| (包括课程设计的目的、时间进度安排、设计报告撰写要求) 一、小组成员
| 姓名 | 班级 | 学号 | | 1111 | 19计科一班 | 19 | | 11111 | 19计科一班 | 19001 | | 1111 | 19计科一班 | 190 | | 1111 | 19计科一班 | 190 |
二、课程设计的基本目标 1. 熟练掌握人工智能所需的基本知识,包括问题设置、算法建模等。 2. 熟练掌握人工智能求解问题的整个过程。 3. 将以往所学的知识与本课程综合起来应用于实际设计中,培养在实际工作中分析问题和解决问题的能力。 三、课程设计进度安排 1.寻找有关资料 2.分配任务,编写代码 3.日常交流 4.汇合代码,书写文档 5.总结 四、设计报告撰写要求 1、格式要求:A4纸,正文中的任何部分不得写到边框以外,亦不得随意接长或截短。汉字必须使用国家公布的规范字。 2、页面设置:上2.5cm,下2.5cm,左2.5cm,右2cm;页眉1.5cm,页脚1.75cm。行距采用固定值:22磅,标准字符间距,对齐方式为两端对齐,排版合理、美观。 3、中文为小四号宋体,西文、数字等符号均采用Times New Roman字体,图表要求绘制清晰,图标题小五号字体,位于图的下面,表标题小五号字体,位于表的上面。 4、课程设计报告封面内容要求全班统一格式,3号黑体字。 摘要 随着网络技术和计算机视觉技术的发展,在日常生活中如何正确识别个人身份和保护其个人隐私已经成为当今社会亟待解决的重大问题。而传统的证件和密码等消息容易造假,使得人体生物特征以外的认证技术都不能满足人们的需求。而生物特征的唯一性、稳定性和不容易造假的特点,使其成为认证身份的首选安全方式。而人脸具有简易性、直观性、非接触性和非强制性等优点,因此本文对人脸识别技术进行了研究。 我们在分析研究国内外关于人脸识别的研究现状的基础是主要完成了如下工作内容包括:首先预处理人脸图像。对检测出来的人脸进行灰度化、中值滤波、边缘增强和归一化处理;其次提取PCA特征。在对比分析了典型人脸特征提取算法的基础上,应用基于主成分分析PCA算法,该算法能有效地减少光照变化和表情变化对系统识别的影响。最后用此方式对人脸进行特征提取,计算得出的特征向量用于下一步的网络训练,经过弹性动量的权值调整方法完成训练BP神经网络和利用该分类器对测试样本集进行人脸识别。实验结果表明该方法相对于单独使用PCA特征和BP神经网络都具有很好的人脸识别率同时在样本集很少的情况下也行达到很高的人脸识别率。 关键词:人脸识别,主要成分分析方法,BP神经网络 1.研究背景 随着网络技术和计算机视觉技术的发展,在日常生活中如何正确识别个人身份和保护其个人隐私已经成为当今社会亟待解决的重大问题。而传统的证件和密码等消息容易造假,使得人体生物特征以外的认证技术都不能满足人们的需求。而生物特征的唯一性、稳定性和不容易造假的特点,使其成为认证身份的首选安全方式。对于人体来说,生物特征包括人体指纹、人脸和虹膜等生理特征或笔迹、语音和步态等行为特征,生物特征识别技术是以基于生物技术采用信息科学技术来识别的新技术,从而对个人身份进行鉴别。在现实世界中,人们从陌生人到熟悉的朋友期间,人脸识别起到了相互认识的重要作用,但人脸识别相对于虹膜识别和指纹识别来说他的唯一性要稍逊色于她俩。但人脸识别技术具有简易性、直观性、非接触性和非强制性等优点,与其他生物特征的比较如下图1所示。 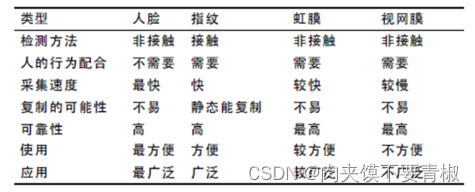
图1 因为人脸识别技术有很多优点,所以大量人力物力被投入到研究中,这也使得人脸识别在视频监控、门禁系统、机器人和网络应用等各个领域得到了广泛的应用。因此,探究人脸识别技术具有理论意义和实际意义。近年来尽管人们在人脸识别上进行了深度的学术研究,并取得了精妙且实用价值的识别算法,但是人脸识别技术仍然需要应对强大的困境。 2.研究主要内容 主要研究是基于PCA特征和改进了BP神经网络的人脸识别分类算法,在研究期间主要做了如下几点工作:首先预处理人脸图像。对检测出来的人脸进行灰度化、中值滤波、边缘增强和归一化处理;其次提取PCA特征。本文在对比分析了典型人脸特征提取算法的基础上,应用基于主成分分析PCA算法,该算法能有效地减少光照变化和表情变化对系统识别的影响。最后通过采用这种方式在人脸上进行特征提取,变化得到的特征向量作为接下来的网络训练,通过弹性动量的权值调整方法完成训练BP神经网络和利用该分类器对测试样本集进行人脸识别。 