







从“小胡子”到 vue 插值语法
什么是模板引擎
模板引擎是将数据要变为视图最优雅的解决方案,简单来说就是将模板文件和数据通过模板引擎生成一个HTML代码。还不懂?没关系,打个比方;一场考试,试卷就是模板,每个人写的答案就是数据,最后老师(模板引擎)批改(处理)得到成绩。模板的最大好处就是复用,改变数据就可以得到不同的结果。
在模板引擎中发展过程中经历了如下四个阶段:
• 纯DOM法: 非常笨拙,没有实战价值
• 数组join法: 曾几何时非常流行,是曾经的前端必会知识
• ES6的反引号法: ES6中新增的${a}语法糖,很好用
• 模板引擎:解决数据变为视图的最优雅的方法
纯DOM法
使用原生 JavaScript 动态创建 DOM,可以看出这样创建的 DOM 结构过程十分复杂且笨重。并且丢失 html 代码结构。
<body>
<ul id="list">
</ul>
<script>
// 数据
var arr = [
{ "name": "小明" },
{ "name": "小红" },
{ "name": "小强" }
];
var list = document.getElementById('list');
for (var i = 0; i < arr.length; i++) {
// 每遍历一项,都要用DOM方法去创建li标签
let oLi = document.createElement('li');
// 创建hd这个div
let hdDiv = document.createElement('div');
hdDiv.className = 'hd';
hdDiv.innerText = arr[i].name + '的基本信息';
// 创建bd这个div
let bdDiv = document.createElement('div');
bdDiv.className = 'bd';
// 创建三个p
let p1 = document.createElement('p');
p1.innerText = '姓名:' + arr[i].name;
bdDiv.appendChild(p1);
// 创建的节点是孤儿节点,所以必须要上树才能被用户看见
oLi.appendChild(hdDiv);
oLi.appendChild(bdDiv);
list.appendChild(oLi);
}
</script>
</body>
数组join法
因为使用原生JavaScript创建DOM很不方便,所以有人想出了利用字符串join把多个字符串连接起来,这样即可以让字符串有了DOM的结构特征,又让创建DOM节点没有那么笨重 。不得不说想出这个办法的前辈真是厉害。
<body>
<ul id="list"></ul>
<script>
var arr = [
{ "name": "小明", "sex": "男" },
{ "name": "小红", "sex": "女" },
{ "name": "小强", "sex": "男" }
];
var list = document.getElementById('list');
// 遍历arr数组,每遍历一项,就以字符串的视角将HTML字符串添加到list中
for (let i = 0; i < arr.length; i++) {
list.innerHTML += [
'<li>',
' <div class="hd">' + arr[i].name + '的信息</div>',
' <div class="bd">',
' <p>姓名:' + arr[i].name + '</p>',
' <p>性别:' + arr[i].sex + '</p>',
' </div>',
'</li>'
].join('')
}
</script>
</body>
ES6的反引号法
利用ES6反引号和语法糖可以更加优雅的创建DOM节点。
<body>
<ul id="list"></ul>
<script>
var arr = [
{ "name": "小明", "sex": "男" },
{ "name": "小红", "sex": "女" },
{ "name": "小强", "sex": "男" }
];
var list = document.getElementById('list');
// 遍历arr数组,每遍历一项,就以字符串的视角将HTML字符串添加到list中
for (let i = 0; i < arr.length; i++) {
list.innerHTML += `
<li>
<div class="hd">${arr[i].name}的基本信息</div>
<div class="bd">
<p>姓名:${arr[i].name}</p>
<p>性别:${arr[i].sex}</p>
</div>
</li>
`;
}
</script>
</body>
模板引擎
mustache
mustache是“胡子”的意思,因为它的嵌入标记{{ }}非常像胡子,{{ }}的语法也被 Vue 沿用,这就是我们学习 mustache 的原因 mustache 是最早的模板引擎库,比 Vue 诞生的早多了,它的底层实现机理在当时是非常有创造性的、轰动性的,为后续模板引擎的发展提供了崭新的思路.
