









目录
1.最长公共前后缀
1.1前缀
前缀说的是一个字符串除了最后一个字符以外,所有的子串都算是前缀。
| 前缀 | 字符串:ABABC |
|---|---|
| 前缀1 | A |
| 前缀2 | AB |
| 前缀3 | ABA |
| 前缀4 | ABAB |
以上这个例子就是排除了最后一个字符C,其余不含有尾部元素C的子串都是ABABC的前缀
1.2后缀
后缀说的是一个字符串除了第一个字符以外,所有的子串都算是后缀。
| 后缀 | 字符串:ABABC |
|---|---|
| 后缀1 | C |
| 后缀2 | BC |
| 后缀3 | ABC |
| 后缀4 | BABC |
以上这个例子就是排除了第一个字符A,其余不含有首部元素A的子串都是ABABC的后缀
1.3最长公共前后缀
Q:如何选择出最长公共前后缀?
A:在前缀集合和后缀集合里面找两个相同的子串,并且这两个子串还是最长的,这里相同的子串就是BC了,如果有ABCDEFG是前缀,ABCDEFG是后缀,ABCDE也是前缀之一,ABCDE也是后缀之一,那么就是挑最长的那个ABCDEFG了!
这个“最长公共前后缀”的意义在于在next数组里面,
2、KMP算法过程
2.1例子1
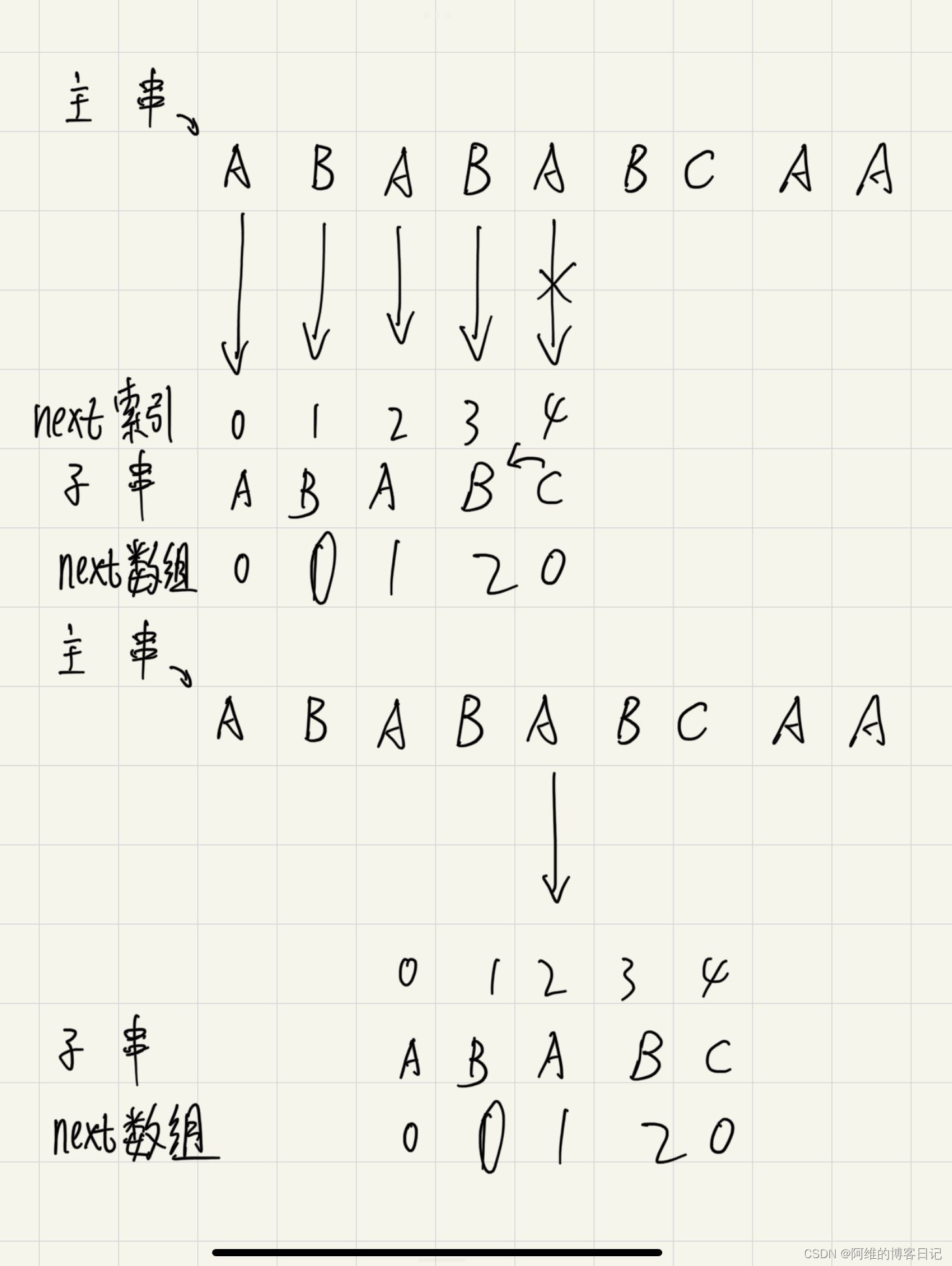
首先是主串和子串挨个字符进行匹配,这里是ABABA都匹配了,这里主串第五个元素A和模式串(图中写为了子串)的第5个元素不匹配,然后模式串ABABC的next数组是对其每个子串计算他的最长公共前后缀的长度
(注意:next长度和模式串的长度是完全一致的,next数组就是标注模式串的最长公共前后缀长度用的!)
| 子串 | 模式串:ABABC | 最长公共前后缀 |
|---|---|---|