3.BP神经网络 BP(Back Propagation)神经网络最初是在1986年由D.E.Ru⁃melhart 和J.L.Mc Celland首先提出来的,是目前应用最广泛的人工神经网络。BP神经网络包括输入层、隐藏层和输出层。 4.基于BP神经网络的人脸识别算法 4.1人脸图像检测 人脸图像检测就是对输入图像中进行判断是否包含人脸,如果有,则给出人脸的位置、大小等信息,并将人脸区域从背景中分离出来。人脸图像中包含的模式特征十分丰富,如颜色特征、结构特征、直方图特征等,现行已经有很多检测的成熟算法,在此不再赘述。为简单起见,本文直接使用ORL数据库中的人脸图像。 4.2人脸图像预处理 由于原始图像在生成、传输等过程中会受到各种条件的限制和随机干扰,因此在进行人脸识别之前必须对图像进行灰度校正、噪声过滤等图像预处理。预处理的目的是消除噪声及冗余信息的干扰,降低环境因素对图像的影响,突出图像的重要信息。 4.3人脸图像特征提取 原始图像转换为灰度图像后,其所包含的数据量还是比较大的,若直接对其进行计算,则计算量会非常的大,因此需要对灰度图像进一步处理来提取其特征值。图像进行特征提取,使用提取的特征信息来进行人脸的分类,常用于表述人脸的几何特征包括:①眉毛的厚度,眉毛与眼睛之间的垂直距离;②眉毛弧度的11个描述参数;③鼻子的宽度,鼻子的垂直位置④嘴巴宽度、上下嘴唇的厚度、嘴巴的垂直距离;⑤下巴形状的描述参数⑥鼻孔位置的脸宽⑦鼻孔与眼睛中间位置的脸宽。人脸特征提取的方法归纳起来分为两大类:一种是基于知识的表征方法;另外一种是基于代数特征或统计学习的表征方法。基于知识几何特征的提取在很大程度上依赖于先验知识,具有较大的局限性和不准确性,基于统计学习的方法用统计的策略提取所有训练图像的统计特征,不需要抽取每个人脸的面部特征,会更有效,因此成为了目前主流的方法。人脸特征提取不管用哪种方法思路都是将图像划分为小的区域,由高维空间的表示变换到用低维空间来表示,通过添加处理选取低维空间中最能表现图像特征的数据来表示图像,从而达到降低特征维数的目的。 4.4实验内容描述 实验中建议采用如下最简单的三层BP神经网络,输入层为 
,有n个神经元节点,输出层具有m个神经元,网络输出为 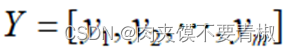
,隐含层具有k个神经元,采用BP学习算法训练神经网络。如图2所示: 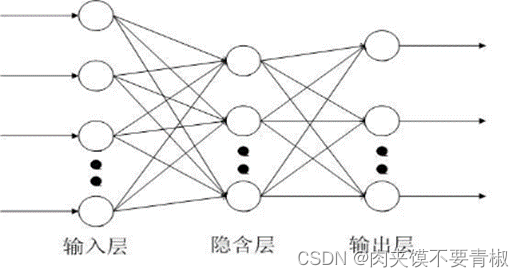
图2 BP网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对BP网络加以训练,网络就具有输入输出对之间的映射能力。BP网络执行的是有教师训练,其样本集是由形如(输入向量,期望输出向量)的向量对构成的。在开始训练前,所有的权值和阈值都应该用一些不同的小随机数进行初始化。 5.P算法主要过程 5.1向前传播阶段 ①从样本集中取一个样本(Xp,Yp),将Xp输入网络,其中Xp为输入向量,Yp为期望输出向量。 ②计算相应的实际输出Op。 在此阶段,信息从输入层经过逐级的变换,传送到输出层。这个过程也是网络在完成训练后正常运行时执行的过程。在此过程中,网络执行的是下列运算: 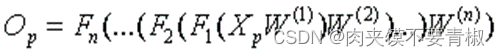
5.2向后传播阶段 ①计算实际输出Op与相应的理想输出Yp的差; ②按极小化误差的方法调整权矩阵。 这两个阶段的工作一般应受到精度要求的控制,定义 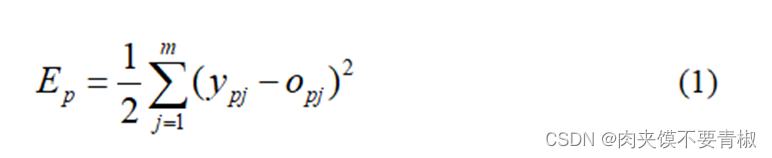
作为网络关于第p个样本的误差测度(误差函数)。而将网络关于整个样本集的误差测度定义为 
如前所述,之所以将此阶段称为向后传播阶段,是对应于输入信号的正常传播而言的,也称之为误差传播阶段。 为了更清楚地说明本文所使用的BP网络的训练过程,首先假设输入层、中间层和输出层的单元数分别是N、L和M。X=(x0,x1,…,xN-1)是加到网络的输入矢量,H=(h0,h1,…,hL-1)是中间层输出矢量,Y=(y0,y1,…,yM-1)是网络的实际输出矢量,并且用D=(d0,d1,…,dM-1)来表示训练组中各模式的目标输出矢量。输入单元i到隐单元j的权值是Vij,而隐单元j到输出单元k的权值是Wjk。另外用θk和Φj来分别表示输出单元和隐单元的阈值。 于是,中间层各单元的输出为: 
而输出层各单元的输出是: 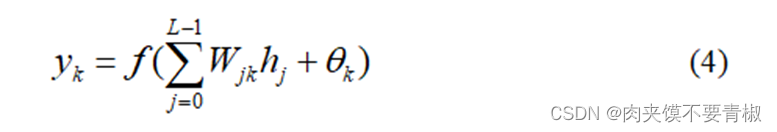
其中f(*)是激励函数,采用S型函数: 
