






数据库cmd操作
- 连接数据库
cmd->
musql -h localhost -P 3306 -u root -p
musql -u root -p
- 断开连接
exit
表的类型
- 真实表
- 虚拟表:通过语句生成的表
- 临时表:create temporary table 表名(表内容,包含字段属性);
临时表不可见,无法在数据库中看到,但是可以正常操作;
临时表在数据库连接断开后,会自动销毁;
作用:一般用于过度,当我们用于处理很复杂的数据时,就可以使用临时表,将要操作的数据存储到临时表中。
复制表
create temporary table 表名 (select 语句); 将虚拟表变为临时表
insert into 表名 (select 语句);
表数据
拿到表->熟悉表->分析逻辑关系
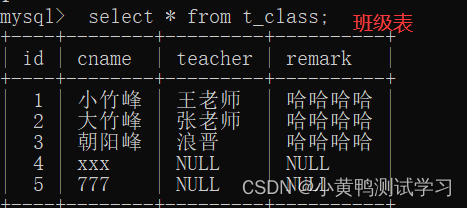
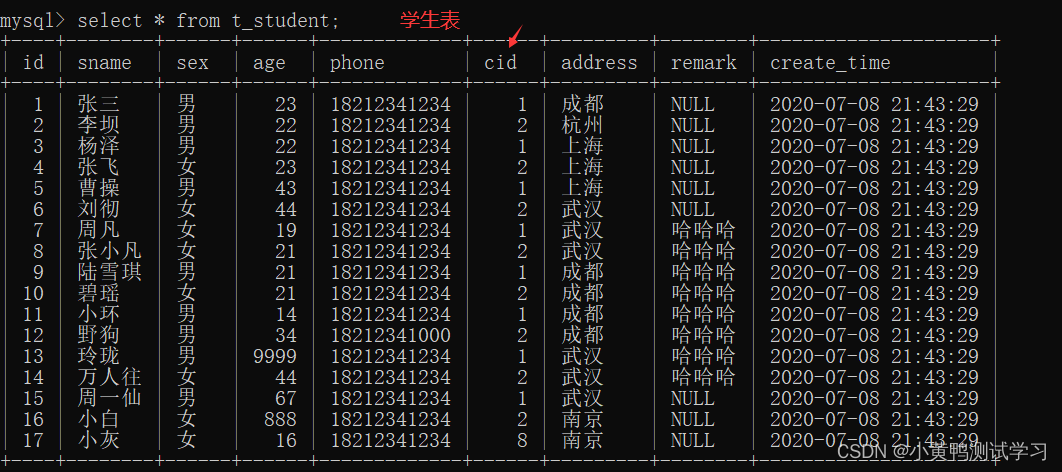
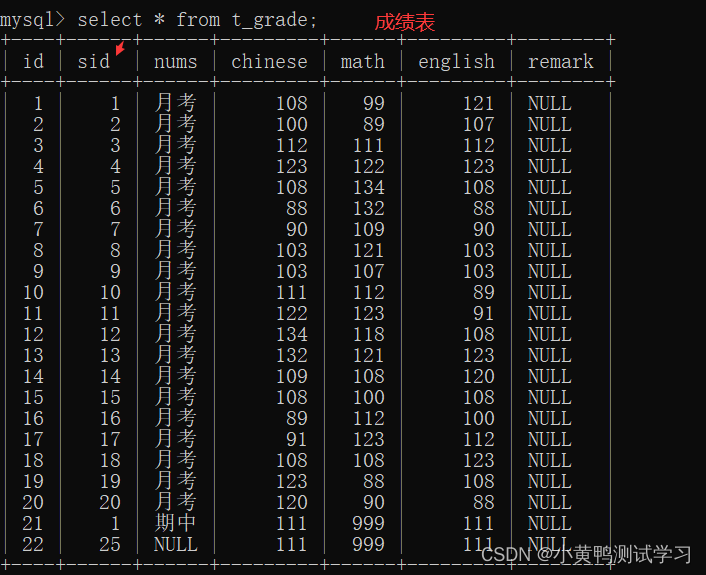
分析:
1.学生表与班级表 用<班级编号>建立关系; t_student.cid= t_class.id
2.学生表与成绩表 用<学号>建立关系; t_student.id= t_class.sid
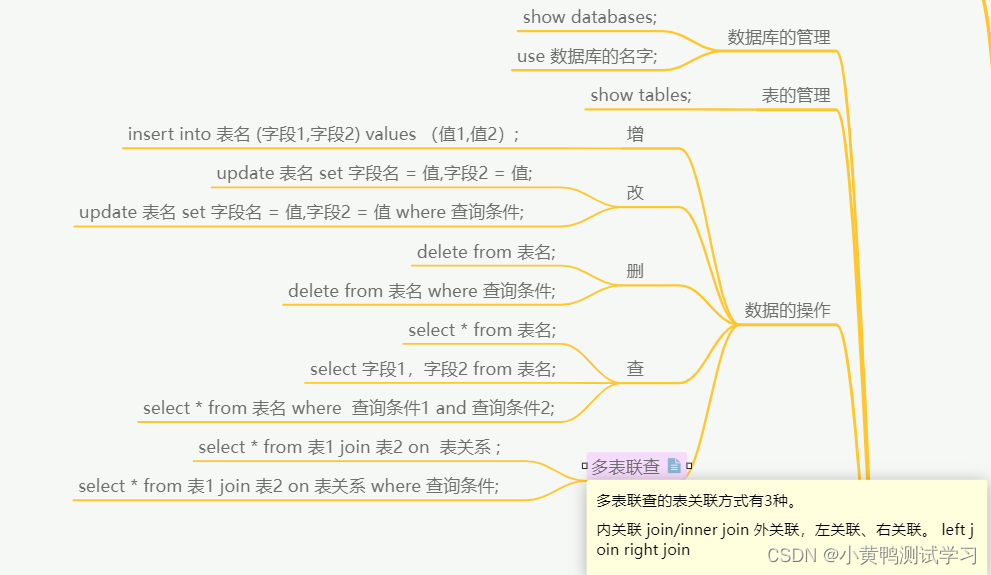
