







 博客围绕埋点数据采集展开,介绍了App、PC web、微信小程序端3类埋点日志,需用flume采集到HDFS。提出采集后存储路径、数据脱敏、日期文件夹分配及中转传输等需求,阐述了数据结构,给出采集设计方案、具体实现步骤,还涉及模型创建和脚本导数据。
博客围绕埋点数据采集展开,介绍了App、PC web、微信小程序端3类埋点日志,需用flume采集到HDFS。提出采集后存储路径、数据脱敏、日期文件夹分配及中转传输等需求,阐述了数据结构,给出采集设计方案、具体实现步骤,还涉及模型创建和脚本导数据。
一:埋点数据的采集
1.1埋点日志在本项目中,有3大类:
①App端行为日志
②PC web端行为日志
③微信小程序端行为日志
日志生成在了公司的N台(5台)日志服务器中,现在需要使用flume采集到HDFS
1.2需求
3类日志采集后要分别存储到不同的hdfs路径
①日志中的手机号、账号需要脱敏处理(加密)
②不同日期的数据,要写入不同的文件夹,且分配应以事件时间为依据
③因为日志服务器所在子网跟HDFS集群不在同一个网段,需要中转传输
1.3埋点数据中的结构和说明
埋点生成的日志数据,统一设计为JSON格式;
各个终端渠道的埋点日志,都由公共属性字段,和事件属性字段组成;
①不同终端渠道,公共属性字段略有不同;
②事件属性则根据事件类型,灵活多样;
1.4flume采集数据设计方案
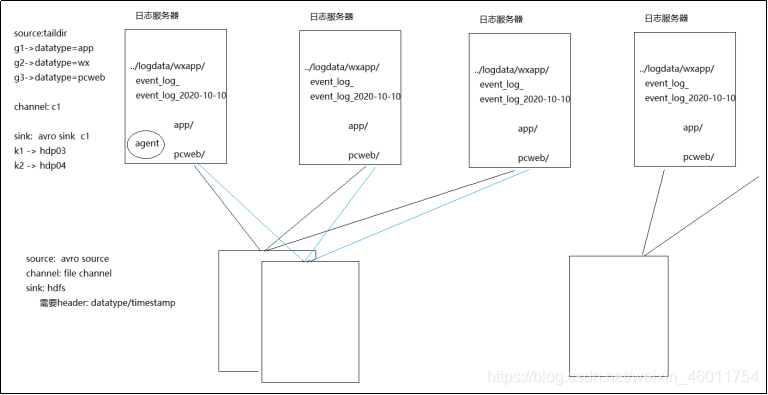
1.5具体实现
1.5.1上游文件配置
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sources.r1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = g1 g2
a1.sources.r1.filegroups.g1 = /opt/data/logdata/app/event.*
a1.sources.r1.filegroups.g2 = /opt/data/logdata/wx/event.*
a1.sources.r1.headers.g1.datatype = app
a1.sources.r1.headers.g2.datatype = wx
a1.sources.r1.batchSize = 100
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.doitedu.flume.interceptor.EventTimeStampInterceptor$EventTimeStampInterceptorBuilder
a1.sources.r1.interceptors.i1.headerName = timestamp
a1.sources.r1.interceptors.i1.timestamp_field = timeStamp
a1.sources.r1.interceptors.i1.to_encrypt_field = account
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/data/flumedata/file-channel/checkpoint
a1.channels.c1.dataDirs = /opt/data/flumedata/file-channel/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hdp02.doitedu.cn
a1.sinks.k1.port = 41414
a1.sinks.k1.batch-size = 100
a1.sinks.k2.channel = c1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hdp03.doitedu.cn
a1.sinks.k2.port = 41414
a1.sinks.k2.batch-size = 100
# 定义sink组及其配套的sink处理器
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 1
a1.sinkgroups.g1.processor.maxpenalty = 10000
1.5.2下游文件配置
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.sources.r1.batchSize = 100
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/data/flumedata/file-channel/checkpoint
a1.channels.c1.dataDirs = /opt/data/flumedata/file-channel/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hdp01.doitedu.cn:8020/logdata/%{datatype}/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = DoitEduData
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.rollSize = 268435456
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.useLocalTimeStamp = false
1.5.3自定义拦截器代码实现
package cn._51doit;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
/**
* @date 2021-01-11
* @desc 项目字段加密及时间戳提取拦截器
*/
public class FieldEncryptInterceptor implements Interceptor {
String timestamp_field;
String to_encrypt_field;
String headerName;
public FieldEncryptInterceptor(String timestamp_field, String to_encrypt_field, String headerName) {
this.timestamp_field = timestamp_field;
this.to_encrypt_field = to_encrypt_field;
this.headerName = headerName;
}
public void initialize() {
}
public Event intercept(Event event) {
// 根据要加密的字段,从event中提取原值(用json解析)
try {
String line = new String(event.getBody());
JSONObject jsonObject = JSON.parseObject(line);
String toEncryptField = jsonObject.getString(to_encrypt_field);
String timeStampField = jsonObject.getString(timestamp_field);
// 加密
if (StringUtils.isNotBlank(toEncryptField)) {
String encrypted = DigestUtils.md5Hex(toEncryptField);
// 将加密后的值替换掉原值
jsonObject.put(to_encrypt_field, encrypted);
// 转回json,并放回event
String res = jsonObject.toJSONString();
event.setBody(res.getBytes("UTF-8"));