5.3训练过程 (1) 选定训练集。由相应的训练策略选择样本图像作为训练集。 (2) 初始化各权值Vij,Wjk和阈值Φj,θk,将其设置为接近于0的随机值,并初始化精度控制参数ε和学习率α。 (3) 从训练集中取一个输入向量X加到网络,并给定它的目标输出向量D。 (4) 利用上式(3)计算出一个中间层输出H,再用上式(4)计算出网络的实际输出Y。 (5) 将输出矢量中的元素yk与目标矢量中的元素dk进行比较,计算出M个输出误差项: 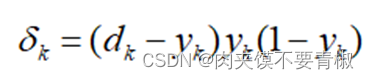
对中间层的隐单元也计算出L个误差项: 
(6) 依次计算出各权值和阈值的调整量: 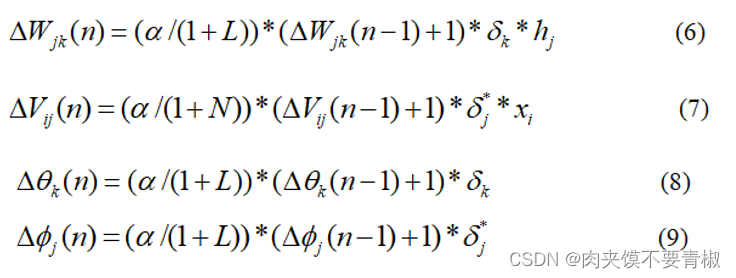
(7) 调整权值和阈值: 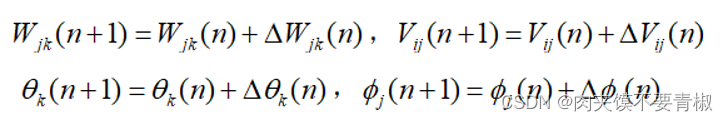
(8) 当k每经历1至M后,判断指标是否满足精度要求:E≤ε,其中E是总误差函数,且 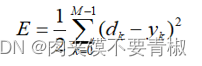
如果不满足,就返回(3),继续迭代。如果满足,就进入下一步。 (9) 训练结束,将权值和阈值保存在文件中。这时可以认为各个权值已经达到稳定,分类器形成。再一次进行训练时,直接从文件导出权值和阈值进行训练,不需要进行初始化。 6.PCA特征 主成分分析(Principal Component Analysis,PCA),PCA它是一种数据分析的方法,同时它也是一种主流的可以根据变量的协方差对要计算的数据进行降维、压缩的方法。它的精髓在于尽量用最少数量的维度,尽可能精确地描述数据[25]。PCA通过线性变换把原来的数据变换为线性无关的表示,变量间主要的特征分量能够被PCA提取以达到降维的作用。PCA处理后的目标能够使目标维数太大的问题减小并且能够使检测人脸过程中的计算量减少。而在减少维度的过程中使得一些也有用的信息减少可能会产生一些不能准确分类的问题。 假如有一个K维的特征,它的每一维特征与除他之外的特征都正交,我们可以通过变换这些维的坐标系使得这些特征在某些维上表现更明显,某些维上表现不太明显。假如有一个倾斜45度椭圆在第一现象中按照x,y坐标投影,由于它们在x,y上变化的方差相差不大导致的问题是没有办法来判断这个点具体是哪个,那么假如我们将坐标轴进行旋转,以椭圆的长轴作为x轴,此时投影在长轴的点分布比较多而在短轴上投影点分布的比较少,所以能够保留长轴属性区分椭圆上的点。以此得出我们要想将数据进行降维首先的求出这些数据的投影矩阵。而投影矩阵就通过求出样本数据的协方差,然后对这些协方差矩阵求特征向量得到的。 举一个具体的例子就是,假如有一个样本为1000维度为10训练集,构成一个1000*10 的矩阵,可以求得一个100*10 的协方差矩阵,将计算得到的协方差矩阵的特征值和特征向量计算出来。在所得结果中,任意选取其中5个特征值所对应的特征向量,构成一个10*5的特征向量矩阵。这时用样本矩阵称以特征向量矩阵就会达到一个1000*3的降维后的新矩阵。然后用给定的测试集矩阵去乘特征矩阵,用此时得到的特征进行分类任务。 以上便是 PCA降维的基本的数学原理,对于人脸识别来说,在人脸识别库中有一系列的训练样本,这些样本中的特征组成了高维度的向量,而这些高维度中的某些元素对于特征表示并没有多大的区分性那么用它来作为特征区分并不会有很好的效果,所以我们必选择那些有明显变化的元素也就是选择那些方差的比较大的维,而将那些没有明显变化的维去除,这样一来我们选择的特征都是足以表达图像特征的维,使得计算也变得相对简单。 7.算法代码实现 描述 实验中先进行权值和参数的初始化,然后大约进行100次训练,保存参数文件以供以后直接调用。训练集合为15个人的11张不同的脸部图像,根据顺序进行了编号,共165张。实验采用每个人前5张图进行训练,然后测试每个人后6张图的正确率。 过程 采用BP模型训练神经网络100次,学习率0.3,精度分别为0.1/0.01/0.001,得到如下结果: <匹配率计算公式:Matching rate = match num / 6> 
5.总结 人脸识别一直是计算机视觉领域研究的重点内容之一。本文以识别人脸为研究对象,通过对算法的一系列探究,最终实现了人脸识别的方法。下面对本文所做的工作总结如下: (1)在生物识别算法中,论述了具有代表性的人脸识别算法的研究背景和意义;人脸识别的应用和识别的内容以及国内外研究现状等。 (2)为了更好的提高人脸识别的准确率,我们首先对已检测到人脸图像进行了灰度化、中值滤波、边缘增强和归一化等预处理 (3)对预处理的人脸图像进行特征提取。在分析研究的传统的经典的人脸特征基础了使用了经典的主成分分析(PCA)方法。 (4)应用改进的BP神经网络实现了人脸识别。实验结果表明该方法对光照噪声具有很好的鲁棒性。 #include <stdio.h>