sql语句的类型
- DML:数据操纵语言
新增修改 insert、update、delete - DQL:数据查询语言
查询 select 、from、where - DCL:数据控制语言
功能性、事务 begin、commit、rollback - DDL:数据定义语言
表结构:create、alter、drop
数据库sql语句
-
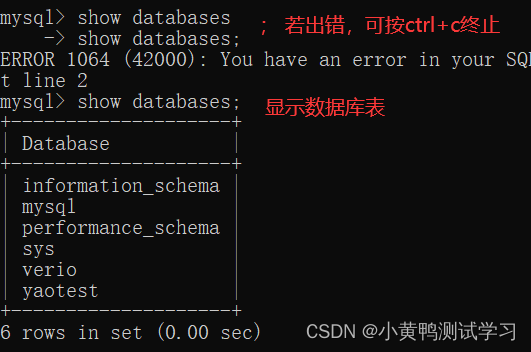
数据库的管理
显示数据库表: show databases;
创建数据库:
create database 数据库的名字 ;
create database 数据库的名字 default charset utf8 字符集(utf8) ;
修改数据库:alter database 数据库的名字 default charset 字符集(utf8);
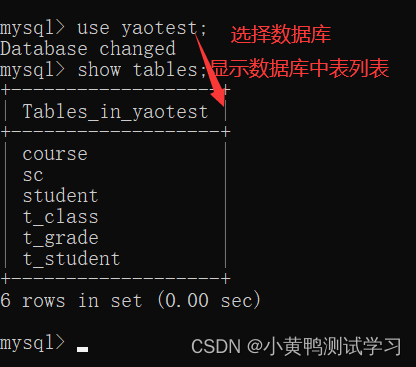
选择数据库表:use 数据库名字;
删除数据库:drop database 数据库名字;
-
表的管理
显示表:show tables;
创建表:create table 表的名字(字段1属性,字段2属性);
字段名 字段类型(字段长度) 必须有
defaulte 默认值
comment 注释
not null 非空