| 子串1 | A | 0 |
| 子串2 | AB | 0 |
| 子串3 | ABA | 1 |
| 子串4 | ABAB | 2 |
| 子串5 | ABABC | 0 |
以上表格的第三列00120构成下图中的next数组
因为第5个元素A和模式串的C不匹配,所以我们看模式串不匹配元素所在下标4,到next数组里面也是下标为4的地方的前一个的地方,也就是4-1=3,看下标为3的地方,对应next【3】=2说明ABAB的最长公共前后缀是2,也就是说我们前面匹配过的模式串ABABC中ABAB的最长公共前后缀是2,ABAB的AB是无需再次匹配的!(根据最长公共前后缀的定义及其意义,ABAB最长公共前后缀长度是2,ABAB的AB长度就是2,后缀也就是前缀!直接乾坤大挪移!)之后依次匹配主串和模式串,发现后续字符相等,完成匹配!over!
2.2例子2

注意:我上面这个图,最下面的红字“前2个字符不匹配”说的是AB不用再次拿去匹配了,因为前面已经匹配过了!
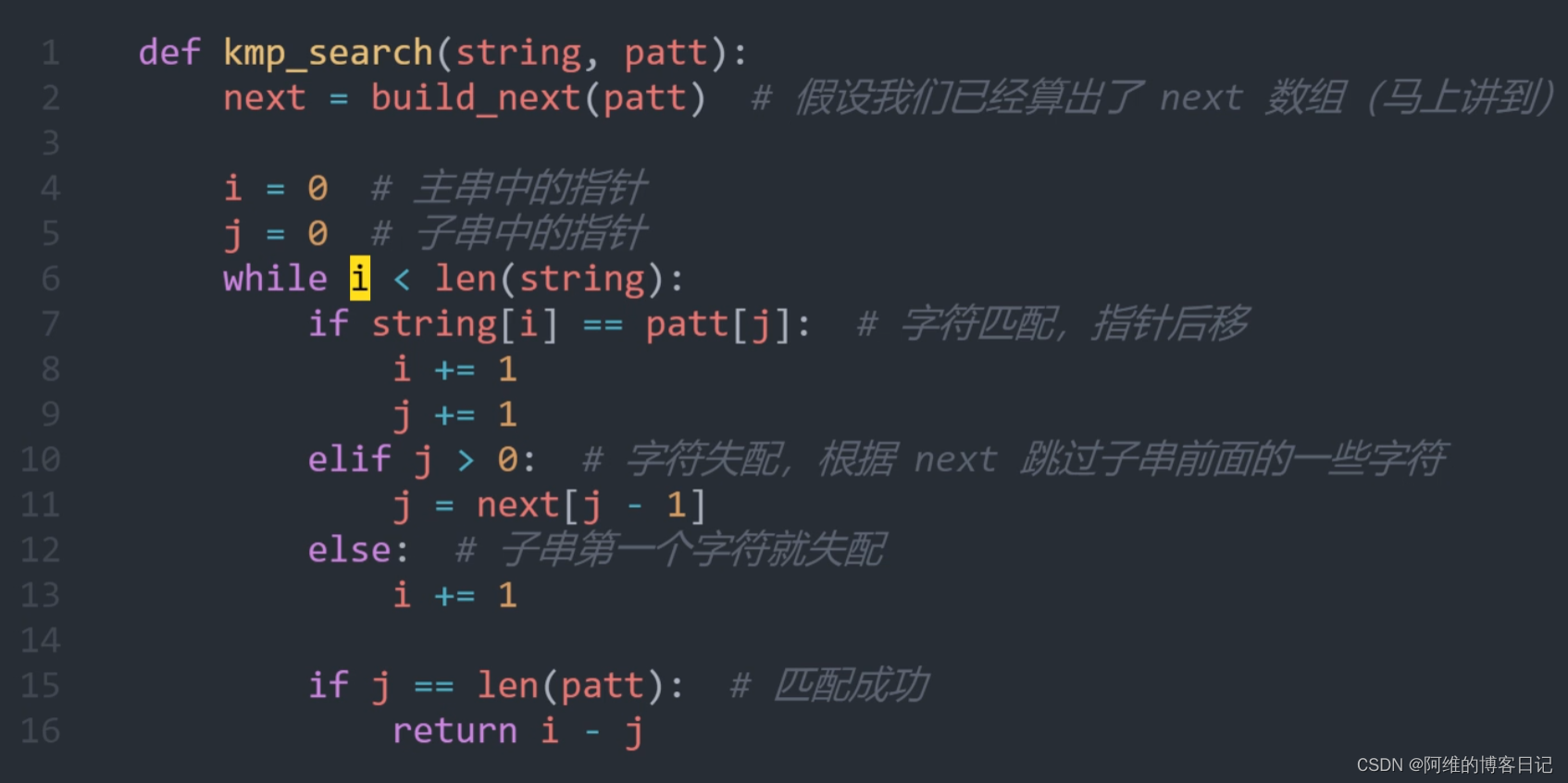
2.3Python代码:
2.4next数组的计算过程
这部分非常难以用文字描述,简单暴力清晰的讲解交给B站一位up主,记得反复观看7次以上,一定大有所获!
链接:【最浅显易懂的 KMP 算法讲解】 【精准空降到 04:21】

3.KMP算法对应的leetcode题目
https://leetcode.cn/problems/repeated-substring-pattern/
点击此处直接访问---->459. 重复的子字符串
class Solution {
public:
vector<int> build_next(const string& patt){
vector<int> next(1,0);
int prefix_len=0;
int i=1;
while(i<patt.size()){
if(patt[prefix_len]==patt[i]){
prefix_len++;
next.push_back(prefix_len);
i++;
}else{
if(prefix_len==0){
next.push_back(0);
i++;
}else{
prefix_len=next[prefix_len-1];
}
}
}
return next;
}
int kmp_search(const string& str,const string& patt){
vector<int> next=build_next(patt);
int i=0,j=0;
for(;i<str.size();){
if(str[i]==patt[j]){
i++;
j++;
}
else if(j>0){
j=next[j-1];
}
else {
i++;
}
if(j==patt.size()){
return i-j;
}
}
return -1;
}
bool repeatedSubstringPattern(string s) {
string ss=s+s;
return kmp_search(ss.substr(1,ss.size()-2),s)!=-1;
}
};
注意!C++string类中对应的substr方法的形参,index是起始索引,num是指定了从index开始,需要截取多少位字符!不要惯性思维的认为是JAVA中的substr的起始索引和结束索引!二者不一样!

















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