#include <stdlib.h>
#include <Windows.h>
#include <string.h>
#include <time.h>
#include <string>
#include <math.h>
#include <iostream>
#include <sstream>
using namespace std;
char bmp_path[50];
int bmp_width;
int bmp_height;
int size;
int bmp_biBitCount;
int line_byte;
BITMAPINFOHEADER head_info;
RGBQUAD bmp_color[256];
char bmp_buf[8000];
const int N=3000,L=100,M=15;
double input_vector[N];
double mid_vector[L];
double output_vector[M];
int exp_output[M];
double input_weight[N][L];
double mid_weight[L][M];
double mid_limit[L];
double output_limit[M];
double study_rate = 0.3;
double accuracy = 0.001;
double mid_error[L];
double output_error[M];
double deta_input_weight[N][L];
double deta_mid_limit[L];
double deta_mid_weight[L][M];
double deta_output_limit[M];
void init()
{
srand(time(0));
for(int i=0;i<N;i++)
{
for(int j=0;j<L;j++)
{
input_weight[i][j] = rand()*2.0/RAND_MAX - 1.0;
}
}
for(int i=0;i<L;i++)
{
mid_limit[i] = rand()*2.0/RAND_MAX - 1.0;
}
for(int i=0;i<L;i++)
{
for(int j=0;j<M;j++)
{
mid_weight[i][j] = rand()*2.0/RAND_MAX - 1.0;
}
}
for(int i=0;i<M;i++)
{
output_limit[i] = rand()*2.0/RAND_MAX - 1.0;
}
}
double sigmoid(double x)
{
return 1.0 / (1.0 + exp(-1.0*x));
}
void save_file()
{
FILE *fp =fopen("parameter.txt","w+");
if(NULL==fp)
{
printf("\n-----creating file is failed!-----\n");
}
for(int i=0;i<N;i++)
{
for(int j=0;j<L;j++)
{
fprintf(fp,"%lf ",input_weight[i][j]);
}
}
fprintf(fp,"\n");
for(int i=0;i<L;i++)
{
for(int j=0;j<M;j++)
{
fprintf(fp,"%lf ",mid_weight[i][j]);
}
}
fprintf(fp,"\n");
for(int i=0;i<L;i++)
{
fprintf(fp,"%lf ",mid_limit[i]);
}
fprintf(fp,"\n");
for(int i=0;i<M;i++)
{
fprintf(fp,"%lf ",output_limit[i]);
}
printf("\n-----Saving file is successful!-----\n");
fclose(fp);
}
void load_file()
{
FILE *fp =fopen("parameter.txt","r");
if(NULL==fp)
{
printf("\n-----creating file is failed!-----\n");
}
for(int i=0;i<N;i++)
