







背景:阿东做了一个根据设置的规则进行匹配的功能,最终考虑使用 Groovy 脚本实现动态规则匹配。由于系统并发较高(日峰值 QPS 读 + 写 5W 左右)上线前需要进行一波压力测试,测试环境实例数 1 个,容器配置较低(4核4G)。
一. 压测
使用 jmeter 进行一波压力测试:
1. 设置线程组和 HTTP 接口信息
2. 设置结果树和聚合报告
3. 设置 2000 线程执行 300 秒,间隔 1 秒
执行没一会就收到 CPU 占用 100% 的告警,心里初步想法是 GC 线程导致。
二. 内存泄漏排查
赶紧登录实例容器一看究竟!
找到 Java 应用的进程 id:
jps使用 top 命令动态展示该 Java 应用下的 CPU 占用高的子进程:
top -Hp 1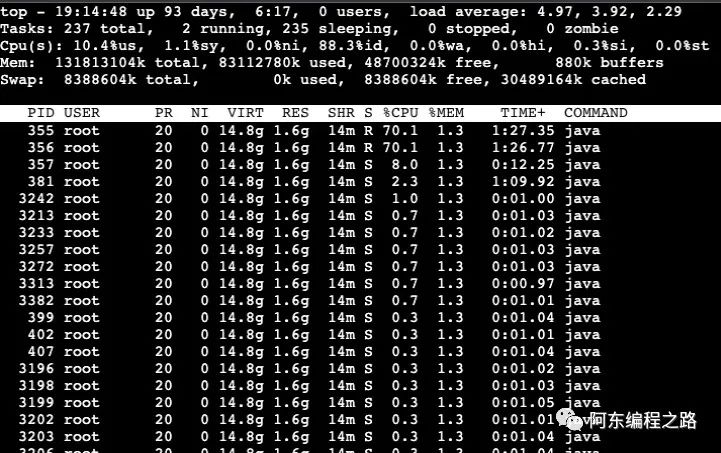
发现进程号为 355 和 356 的进程 CPU 已经飙到 70% 多!
因为 jstack 打印堆栈信息的线程 id 是 16 进制,所以需要先将线程 id 转换为 16 进制格式数据:
printf "%x" 355得到结果为 163
使用 jstack 命令打印线程堆栈信息:
jstack 1 | grep 163
果然是 GC 线程导致 CPU 飙高,可以得出是空闲内存不足(Java 堆区没有空间分配新对象)导致频繁 GC。
再通过 jstat 命令查看 GC 情况:
jstat -gcutil 1 2000
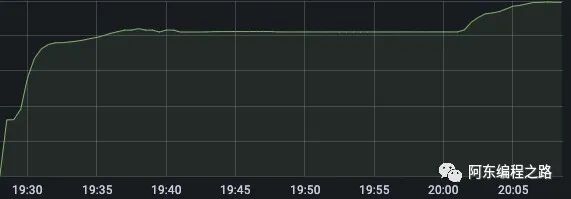
(内存占用曲线)
看到发生 Full GC 一百五十多次,并且内存曲线一直呈上升趋势无降低,基本可以判断发生了内存泄漏。
但是内存泄漏分为 堆内内存泄漏 和 堆外内存泄漏,需要再次判断下( -heap 参数打印出 Java 堆详细信息):
jmap -heap 1
看到 CMS 垃圾收集的区域(也就是老年代)占用达到 99.999%,庆幸发生的是堆内内存泄漏,可控的!