mustache库基本使用(了解即可,方便后续原理的理解)
循环对象数组
<body>
<div id="container"></div>
<!-- 模板 -->
<script type="text/template" id="mytemplate">
<ul>
<!-- 这里会根据arr的长度循环,每次循环都创建包裹的DOM节点的数据 -->
{{#arr}}
<li>
<div class="hd">{{name}}的基本信息</div>
<div class="bd">
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
</div>
</li>
{{/arr}}
</ul>
</script>
<!--引入库需要自己下载-->
<script src="jslib/mustache.js"></script>
<script>
var templateStr = document.getElementById('mytemplate').innerHTML;
var data = {
arr: [
{ "name": "小明", "sex": "男" },
{ "name": "小红", "sex": "女" },
{ "name": "小强", "sex": "男" }
]
};
// 解析模板和数据生成dom字符串
var domStr = Mustache.render(templateStr, data);
// 将dom字符串上树显示
var container = document.getElementById('container');
container.innerHTML = domStr;
</script>
没有循环的情况
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script>
var templateStr = `
<h1>我中了{{thing}},好{{mood}}</h1>
`;
var data = {
thing: '二十万',
mood: '开心'
};
// 解析模板和数据生成dom字符串
var domStr = Mustache.render(templateStr, data);
// 将dom字符串上树显示
var container = document.getElementById('container');
container.innerHTML = domStr;
</script>
</body>
循环简单数组
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script>
var templateStr = `
<ul>
{{#arr}}
<li>{{.}}</li>
{{/arr}}
</ul>
`;
var data = {
arr: ['A', 'B', 'C']
};
// 解析模板和数据生成dom字符串
var domStr = Mustache.render(templateStr, data);
// 将dom字符串上树显示
var container = document.getElementById('container');
container.innerHTML = domStr;
</script>
</body>
循环嵌套数组
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script>