}
// 放入时间戳到header中
event.getHeaders().put(headerName, timeStampField);
} catch (Exception e) {
event.getHeaders().put("datatype", "malformed");
e.printStackTrace();
}
return event;
}
public List<Event> intercept(List<Event> list) {
for (Event event : list) {
intercept(event);
}
return list;
}
public void close() {
}
public static class FieldEncryptInterceptorBuilder implements Builder {
String timestamp_field;
String to_encrypt_field;
String headerName;
public Interceptor build() {
return new FieldEncryptInterceptor(timestamp_field, to_encrypt_field, headerName);
}
public void configure(Context context) {
timestamp_field = context.getString("timestamp_field");
headerName = context.getString("headerName");
to_encrypt_field = context.getString("to_encrypt_field");
}
}
}
1.6ods层app及wx埋点日志对应模型创建
1.6.1app端
-- ODS层,app埋点日志对应表模型创建
DROP TABLE IF EXISTS `ods.event_app_log`;
CREATE EXTERNAL TABLE `ods.event_app_log`(
`account` string ,
`appid` string ,
`appversion` string ,
`carrier` string ,
`deviceid` string ,
`devicetype` string ,
`eventid` string ,
`ip` string ,
`latitude` double ,
`longitude` double ,
`nettype` string ,
`osname` string ,
`osversion` string ,
`properties` map<string,string> ,
`releasechannel` string ,
`resolution` string ,
`sessionid` string ,
`timestamp` bigint
)
PARTITIONED BY (`dt` string)
ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hdp01.doitedu.cn:8020/user/hive/warehouse/ods.db/event_app_log'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1610337798'
);
-- 数据入库
load data inpath '/logdata/app/2021-01-10' into table ods.event_app_log partition(dt='2021-01-10');
-- 如何删除一个表中已存在分区
alter table ods.event_app_log drop partition(dt='2020-01-10');
-- 不适用load,如何添加一个分区到已存在的表中
alter table ods.event_app_log add partition(dt='2020-01-11') location '/abc/ddd/'
1.6.2微信端
DROP TABLE IF EXISTS `ods.event_wx_log`;
CREATE EXTERNAL TABLE `ods.event_wx_log`(
`account` string ,
`openid` string,
`carrier` string ,
`deviceid` string ,
`devicetype` string ,
`eventid` string ,
`ip` string ,
`latitude` double ,
`longitude` double ,
`nettype` string ,
`osname` string ,
`osversion` string ,
`properties` map<string,string> ,
`resolution` string ,
`sessionid` string ,
`timestamp` bigint
)
PARTITIONED BY (`dt` string)
ROW FORMAT SERDE
'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://linux01:8020/user/hive/warehouse/ods.db/event_wx_log'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1610337798'
);
1.7自定义开发shell脚本自动导数据进ods库
1.7.1app端
#!/bin/bash
######################################
#
# @author : 杰
# @date : 2021-01-11
# @desc : app端埋点日志入库
# @other
######################################
export JAVA_HOME=/opt/apps/jdk1.8.0_191/
export HIVE_HOME=/opt/apps/hive-3.1.2/
DT=$(date -d'-1 day' +%Y-%m-%d)
if [ $1 ]
then
DT=$1
fi
${HIVE_HOME}/bin/hive -e "
load data inpath '/logdata/app/${DT}' into table ods.event_app_log partition(dt='${DT}')
"
if [ $? -eq 0 ]
then
echo "${DT}app埋点日志,入库成功"
else
echo "入库失败"
fi
1.7.2wx端
#!/bin/bash
######################################
#
# @author : 杰
# @date : 2021-01-11
# @desc : wx端埋点日志入库
# @other
######################################
export JAVA_HOME=/opt/apps/jdk1.8.0_191/
export HIVE_HOME=/opt/apps/hive-3.1.2/
DT=$(date -d'-1 day' +%Y-%m-%d)
if [ $1 ]
then
DT=$1
fi
${HIVE_HOME}/bin/hive -e "
load data inpath '/logdata/wx/${DT}' into table ods.event_wx_log partition(dt='${DT}')
"
if [ $? -eq 0 ]
then
echo "${DT}wx埋点日志,入库成功"
else
echo "入库失败"
fi



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