所以我们需要将堆快照 dump 下来进行内存分析看下到底是哪个地方导致的内存泄漏。
使用 jmap -dump 生成 Java 堆转储快照(live 参数代表 dump 存活对象):
jmap -dump:live,format=b,file=OOMDump.bin 1提示“Heap dump file created”代表生成完成,将堆 dump 文件 scp 到本地。
我们使用 Java 自带内存分析工具 jvisualvm 来分析下内存泄漏,本地终端执行启动 jvisualvm:
jvisualvm将 OOMDump.bin 文件装入内存分析工具进行分析:

点进占用内存大小最多的类,查看 GC 引用链:
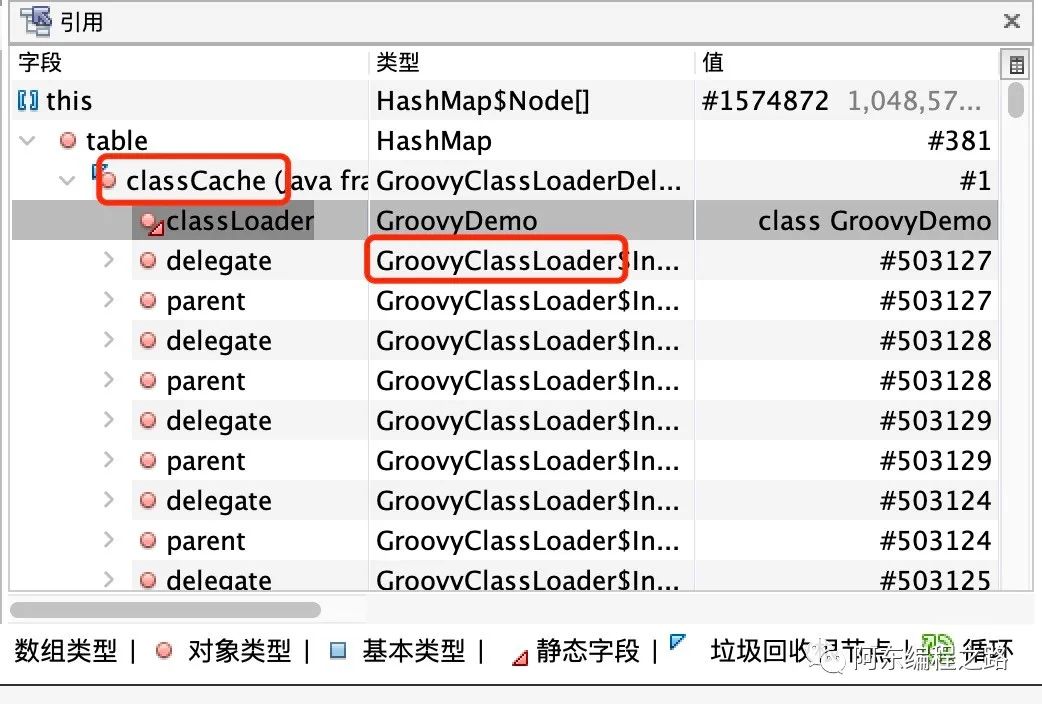
发现是 GroovyClassLoader 类下的 classCahe 变量造成的内存泄漏。
Show Me The Code!来看下业务代码怎么写的:
/**
* 执行脚本
* @param script 脚本,例如:"return '1'.equals(a)"
* @param params 脚本变量,例如:"'a':'1'"
* @return 执行结果
*/
public static Boolean executeGroovy(String script, Map<String, String> params) {
// 使用 groovyClassLoader 将脚本加载成 Groovy 对象
Class groovyClass = groovyClassLoader.parseClass(script);
if (groovyClass == null) {
return false;
}
Binding binding = new Binding();
// 绑定变量
params.entrySet().stream().forEach(e -> {
binding.setVariable(e.getKey(), e.getValue());
});
// 创建 Groovy 脚本对象
Script scriptObj = InvokerHelper.createScript(groovyClass, binding);
try {
// 执行脚本
return (Boolean) scriptObj.run();
} catch (Exception e) {
log.error("脚本执行出错,script:{}, error:{}", script, e.getMessage(), e);
return false;
}
}在业务代码里只有在每次调用执行脚本方法 executeGroovy() 开始加载 Groovy 对象时用到了 GroovyClassLoader 类加载器,所以我们来看下源码 groovyClassLoader.parseClass() 方法做了些什么:
public Class parseClass(String text) throws CompilationFailedException {
// 默认以时间戳+脚本的hash值作为groovy的名称
return parseClass(text, "script" + System.currentTimeMillis() +
Math.abs(text.hashCode()) + ".groovy");
}
public Class parseClass(final String text, final String fileName) throws CompilationFailedException {
GroovyCodeSource gcs = AccessController.doPrivileged(new PrivilegedAction<GroovyCodeSource>() {
public GroovyCodeSource run() {
return new GroovyCodeSource(text, fileName, "/groovy/script");
}
});
gcs.setCachable(false);
// 加载
return parseClass(gcs);
}如果不指定名称,GroovyClassLoader 会默认给 Groovy 生成一个以 时间戳 + 脚本的 hash 值作为名称。
protected final Map<String, Class> classCache = new HashMap<String, Class>();
private Class doParseClass(GroovyCodeSource codeSource) {
......
for (Object o : collector.getLoadedClasses()) {
Class clazz = (Class) o;
String clazzName = clazz.getName();
definePackageInternal(clazzName);
// 重点在这里,会将Groovy脚本类放进classCache里
setClassCacheEntry(clazz);
if (clazzName.equals(mainClass)) answer = clazz;
}
return answer;
}
protected void setClassCacheEntry(Class cls) {
// 吐槽一下这里的锁真大!
synchronized (classCache) {
// 以刚才默认生成名称为key,Groovy class对象为value放进classCache
classCache.put(cls.getName(), cls);
}
}最后将刚才默认生成名称为 key、Groovy class 对象为 value 放进 classCache(内存泄漏的罪魁祸首!)