var templateStr = `
<ul>
{{#arr}}
<li>
{{name}}的爱好是:
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/arr}}
</ul>
`;
var data = {
arr: [
{'name': '小明', 'hobbies': ['羽毛球']},
{'name': '小红', 'hobbies': ['编程', '看书']},
]
};
// 解析模板和数据生成dom字符串
var domStr = Mustache.render(templateStr, data);
// 将dom字符串上树显示
var container = document.getElementById('container');
container.innerHTML = domStr;
</script>
</body>
bool值
<body>
<div id="container"></div>
<script src="jslib/mustache.js"></script>
<script>
var templateStr = `
<div>hello</div>
{{#m}}
<h1>你好</h1>
{{/m}}
<div>world</div>
`;
// 若m=false,则模板中被包裹{{#m}}{{/m}}的内容就不会显示,m=true才会显示
var data = {
m: false
};
// 解析模板和数据生成dom字符串
var domStr = Mustache.render(templateStr, data);
// 将dom字符串上树显示
var container = document.getElementById('container');
container.innerHTML = domStr;
</script>
</body>
正则表达式实现最简单的模板引擎
最简单的模板引擎的实现机理,利用的是正则表达式中的 replace() 方法。replace() 的第二个参数可以是一个函数,这个函数提供捕获的目标$1作为参数,再将 $1 结合 data 对象,即可进行智能的替换。但是这样做还是不够灵活,并且随着代码的增加对正则表达式要求也越来越高,并不利于开发。
<body>
<script>
var templateStr = '<h1>我中了{{thing}},花了{{money}}元,真{{mood}}</h1>';
var data = {
thing: '二十万',
money: 5,
mood: '爽'
};
// 这个函数使用正则全局匹配{{}},并用数据对象中key值对应的value替换字符串中的key值
function render(templateStr, data) {
return templateStr.replace(/\{\{(\w+)\}\}/g, function (findStr, $1) {
return data[$1];
});
}
var result = render(templateStr, data);
console.log(result);
</script>
</body>
mustache 的底层核心机理
mustache库的机理
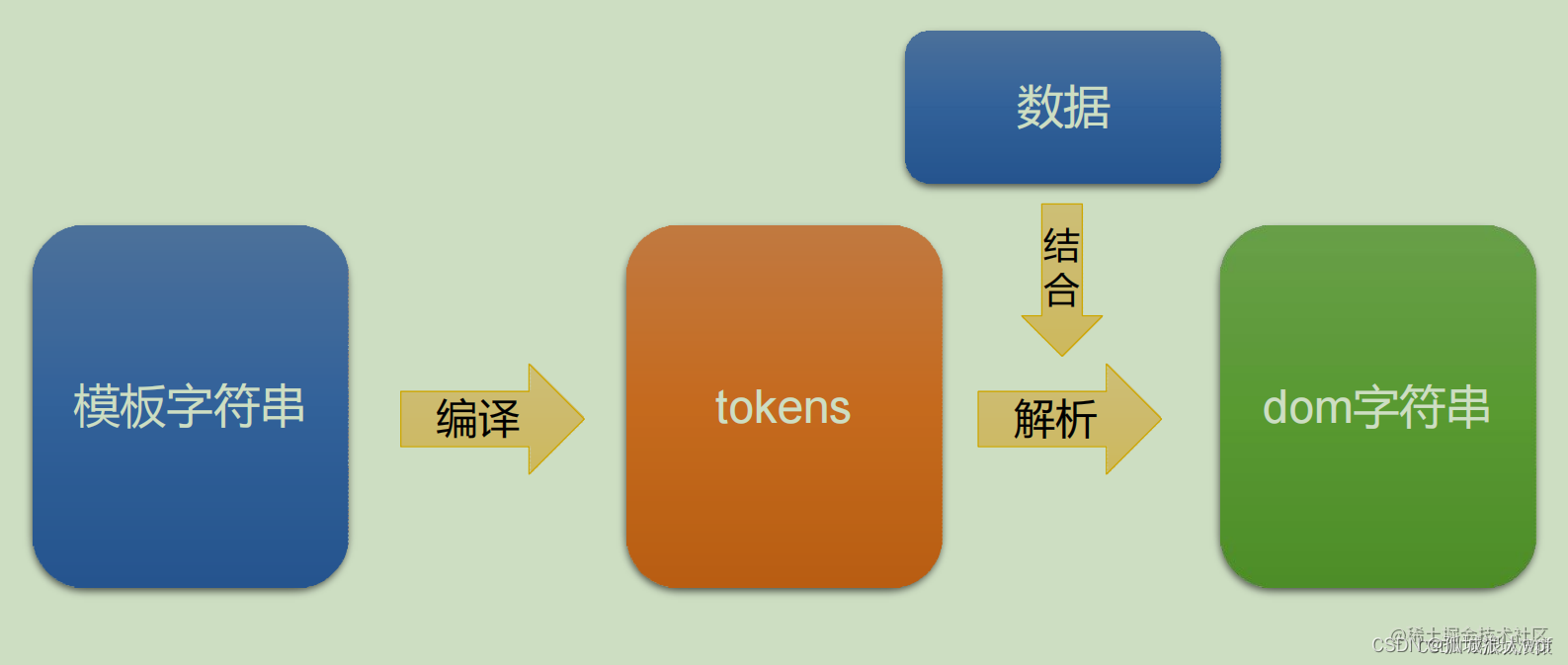
例:

mustache 库底层重点要做两个事情:
-
将模板字符串编译为tokens形式
-
将tokens结合数据,解析为dom字符串
什么是tokens?
