







目录
程序功能
输入源程序,进行词法分析,输出词法分析的(类别编码,值)二元式序列;
能够发现文件输入串的错误;
能够识别注释的开始与结束;
能够根据代码的换行使二元式序列跟随换行。
目标任务
以下为正则文法所描述的 C 语言子集单词符号的示例,请补充单词符号:++,--, >>, <<, += , -= ,*=, /= ,&&(逻辑与),||(逻辑或),!(逻辑非)等等,给出补充后描述 C 语言子集单词符号的正则文法,设计并实现其词法分析程序。
<标识符>→字母︱ <标识符>字母︱ <标识符>数字
<无符号整数>→数字︱ <无符号整数>数字
<单字符分界符> →+ ︱- ︱* ︱;︱, ︱(︱) ︱{︱} <双字符分界符>→<大于>=︱<小于>=︱<小于>>︱<感叹号>=︱<等于>=︱<斜竖>*
<小于>→<
<等于>→=
<大于>→>
<斜竖> →/
<感叹号>→!
该语言的保留字 :void、int、float、double、if、else、for、do、while 等等(也可补充)。
(1)可将该语言设计成大小写不敏感,也可设计成大小写敏感,用户定义的标识符最长不超过 32 个字符;
(2)字母为 a-z A-Z,数字为 0-9;
(3)可以对上述文法进行扩充和改造;
(4)“/*……*/”和“//”(一行内)为程序的注释部分。
(5)给出各单词符号的类别编码;
(6)词法分析程序应能发现输入串中的错误;
(7)词法分析作为单独一遍编写,词法分析结果为二元式序列组成的中间文件;
(8)设计两个测试用例(尽可能完备),并给出测试结果。
正则文法
G[<单词符号>]:
<单词符号> → <标识符> ε ︱ <无符号整数> ε︱<单字符分界符> ε︱<双字符分界符>ε︱......
<标识符>→[a-z A-Z]︱<标识符>[a-z A-Z]︱<标识符>[0-9]
<无符号整数>→[0-9]︱<无符号整数>[0-9]
<单字符分界符> →; ︱, ︱(︱)︱[︱]︱{︱}︱%
<双字符分界符>→<大于>= ︱ <小于>= ︱ <等于>= ︱ <感叹号> = ︱ <斜竖> *︱<加号>+︱<加号>=︱<减号>-︱<减号>=︱<星号>=︱<斜竖>=︱<大于>>︱<小于><︱<与符号>&︱<竖线>|︱<斜竖>/︱<星号>/
<小于>→<
<等于>→=
<大于>→>
<感叹号> →!
<斜竖> →/
<加号> →+
<减号> →-
<星号> →*
<与符号> →&
单词符号的类别编码
| 单词符号 | 类别编码 | 单词符号 | 类别编码 |
| 标识符 | 1 | } | 24 |
| 无符号整数 | 2 | > | 25 |
| void | 3 | < | 26 |
| int | 4 | = | 27 |
| float | 5 | ! | 28 |
| double | 6 | / | 29 |
| if | 7 | >= | 30 |
| else | 8 | <= | 31 |
| for | 9 | != | 32 |
| do | 10 | == | 33 |
| while | 11 | % | 34 |
| return | 12 | ++ | 35 |
| break | 13 | -- | 36 |
| + | 14 | += | 37 |
| - | 15 | -= | 38 |
| * | 16 | *= | 39 |
| ; | 17 | /= | 40 |
| , | 18 | >> | 41 |
| ( | 19 | << | 42 |
| ) | 20 | && | 43 |
| [ | 21 | || | 44 |
| ] | 22 | | | 45 |
| { | 23 | & | 46 |
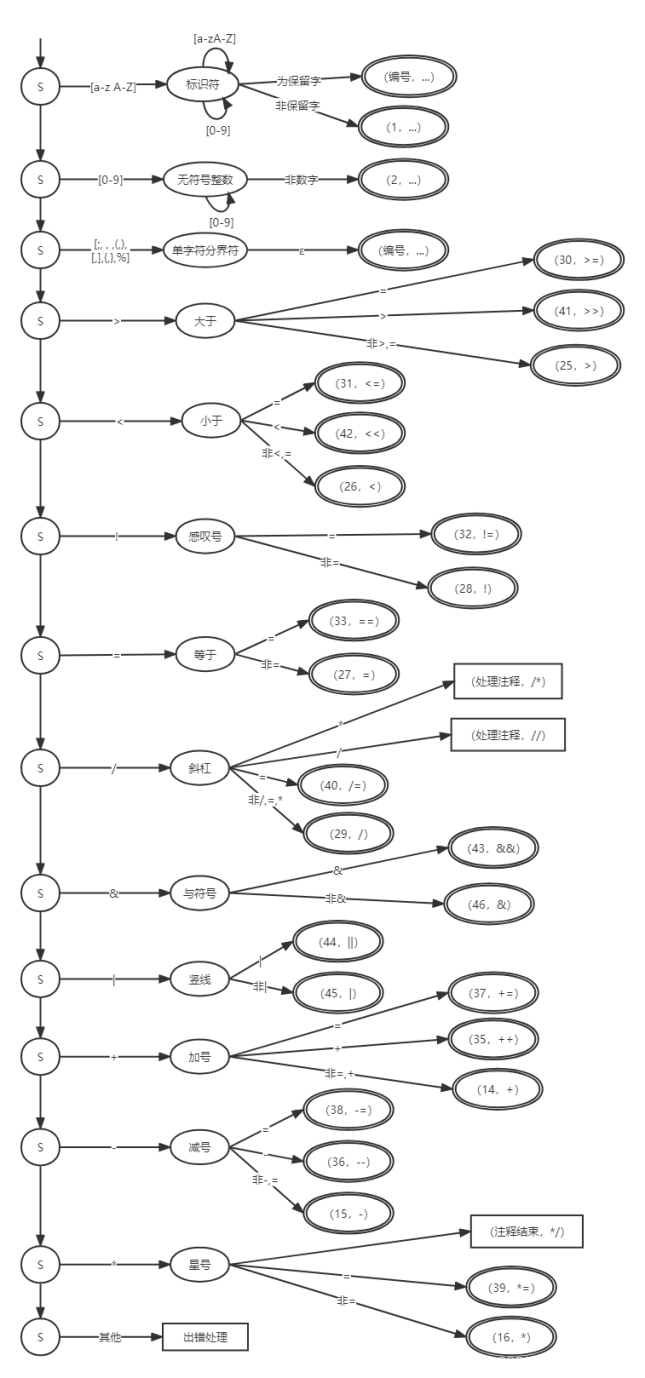
状态转换图
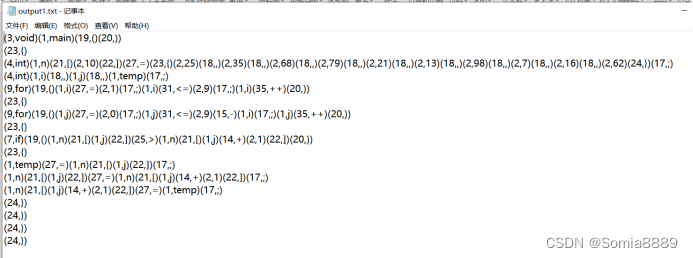
测试用例
用例1:

结果:
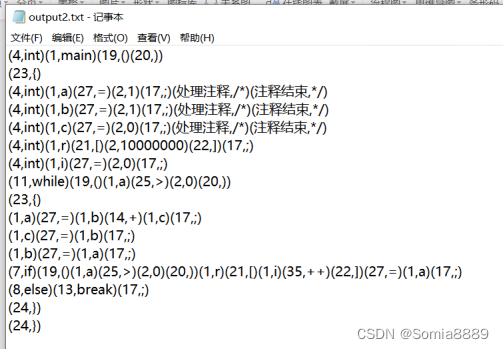
用例2:

结果:
完整代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int isLetter(char c){
if((c>='a'&&c<='z')||(c>='A'&&c<='Z')) return 1;
else return 0;
}
int isNumber(char c){
if(c>='0'&&c<='9') return 1;
else return 0;
}
int getIdentifier_id(char s[]){
if(strcmp(s,"void")==0){
return 3;
}else if(strcmp(s,"int")==0){
return 4;
}else if(strcmp(s,"float")==0){
return 5;
}else if(strcmp(s,"double")==0){
return 6;
}else if(strcmp(s,"if")==0){
return 7;
}else if(strcmp(s,"else")==0){
return 8;
}else if(strcmp(s,"for")==0){
return 9;
}else if(strcmp(s,"do")==0){
return 10;
}else if(strcmp(s,"while")==0){
return 11;
}else if(strcmp(s,"return")==0){
return 12;
}else if(strcmp(s,"break")==0){
return 13;
}else{
return 1;
}
}
int getSinglechar_id(char c){
if(c==';') return 17;
else if(c==',') return 18;
else if(c=='(') return 19;
else if(c==')') return 20;
else if(c=='[') return 21;
else if(c==']') return 22;
else if(c=='{') return 23;
else if(c=='}') return 24;
else if(c=='%') return 34;
else return 0;
}
int main(){
FILE *fp=NULL;
fp=fopen("t4.txt","r");
FILE *fw=NULL;
fw=fopen("test4.txt","at+");
char ch;
ch=fgetc(fp);
while(!feof(fp)){
if(ch==' '||ch=='\t'){
ch=fgetc(fp);
continue;
}else if(ch=='\n'){
fprintf(fw,"\n");
ch=fgetc(fp);
continue;
}else if(isLetter(ch)==1){
char s1[32];
int i=0;
s1[i++]=ch;
do{
ch=fgetc(fp);
s1[i++]=ch;
}while(isLetter(ch)==1||isNumber(ch)==1);
s1[i-1]='\0';
int id=getIdentifier_id(s1);
fprintf(fw,"(%d,%s)",id,s1);
}else if(isNumber(ch)==1){
char s2[32];
int i=0;
s2[i++]=ch;
do{
ch=fgetc(fp);
s2[i++]=ch;
}while(isNumber(ch)==1);
s2[i-1]='\0';
fprintf(fw,"(2,%s)",s2);
}else if(getSinglechar_id(ch)!=0){
fprintf(fw,"(%d,%c)",getSinglechar_id(ch),ch);
ch=fgetc(fp);
}else if(ch=='>'){
ch=fgetc(fp);
if(ch=='='){
fprintf(fw,"(30,>=)");
ch=fgetc(fp);
}else if(ch=='>'){
