是程序暂停时间。。。
使用time.sleep(3) 固定的等待时间,时间设置太短元素或页面未加载会报错
设置时间太长会浪费时间。尽量少用
不管资源是否完成,都按固定时间等待
5,如何提高selenium脚本的执行速度?
1)少用sleep
2)多用显式等待方法
3)性能好的电脑执行
4)实现多线程。在编写测试用例的时候,一定要实现松耦合,然后在服务器允许的情况下,设置多线程运行,提高执行速度
5)导入的模块不要随意,只导入需要的部分
6)另外从代码方面提高python的运行效率
使用生成器,因为可以节约大量内存 循环代码优化,避免过多重复代码的执行 核心模块用Cython PyPy等,提高效率 多进程、多线程、协程 多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
6,用例在运行过程中经常会出现不稳定的情况,也就是这次可以通过,下次无法通过了?
显示等待WebDriverWait() + 元素判断expected_conditions()
1,查找元素前先做判断:expected_conditions()里面的各种方法
2,显式等待:WebDriverWait()
这两者配合使用
3、可以考虑尝试多种定位方式
7、WEB界面元素定位,一闪而过(几秒自动消失)的弹框如何定位?
操作步骤:
因为闪退弹窗速度比较快,需要按如下步骤操作:
1)在打开的浏览器中按F12 ,选择Sources;
2)操作触发弹窗步骤;
3) 鼠标按下暂停图标(pause) 或快捷键(Ctrl+\),这样弹窗就暂停了,不会闪退了(这里如果动作慢也可能定位不到,就需要重复步骤2)和3)了);
显示等待加ec,若是不好定位,找开发加上元素唯一的id 或者name
8、你的自动化用例的执行策略是什么?
集成到jenkins一键执行,可以手动执行,也可以定时执行
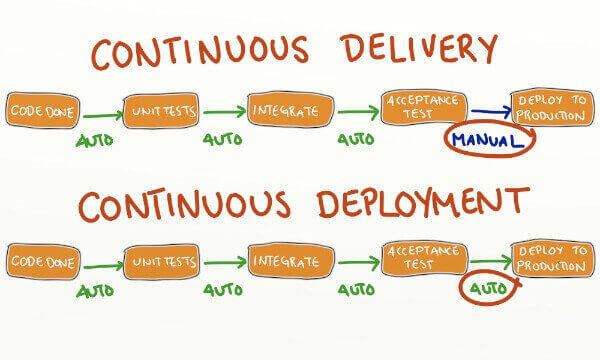
9、持续集成CI原理
互联网软件的开发和发布,已经形成了一套标准流程,最重要的组成部分就是持续集成(Continuous integration,简称CI)。
一、概念
持续集成指的是,频繁地(一天多次)将代码集成到主干。
它的好处主要有两个。
(1)快速发现错误。每完成一点更新,就集成到主干,可以快速发现错误,定位错误也比较容易。
(2)防止分支大幅偏离主干。如果不是经常集成,主干又在不断更新,会导致以后集成的难度变大,甚至难以集成。
持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。
Martin Fowler说过,"持续集成并不能消除Bug,而是让它们非常容易发现和改正。"
与持续集成相关的,还有两个概念,分别是持续交付和持续部署。
二、持续交付
持续交付(Continuous delivery)指的是,频繁地将软件的新版本,交付给质量团队或者用户,以供评审。如果评审通过,代码就进入生产阶段。
持续交付可以看作持续集成的下一步。它强调的是,不管怎么更新,软件是随时随地可以交付的。
三、持续部署#
持续部署(continuous deployment)是持续交付的下一步,指的是代码通过评审以后,自动部署到生产环境。
持续部署的目标是,代码在任何时刻都是可部署的,可以进入生产阶段。
持续部署的前提是能自动化完成测试、构建、部署等步骤。
四、流程#
根据持续集成的设计,代码从提交到生产,整个过程有以下几步。
a 提交
流程的第一步,是开发者向代码仓库提交代码。所有后面的步骤都始于本地代码的一次提交(commit)。
b测试(第一轮)
代码仓库对commit操作配置了钩子(hook),只要提交代码或者合并进主干,就会跑自动化测试。
测试有好几种。
-
单元测试:针对函数或模块的测试
-
集成测试:针对整体产品的某个功能的测试,又称功能测试
-
端对端测试:从用户界面直达数据库的全链路测试
第一轮至少要跑单元测试。
c 构建#
通过第一轮测试,代码就可以合并进主干,就算可以交付了。
交付后,就先进行构建(build),再进入第二轮测试。所谓构建,指的是将源码转换为可以运行的实际代码,比如安装依赖,配置各种资源(样式表、JS脚本、图片)等等。
常用的构建工具如下。
Jenkins和Strider是开源软件,Travis和Codeship对于开源项目可以免费使用。它们都会将构建和测试,在一次运行中执行完成。