tokens 是一个 JS 的嵌套数组,就是用一个 JS 对象来描述模板字符串,它是“抽象语法树”、“虚拟DOM”等等的开山鼻祖。
简单模板字符串
<h1>我中了{{thing}},真{{mood}}啊</h1>
对应的tokens
[
["text", "<h1>我中了"],
["name", "thing"],
["text", ",真"],
["name", "mood"],
["text", "啊</h1>"],
]
双重循环模板字符串
<div>
<ol>
{{#students}}
<li>
学生
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/students}}
</ol>
</div>
对应的tokens
如果有循环,那么 tokens 会层层嵌套。
[
["text", "<div><ol>"],
["#", "students", [
["text", "<li>学生"],
["name", "name"],
["text", "的爱好是<ol>"],
["#", "hobbies", [
["text", "<li>"],
["name", "."],
["text", "</li>"],
]],
["text", "</ol></li>"],
]],
["text", "</ol></div>"]
]
由以上对应关系可以得出当匹配到{{时,他前面到上一个}}或开头之间的内容会被保存为["text", "XXX"],而一对{{}}之间的内容被保存为["name", "XXX"],循环开始({{#students}})会被保存为["#", "XXX"],循环结束会直接忽略。
重点:
- 不同的键标记不同的内容,text 对应的值不需要特殊处理,name 对应的值时需要替换的···
- 如果有循环存在,那么 tokens 就会有嵌套。从这里可以看出我们将一个DOM树变成了一个 js 树状结构。
实现简单的小胡子(mustache)
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="container"></div>
<script src="/xuni/bundle.js"></script>
<script>
// 模板字符串
let templateStr = `<div>
<ul>
{{#students}}
<li class="myli">
学生{{name}}的爱好是
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/students}}
</ul>
</div>`
// 数据
var data = {
students: [
{ 'name': '小明', 'hobbies': ['编程', '游泳'] },
{ 'name': '小红', 'hobbies': ['看书', '弹琴', '画画'] },
{ 'name': '小强', 'hobbies': ['锻炼'] }
]
};
// 解析
const domStr = myTemplate.render(templateStr, data);
document.getElementById('container').innerHTML = domStr;
console.log(domStr);
</script>
</body>
</html>
第一步首先是把模板字符串变为tokens
Scanner扫描类
我们要想将模板字符串变为 tokens 需要怎么做?首先肯定是要有一个工具把{{}}内和外的字符串分割出来并做对应的标记区别,mustache 的方法是声明一个扫描类 Scanner。
两个方法scan和scanutil
- scanutil的作用是一个一个字符遍历寻找指定标记,并把扫描过的字符作为字符串返回,
- scan的作用是使指针跳过指定标记。
三个属性
this.templateStr即将扫描的字符串。this.pos遍历字符串当前指针位置。this.tail遍历过程中还未遍历到的字符串(尾巴)。
例:this.templateStr = “abc”,this.pos = 1时,this.tail=“bc”;
下面给出代码,有详细注释,这里的逻辑很简单。
// 扫描器类
export default class Scanner {
constructor(templateStr) {
// 将模板字符串写到实例身上
this.templateStr = templateStr;
// 指针指向尾巴开头的下标
this.pos = 0;
// 尾巴,一开始就是模板字符串原文
this.tail = templateStr;
}
// 使指针跳过指定标记
scan(tag) {
if (this.tail.indexOf(tag) === 0) {
// tag有多长,比如{{长度是2,就让指针后移多少位
this.pos += tag.length;
// 改变尾巴为从当前指针这个字符开始,到最后的全部字符
this.tail = this.templateStr.substring(this.pos);
}
}
// 一个一个遍历寻找指定标记,并把扫描的字符作为字符串返回
scanUtil(stopTag) {
// 记录一下执行本方法的时候pos的值,方便后期截取字符串
const post_back = this.pos;
// 扫描寻找stoptag,当尾巴的开头不是stopTag的时候,就说明还没有扫描到stopTag
// 写&&很有必要,因为防止找不到,那么寻找到最后也要停止下来
while (this.tail.indexOf(stopTag) !== 0 && this.pos < this.templateStr.length) {
this.pos++;
// 改变尾巴为从当前指针这个字符开始,到最后的全部字符
this.tail = this.templateStr.substring(this.pos);
}
//返回截取的目标字符串
return this.templateStr.substring(post_back, this.pos);
}
}
模板字符串转为tokens数组
首先需要实例化一个扫描器用来扫描字符串并返回目标字符串。在扫描器工作过程中每一次循环都要使scanUtil('{{'),scan('{{'),scanUtil('}}'),scan('}}')则四个函数按顺序执行,才能完成一次区分{{}}内外字符串的任务。
原因:以"我中了{{thing}}"为例