{
for(int j=0;j<L;j++)
{
fscanf(fp,"%lf ",&input_weight[i][j]);
}
}
for(int i=0;i<L;i++)
{
for(int j=0;j<M;j++)
{
fscanf(fp,"%lf ",&mid_weight[i][j]);
}
}
for(int i=0;i<L;i++)
{
fscanf(fp,"%lf ",&mid_limit[i]);
}
for(int i=0;i<M;i++)
{
fscanf(fp,"%lf ",&output_limit[i]);
}
printf("\n-----Loading file is successful!-----\n");
fclose(fp);
}
int read_bmp(char *bmp_path)
{
FILE *fpbmp = fopen(bmp_path,"rb");
if(NULL==fpbmp)
{
perror("ERROR");
printf("\n-----Fetching image is failed!-----\n");
return 0;
}
fseek(fpbmp,sizeof(BITMAPFILEHEADER),0);
fread(&head_info,sizeof(BITMAPINFOHEADER),1,fpbmp);
bmp_width = head_info.biWidth;
bmp_height = head_info.biHeight;
bmp_biBitCount = head_info.biBitCount;
line_byte = (bmp_width*bmp_biBitCount/8 + 3) / 4 * 4;
size = bmp_height * line_byte;
fread(bmp_color,sizeof(RGBQUAD),256,fpbmp);
fread(bmp_buf,1,size,fpbmp);
int k=0;
for(int i=20;i<80;i++)
{
for(int j=15;j<65;j++)
{
input_vector[k++] = (bmp_buf[i*80+j]+128)*1.0/255;
}
}
fclose(fpbmp);
return 1;
}
void forward()
{
double sum=0;
for(int i=0;i<L;i++)
{
sum=0;
for(int j=0;j<N;j++)
{
sum += input_vector[j]*input_weight[j][i];
}
mid_vector[i] = sigmoid(sum+mid_limit[i]);
}
for(int i=0;i<M;i++)
{
sum=0;
for(int j=0;j<L;j++)
{
sum += mid_vector[j]*mid_weight[j][i];
}
output_vector[i] = sigmoid(sum+output_limit[i]);
}
}
double cal_error()
{
double e=0;
for(int i=0;i<M;i++)
{
e += (exp_output[i]-output_vector[i])*(exp_output[i]-output_vector[i]);
}
return e<=2.0 ? e*0.5:1.0;
}
void back()
{
for(int i=0;i<M;i++)
{
output_error[i] = (exp_output[i]-output_vector[i])*output_vector[i]*(1-output_vector[i]);
}
for(int i=0;i<L;i++)
{
double sum=0;
for(int k=0;k<M;k++)
{
sum += output_error[k]*mid_weight[i][k];
}
mid_error[i] = mid_vector[i]*(1-mid_vector[i])*sum;
}
for(int i=0;i<L;i++)
{
for(int j=0;j<M;j++)
{
deta_mid_weight[i][j] = study_rate * output_error[j]*mid_vector[i];
mid_weight[i][j] += deta_mid_weight[i][j];
}
}
for(int i=0;i<M;i++)
{