d 测试(第二轮)
构建完成,就要进行第二轮测试。如果第一轮已经涵盖了所有测试内容,第二轮可以省略,当然,这时构建步骤也要移到第一轮测试前面。
第二轮是全面测试,单元测试和集成测试都会跑,有条件的话,也要做端对端测试。所有测试以自动化为主,少数无法自动化的测试用例,就要人工跑。
需要强调的是,新版本的每一个更新点都必须测试到。如果测试的覆盖率不高,进入后面的部署阶段后,很可能会出现严重的问题。
e 部署
通过了第二轮测试,当前代码就是一个可以直接部署的版本(artifact)。将这个版本的所有文件打包( tar filename.tar * )存档,发到生产服务器。
生产服务器将打包文件,解包成本地的一个目录,再将运行路径的符号链接(symlink)指向这个目录,然后重新启动应用。这方面的部署工具有Ansible,Chef,Puppet等。
f 回滚
一旦当前版本发生问题,就要回滚到上一个版本的构建结果。最简单的做法就是修改一下符号链接,指向上一个版本的目录。
10、自动化测试的时候是不是需要连接数据库做数据校验?
1)UI自动化不需要:
一般不需要,特别重要的可以做,成本较高。。从unit>service>UI分层来说不需要做数据校验。。容易扯到业务测试验证
2)接口测试会需要:
一般需要的,校验数据
10、id,name,class,xpath,css selector这些属性,你最偏爱哪一种,为什么?
1,css,css语法简洁,定位快(xpath语法长,定位慢,还不稳定)
二者都可以在html中提取内容,但xpath可以提取xml的内容.
CSS选择器和Xpath的区别?
a,CSS表达式更加简洁,
b,css在chrom,火狐查找速度快一些,效率高一些,xpath在IE浏览器相对快一些(ie浏览器无论是css,xpath都比谷歌,火狐要慢)
c,CSS不支持文本搜索,XPATH支持文本搜索text()
d,xpath支持的函数特别多,CSS选择器支持的函数比较少,所以在复杂元素查找时候,xpath反而更加简洁,所以xpath功能更加强悍
什么时候用css,什么时候xpath?
当查找元素比较简单,用css没错,如果复杂,用xpath比较好
11,如何去定位页面上动态加载的元素?
WebDriverWait()显示等待方法循环去查询是否元素加载出来了
13,如何定位属性动态变化的元素?
1)先去找该元素不变的属性,要是都变,那就找不变的父元素,同层级定位(以不变应万变)
2)或者找开发加不变的id,name
JS实现,
通过相对位置来定位,比如xpath的轴
14,点击链接以后,selenium是否会自动等待该页面加载完毕?
1, 不会的。所以有的时候,当selenium并未加载完一个页面时再请求页面资源,则会误报不存在此元素。所以首先我们应该考虑判断,selenium是否加载完此页面。其次再通过函数查找该元素。
15,如果有时候因网络较慢或其他原因导致定位不到其他元素,如何提高覆盖率?
1),等待页面加载完成,隐式等待
2),等待元素显式等待
16、selenium中hidden或者是display = none的元素是否可以定位到?
可以定位到,但是无法操作!!!!!如果想操作使用js
隐藏元素
如下图有个输入框和一个登录的按钮,本来是显示的

元素的属性隐藏和显示,主要是 type="hidden" 和style="display: none;"属性来控制的,接下来在元素属性里面让它隐藏
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>这里有个按钮,是隐藏的
<!-- type="hidden" -->
<br>
输入账号<input id="yoyo" name="hello" type="hidden">
<!-- type="display: none;" -->
<br>
<button id="yy" name="heo" style="display: none;">登录</button>
<br>
<a hidden id="baidu" href="https://www.baidu.com">访问百度</a>
</p>
</body>
</html>
这样元素就不会显示了,也就是面试官所说的隐藏属性了

17、selenium中如何保证操作元素的成功率?也就是说如何保证我点击的元素一定是可以点击的?