问题似乎已经找到了,因为我们在调用 groovyClassLoader.parseClass() 方法时没有指定名称,所以就算是同样的脚本也会导致 classCache 被无限 set 扩大。而 GC Roots 到内存泄漏对象的引用链的关系是 GroovyClassLoader -> classCache -> table -> Entry,GroovyClassLoader 肯定一直被应用持有(和应用程序生命周期一致),所以会导致 classCache 的元素无法被释放,造成内存泄漏。
三. 问题解决与优化
问题找到了,该考虑如何解决了!
上面分析了我们调用 groovyClassLoader.parseClass() 方法时没有指定名称才会导致这些问题,那我们指定名称呢?
// GroovyClassLoader#parseClass()源码
public Class parseClass(GroovyCodeSource codeSource, boolean shouldCacheSource) throws CompilationFailedException {
synchronized (sourceCache) {
// 从缓存中获取
Class answer = sourceCache.get(codeSource.getName());
if (answer != null) return answer;
answer = doParseClass(codeSource);
// 是否使用缓存
if (shouldCacheSource) sourceCache.put(codeSource.getName(), answer);
return answer;
}
}从源码看确实有 API 自己指定 name,还可以使用缓存,但是这个锁的粒度太大了!肯定会影响性能,其实最新的版本已经将 cache 换成 ConcurrentHashMap,锁粒度缩小为每个 Groovy 类,但是由于目前版本比较稳定且应用内有在使用(场景不同),还是决定在应用层面去优化。
阿东最终决定在 GroovyClassLoader 加上一层本地缓存,加载过的类就以脚本字符串为 key 放进缓存中,并使用软引用修饰 value 防止不同的脚本类过多导致内存溢出(在进行 gc 后如果内存不足会将软引用回收掉),逻辑修改为:
// 本地缓存
private static Map<String, SoftReference<Class>> scriptCache = new ConcurrentHashMap<>();
public static Boolean executeGroovy(String script, Map<String, String> params) {
// 先从本地缓存取,没有再去使用groovyClassLoader加载
SoftReference<Class> softReference = scriptCache.get(script);
Class groovyClass;
if (softReference == null || softReference.get() == null) {
groovyClass = compiledScript(script);
} else {
groovyClass = softReference.get();
}
......
}
// 解析
private static Class compiledScript(String script) {
try {
Class gvClz = groovyClassLoader.parseClass(script);
// 解析完放进缓存
scriptCache.put(script, new SoftReference<>(gvClz));
return gvClz;
} catch (Exception e) {
log.error("编译脚本出错,script:{}, error:{}", script, e.getMessage(), e);
return null;
}
}大概逻辑就是:先从本地缓存拿 Groovy 类,没有再使用 GroovyClassLoader 加载。
针对 classCache,加个定时任务每一小时清空一次。
四. 验证
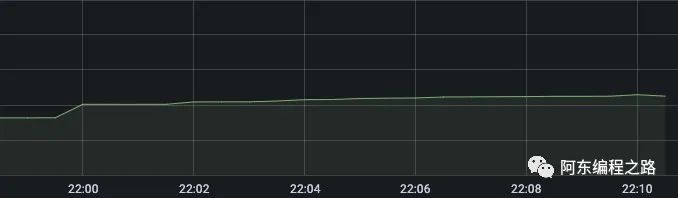
还是使用 jmeter 设置 2000 线程执行 300 秒,间隔 1 秒:内存占用趋势图很平缓,Full GC 只有一次(容器启动会有三次),果然没有什么问题是加缓存解决不了的。

功能顺利上线...
五. 总结
通过这次经历,得出了上线前压测的重要性;如果真在线上遇到内存泄漏,冷静一点,留一台实例,重启其他实例保证线上服务正常运行,并将留下实例的所有对外入口切掉(Nginx节点下线,RPC服务下线,消息队列消费者下线等),对该实例进行内存分析找出问题即可。
如果觉得文章不错可以点个赞和关注!
公众号:阿东编程之路
你好,我是阿东,目前从事后端研发工作。技术更新太快需要一直增加自己的储备,索性就将学到的东西记录下来同时分享给朋友们。未来我会在此公众号分享一些技术以及学习笔记之类的。妥妥的都是干货,跟大家一起成长。















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