deta_output_limit[i] =study_rate * output_error[i];
output_limit[i] += deta_output_limit[i];
}
for(int i=0;i<N;i++)
{
for(int j=0;j<L;j++)
{
deta_input_weight[i][j] = study_rate * mid_error[j]*input_vector[i];
input_weight[i][j] += deta_input_weight[i][j];
}
}
for(int i=0;i<L;i++)
{
deta_mid_limit[i] =study_rate * mid_error[i];
mid_limit[i] += deta_mid_limit[i];
}
}
void train(int m)
{
printf("-----Training %d!-----\n",m);
while(m--)
{
printf(".");
for(int n=1;n<=5;n++)
{
for(int i=n;i<=165;i=i+11)
{
stringstream s;
s<<i;
string str = s.str();
string bmp_name ="YALE\\"+str+".bmp";
for(int j=0;j<50;j++)
{
if(j<bmp_name.length())
{
bmp_path[j]=bmp_name[j];
}
else
{
bmp_path[j] = '\0';
break;
}
}
if(0==read_bmp(bmp_path)) break;
for(int j=0;j<M;j++)
{
if(j == (i-1)/11) exp_output[j]=1;
else exp_output[j]=0;
}
forward();
double e_sum=cal_error();
if(e_sum<accuracy)
{
continue;
}
back();
}
}
}
save_file();
printf("\n-----The train is finished!-----\n");
}
int test_bmp()
{
printf("\n-----Testing Network!-----\n");
for(int n=1;n<=15;n++)
{
int sum=0;
for(int i=(n-1)*11+6;i<=n*11;i++)
{
stringstream s;
s<<i;
string str = s.str();
string bmp_name ="YALE\\"+str+".bmp";
for(int j=0;j<50;j++)
{
if(j<bmp_name.length())
{
bmp_path[j]=bmp_name[j];
}
else
{
bmp_path[j] = '\0';
break;
}
}
if(0==read_bmp(bmp_path)) return -1;
forward();
double min_error = 999;
int ans=0;
for(int k=1;k<=M;k++)
{
for(int l=0;l<M;l++)
{
if(l == (k-1)) exp_output[l]=1;
else exp_output[l]=0;
}
double error = cal_error();
if(error<min_error)
{
min_error=error;
ans=k;
}
}
if(ans == n) sum++;
}
printf("\nNo.%d match num:%d matching rate:%.2lf%%\n",n,sum,sum*100.0/6);
sum=0;
}
return 0;
}
int main(int argc, char const *argv[])
{
printf("The study_rate:%.1lf accuracy:%.3lf\n",study_rate,accuracy);
load_file();
test_bmp();
system("pause");
return 0;
}
好吧代码有点乱我是从课程报告直接复制的 | 






















 4057
4057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