1.)首先通过封装find方法,实现wait_for_element_ispresent(WebDriverWait)
2).在对页面进行click之前,先滚动到该元素(通过Js封装),避免在页面未加载完成前或是在下拉之后才能显示。
3.)不同方式进行定位,与expected_conditions判断方法封装,循环判断页面元素出现后再操作;
4).开发人员规范开发习惯,如给页面元素加上唯一的name,id等。
5)尽量使用专用环境,避免其他影响
18、如何设计高质量的自动化脚本
1)、使用四层结构实现业务逻辑、脚本、数据分离。
在搭建ui自动化框架,使用的是po设计模式,也就是把每一个页面所需要
操作的元素和步骤都封装成一个页面类中。然后使用selenium+unittest搭建
2)四层框架实现数据、脚本、业务逻辑分离(关键字驱动)。其中四层框架包括
基础层(BasePage)、业务逻辑层(Pages)、数据层(Data)、测试用例层(Testcase)
1.基础层(BasePage)
设计一个基本的Page类,所有页面皆继承该类。提供一个页面需要实现的基本功能及公共方法。
2.业务逻辑层(Pages)
按照PO设计模式,将每个页面抽象为一个类,放在Pages包里面,每个页面继承Basepage,可调用Data层数据,包括页面所有的操作对象属性和实现的功能
3.数据层(Data)
该层存放相关数据,例如:用户数据和密码。在测试用例可通过调用数层的数据来进行操作。
4.测试用例层(Testcases)
每一个测试用例testcase都对应Pages里面的一个页面,继承unnitest.TestCase类
通过调用对应页面类的方法,数据层的数据、增加断言(assert)来验证功能的正确性。
此外通过Jenkins自动执行测试、代码质量检测和部署到测试服务器、部署到生产服务器上
3).使用PO设计模式,将一个页面用到的元素和操作步骤封装在一个页面类中。如果一个元素定位发生了改变,我们只用修改这个页面的元素属性
4).对于页面类的方法,我们尽量从客户的正向逻辑去分析,方法中是一个独立场景,例如:登录到退出,而且不要想着把所有的步骤都封装在一个方法中。
5) 测试用例设计中,减少测试用例之间的耦合度。
19、webdriver client的原理是什么?
在selenium启动以后,driver充当了服务器的角色,跟client和浏览器通信,client根据webdriver协议发送请求给driver。driver解析请求,并在浏览器上执行相应的操作,并把执行结果返回给client.
20、webdriver的协议是什么?
WebDrive协议本身是http协议,数据传输使用json
21、启动浏览器的时候用到的是哪个webdriver协议?
-http、
22、什么是page object设计模式?
1.通俗来讲,把每个页面当成一个页面对象,页面层写定位元素方法和页面操作方法
2.用例层从页面层调用操作方法,写成用例
3.可以做到定位元素与脚本的分离
23、怎样去选择一个下拉框中的value=xx的option?
1.select类里面提供的方法:select_by_value(“xxx”)
2.xpath的语法也可以定位到
24、如何在定位元素后高亮元素(以调试为目的)?
-重置元素属性,给定位的元素加背景、边框
25、什么是断言和验证?
断言(assert):测试将会在检查失败时停止,并不运行后续的检查
优点:可以直截了当的看到检查是否通过
缺点:检查失败后,后续检查不会执行,无法收集那些检查结果状态
验证(vertify):将不会终止测试
缺点:你必须做更多的工作来检查测试结果:查看日志——>耗时多,所以更偏向于断言
26、page object设置模式中,是否需要在page里定位的方法中加上断言?
不需要,page页只做元素抓取和操作方法
27、page object设计模式中,如何实现页面的跳转?
初始化driver参数,Page类传driver参数
28、自动化测试用例从哪里来?
-手工用例中抽取
29、你觉得自动化测试最大的缺陷是什么?
-不稳定
-可靠性不强
-不易维护
-成本与收益
30、什么是分层测试?
1.数据层
2.接口层’
3.UI层
31、webdriver可以用来做接口测试吗?
不可以,webdriver是专门做web的UI自动化参数
32、get和post 的区别?
1、GET请求:请求的数据会附加在URL之后,以?分割URL和传输数据,多个参数用&连接。
POST请求:POST请求会把请求的数据放置在HTTP请求包的包体中。
2、传输数据的大小
使用GET请求时,传输数据会受到URL长度的限制。
对于POST,理论上是不会受限制的
3、安全性。POST的安全性比GET的高
33、is 与 == 区别:
is 用于判断 两个变量 引用对象是否为同一个 == 用于判断 引用变量的值 是否相等















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}