fprintf(fw,"(41,>>)");
ch=fgetc(fp);
}else{
fprintf(fw,"(25,>)");
}
}else if(ch=='<'){
ch=fgetc(fp);
if(ch=='='){
fprintf(fw,"(31,<=)");
ch=fgetc(fp);
}else if(ch=='<'){
fprintf(fw,"(42,<<)");
ch=fgetc(fp);
}else{
fprintf(fw,"(26,<)");
}
}else if(ch=='!'){
ch=fgetc(fp);
if(ch=='='){
fprintf(fw,"(32,!=)");
ch=fgetc(fp);
}else{
fprintf(fw,"(28,!)");
}
}else if(ch=='='){
ch=fgetc(fp);
if(ch=='='){
fprintf(fw,"(33,==)");
ch=fgetc(fp);
}else{
fprintf(fw,"(27,=)");
}
}else if(ch=='/'){
ch=fgetc(fp);
if(ch=='*'){
fprintf(fw,"(处理注释,/*)");
do{
int flag=0;
ch=fgetc(fp);
while(ch=='*'){
ch=fgetc(fp);
if(ch=='/'){
fprintf(fw,"(注释结束,*/)");
ch=fgetc(fp);
flag=1;
}
}
if(flag==1) break;
}while(1);
}else if(ch=='/'){
fprintf(fw,"(处理注释,//)");
do{
ch=fgetc(fp);
}while(ch!='\n');
fprintf(fw,"\n");
ch=fgetc(fp);
}else if(ch=='='){
fprintf(fw,"(40,/=)");
ch=fgetc(fp);
}else{
fprintf(fw,"(29,/)");
}
}else if(ch=='&'){
ch=fgetc(fp);
if(ch=='&'){
fprintf(fw,"(43,&&)");
ch=fgetc(fp);
}else{
fprintf(fw,"(46,&)");
}
}else if(ch=='|'){
ch=fgetc(fp);
if(ch=='|'){
fprintf(fw,"(44,||)");
ch=fgetc(fp);
}else{
fprintf(fw,"(46,|)");
}
}else if(ch=='+'){
ch=fgetc(fp);
if(ch=='='){
fprintf(fw,"(37,+=)");
ch=fgetc(fp);
}else if(ch=='+'){
fprintf(fw,"(35,++)");
ch=fgetc(fp);
}else{
fprintf(fw,"(14,+)");
}
}else if(ch=='-'){
ch=fgetc(fp);
if(ch=='='){
fprintf(fw,"(38,-=)");
ch=fgetc(fp);
}else if(ch=='-'){
fprintf(fw,"(36,--)");
ch=fgetc(fp);
}else{
fprintf(fw,"(15,-)");
}
}else if(ch=='*'){
ch=fgetc(fp);
if(ch=='='){
fprintf(fw,"(39,*=)");
ch=fgetc(fp);
}else{
fprintf(fw,"(16,*)");
}
}else{
fprintf(fw,"错误:未定义的符号");
printf("错误:未定义的符号\n");
break;
}
}
fclose(fp);
fclose(fw);
printf("二元式序列组成的中间文件已生成\n");
} 














 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