scanUtil('{{')的返回值是{{到上一个}}或开头之间的字符串,返回"我中了",以text标记,this.pos=3scan('{{')让指针跳过{{,this.pos=5scanUtil('}}')的返回值是}}到上一个{{或开头之间的需要用数据替换的字符串,返回"thing",以(name||#||/)标记this.pos=10scan('}}')让指针跳过}},this.pos=12,遍历结束
一点点细节
处理 text 的多余空格
因为模板字符串是有一定的 DOM 结构的(方便开发人员阅读),所以在字符串中一定会有多余空格,我们需要舍弃它才能在最后渲染出正确的 DOM。
if (word !== '') {
// 标志空格是否在标签内
let isInHtml = false;
// 保存去掉空格的字符串
let words = '';
// 循环扫描字符串并做判断
for (const element of word) {
// 判断是否在标签里
if (element === '<') {
isInHtml = true;
} else if (element === '>') {
isInHtml = false;
}
// 如果是空格
if (/\s/.test(element)) {
// 只有在标签内才拼接到结果字符串中
if (isInHtml) {
words += " ";
}
} else {
// 不是空格直接拼接
words += element;
}
};
完整代码
import Scanner from './Scanner'
import NestTokens from './nestTokens'
// 模板字符串转为tokens数组
export default function TemplateToTokens(templateStr) {
// 创建扫描器
let scanner = new Scanner(templateStr);
let tokens = [];
let word;
// 让扫描器工作
while (scanner.pos < templateStr.length) {
// 收集开始标记出现之前的文字
word = scanner.scanUtil('{{');
//智能判断是普通文字的空格,还是标签中的空格,标签中的空格不能去掉,
//比如 < div class="box" > 不能去掉class前面的空格
if (word !== '') {
// 标志空格是否在标签内
let isInHtml = false;
// 保存去掉空格的字符串
let words = '';
// 循环扫描字符串并做判断
for (const element of word) {
// 判断是否在标签里
if (element === '<') {
isInHtml = true;
} else if (element === '>') {
isInHtml = false;
}
// 如果是空格
if (/\s/.test(element)) {
// 只有在标签内才拼接到结果字符串中
if (isInHtml) {
words += " ";
}
} else {
// 不是空格直接拼接
words += element;
}
};
// 将去空格后的字符串保存到tokens中
tokens.push(['text', words]);
}
// 过双大括号
scanner.scan('{{');
// 收集大括号内的内容
word = scanner.scanUtil('}}');
if (word !== '') {
// 判断一下首字符
if (word[0] === '#')
// 从下标为1的项开始存,因为下标为0的项是#
tokens.push(['#', word.substring(1)]);
else if (word[0] === '/')
// 从下标为1的项开始存,因为下标为0的项是/
tokens.push(['/', word.substring(1)]);
else
// 存起来
tokens.push(['name', word]);
}
// 过双大括号
scanner.scan('}}');
}
// 返回折叠收集的tokens
return NestTokens(tokens);
}
嵌套tokens处理
当模板字符串中出现了{{#XXX}}···{{/XXX}}包裹的内容时,说明数据中有嵌套的内容,此时tokens应当进行嵌套处理。
我们首先要解决的是怎么判断嵌套的开始和结束,你可能会想当遇到标志为#就为开始,标志是/就是结束,那么我只能告诉你这样想只对了一半,当有多级嵌套时这样的判定方法就无法保证嵌套的开始和结束的正确对应关系,说到这里如果熟悉数据结构的朋友可能就想到了,利用栈存储结构就可保证开始和结束的正确对应。每次遇到开始就入栈,因为是多级嵌套关系且栈是先进后出的特性,所以遇到的结束一定栈顶开始对应的结束。
注意!注意!注意!:下面才是我认为 mustache 中此部分算法中最精妙的部分。
嵌套开始和结束的问题解决了,那么如何使tokens字符串就有真正的嵌套结构呢?我们可以利用引用的特性,定义一个搜集器temp,最初为tokens,它负责搜集每一集嵌套的内容。
模拟过程
处理的嵌套模板字符串
let templateStr = `<div>
<ul>
{{#students}}
<li class="myli">
{{name}}
</li>
{{/students}}
</ul>
</div>`
起初 temp 为 tokens,且将 tokens 压栈,搜集器即为栈顶元素,所以当在遇到{{#students}}前 tokens 数组为
[
["text", "<div><ul>"]
]
遇到{{#students}}后,先将其放入 tokens 中,同时将其压栈,搜集器就为一个空数组且将其作为当前元素的第三个元素,即 tokens 数组变为
[
["text", "<div><ul>"],
["#", "students", []]
]
然后开始搜集嵌套中的内容,当遇到结束标志后说明当前嵌套搜集完成,此时将栈顶元素弹出,将搜集器变为更新后的栈顶元素,在本例中就是 tokens。
[
["text", "<div><ul>"],
["#", "students", [
["text", "<li class="myli">"],
["name", "name"],
["text", "</li>"],
]],
]
然后继续搜集剩下元素,最终的到完整 tokens
[
["text", "<div><ul>"],
["#", "students", [
["text", "<li class="myli">"],
["name", "name"],
["text", "</li>"],
]],
["text", "</ul></div>"]
]
这里搜集器数组真的是非常巧妙,如果不懂一定要多看几遍,学会了以后遇到类似的问题就会解了,这不就是我们学习源码的意义所在吗?
处理多级嵌套的函数
// 处理多级嵌套tokens,将#和/之间的tokens能够整合起来,作为它的下标为3的项
export default function nestTokens(tokens) {
// 结果数组
let nestTokens = [];
// 栈结构,存放小tokens,栈顶(靠近端口的,最新进入的)的tokens数组中当前操作的这个tokens小数组
let stack = [];
// 收集器,天生指向nestedTokens结果数组,引用类型值,所以指向的是同一个数组
// 收集器的指向会变化,当遇见#的时候,收集器会指向这个token的下标为2的新数组
let temp = nestTokens;
tokens.forEach(element => {
// 收集器中放入这个token
if (element[0] === '#') {
temp.push(element)
// 入栈
stack.push(element);
// 收集器要换人。给token添加下标为2的项,并且让收集器指向它
temp = element[2] = [];
} else if (element[0] === '/') {
// 出栈。pop()会返回刚刚弹出的项
stack.pop();
// 改变收集器为栈结构队尾(队尾是栈顶)那项的下标为2的数组
temp = stack.length > 0 ? stack[stack.length - 1][2] : nestTokens
} else {
// 甭管当前的collector是谁,可能是结果nestedTokens,也可能是某个token的下标为2的数组,甭管是谁,推入collctor即可。
temp.push(element);
}
});
return nestTokens;
}
第二步将tokens结合数据变为DOM字符串
主要思路是根据 tokens 数组,标记为 name 的元素是要用元素替换的,而标记为 text 的则直接拼接到结果字符串上,标记为 # 的需要我们进一步递归处理。
import lookUp from "./Lookup";
import parseArray from "./parsweArray";
// 函数的功能是让tokens数组变为dom字符串
export default function renderTemplate(tokens, data) {
// 结果字符串
let resultStr = '';
// 遍历tokens
tokens.forEach(element => {
// 看类型
if (element[0] === 'text') {
// 拼起来
resultStr += element[1];
} else if (element[0] === 'name') {
// 如果是name类型,那么就直接使用它的值,当然要用lookup因为防止这里是“a.b.c”有逗号的形式
resultStr += lookUp(data, element[1]);
} else if (element[0] === '#') {
// 递归处理嵌套
resultStr += parseArray(element, data);
}
});
return resultStr;
}
一点点细节
那么在处理过程中我们会遇到这样一种情况需要被数据替换的字符串类似a.b.c,那么常规方法并不能取到对应数据,所以我们在用数据替换字符串时应该做一个基本的判断,并做出相应的处理,如下代码所示。
/*
功能是可以在dataObj对象中,寻找用连续点符号的keyName属性
比如,dataObj是
{
a: {
b: {
c: 100
}
}
}
那么lookup(dataObj, 'a.b.c')结果就是100
*/
export default function lookUp(dataObj, keyName) {
// 看看keyName中有没有点符号,但是不能是.本身
if (keyName.indexOf('.') !== -1 && keyName !== '.') {
// 以点为分割符将字符串拆开
let keys = keyName.split('.');
// 设置一个临时变量,这个临时变量用于周转,一层一层找下去。
let temp = dataObj;
// 每找一层,就把它设置为新的临时变量
for (let i = 0; i < keys.length; i++) {
temp = temp[keys[i]]
}
return temp;
}
// 如果这里面没有点符号
return dataObj[keyName];
}
处理完取值的问题,接下来就是如何处理嵌套 tokens 的问题了,首先我们需要调用 lookUp 函数取到传入的嵌套 token 所需要的数据,拿到数据后根据数据的长度开始递归,拼接字符串。
注意:这里递归并非是 parseArray 函数自己调用自己,而是 parseArray 函数调用 renderTemplate 函数,因为 renderTemplate 就是将 tokens 与数据结合变为 DOM 字符串的方法,所以 parseArray 拿到数据需要调用 renderTemplate 函数处理当前嵌套层级的 tokens,然后在调用renderTemplate 时若遇到 tokens 嵌套开始标志,则又会调用 parseArray函数进行处理,所以这里的递归并非那种显而易见的递归。 这里的逻辑需要好好捋一捋。
模拟过程
我么们处理下面的tokens
// tokens
[
["text", "<div><ul>"],
["#", "students", [
["text", "<li class="myli">"],
["name", "name"],
["text", "</li>"],
]],
["text", "</ul></div>"]
]
// 数据
data:{
students: [
[name: "小明"],
[name: "小强"]
]
}
首先调用renderTemplate函数处理第一个元素标志为 text,记字符串为
resultStr=<div><ul>
接着处理第二个元素,标志位 #,说明这里有嵌套,调用 parseArray函数处理嵌套 tokens,先拿到嵌套数据为v=[[name: "小明"],[name: "小强"]],然后根据 v 的长度循环调用 renderTemplate 函数,并且传给它的参数是([["text", "<li class="myli">"],["name", "name"],["text", "</li>"]],v[i]),循环两次本次递归结束后,renderTemplate返回
<li class="myli">小明</li><li class="myli">小强</li>
所以parseArray中
resultStr=<li class="myli">小明</li><li class="myli">
再将这个值返回给上一层,此时renderTemplate中
resultStr=<div><ul><li class="myli">小明</li><li class="myli">
然后再由renderTemplate函数继续遍历解析剩下的tokens即["text", "</ol></div>"],最终得到完整的 DOM 字符串
resultStr=<div><ul><li class="myli">小明</li><li class="myli">/ul></div>
得到DOM字符串后在上树就可以创建DOM了
import lookUp from "./Lookup";
import renderTemplate from "./renderTemplate";
export default function parseArray(token, data) {
// 得到整体数据data中这个数组要使用的部分
const v = lookUp(data, token[1]);
// 结果字符串
let resultStr = '';
// 遍历v数组,v一定是数组
// 注意,下面这个循环可能是整个包中最难思考的一个循环
// 它是遍历数据,而不是遍历tokens。数组中的数据有几条,就要遍历几条。
for (let i = 0; i < v.length; i++) {
// 这里要补一个“.”属性
// 拼接
resultStr += renderTemplate(token[2], {
...v[i],
'.': v[i]
});
}
return resultStr;
}
总结
可见一个简单的模板引擎总体来说就做了两步工作:1、将模板转为 tokens,2、将 tokens 结合数据转为真是 DOM。结合 vue 第一步不就是编译过程,第二步就是渲染过程,tokens 就是虚拟DOM。所以万变不离其宗。
我们在实现简单 mustache 模板引擎的过程中遇到了很多问题,也学习到了很多巧妙的解决办法。比如说处理多级嵌套 tokens 是巧妙地利用栈结构和引用,使用一个搜集器,利用它指向的变化,实现了 tokens 的多级嵌套结构。 这大概就是我们学习源码的意义,学习前辈的智慧,解决自己的问题。这也许就是我们码农的传承吧!
好了,这篇博客就到这里了,我是孤城浪人,一名国庆节还在码字的菜鸟,此项目已开源到github。
















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