primary key 主键
index 索引
auto_increment 自增
删除表:drop table 表名;
改变表:alter table 表名;
add 字段属性
drop 字段名
rename 新的表名
modify 字段属性
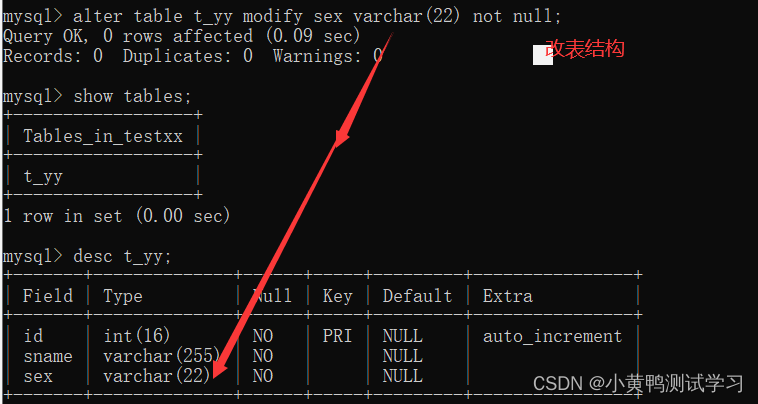
change 字段名 字段属性
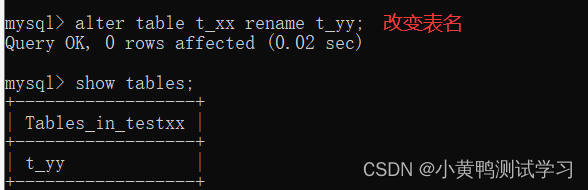
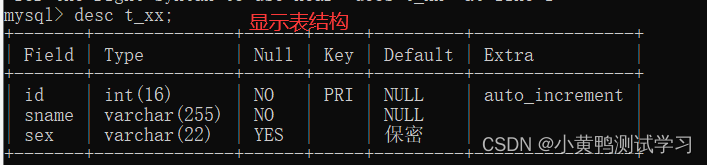
查看表结构:desc 表名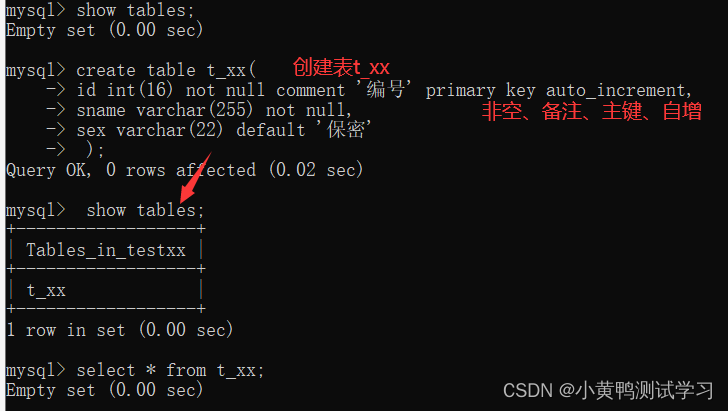
 - 数据的操作-查
- 数据的操作-查-
单表查询
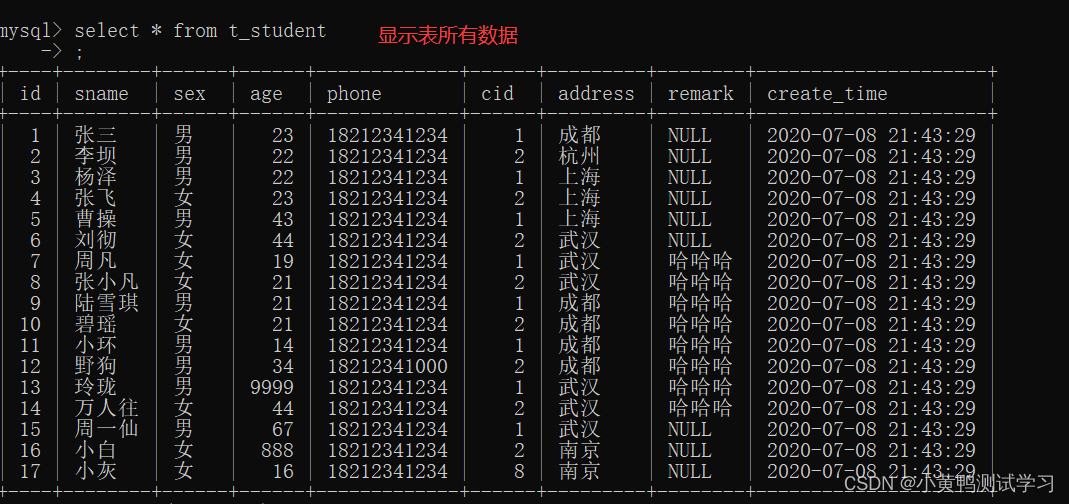
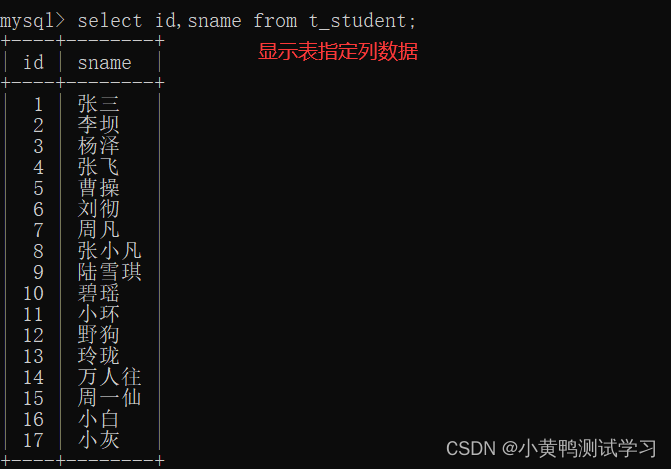
select * from 表名; (*代表所有字段)
select 字段1,字段2 from 表名;
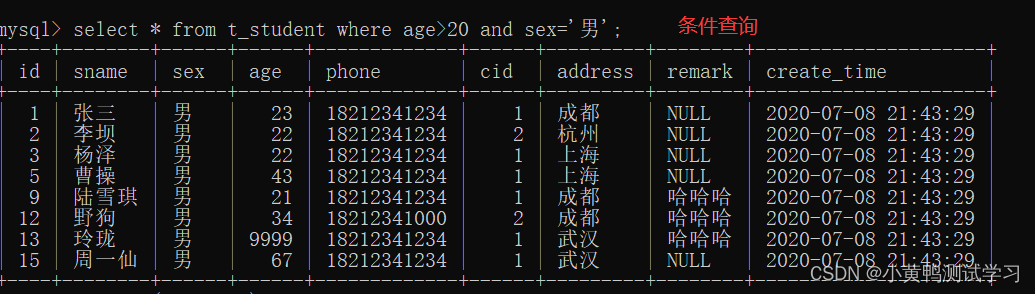
select * from 表名 where 查询条件;
-
多表联查
- 内关联
select * from 表1 join 表2 on 表关系;
select * from 表1 join 表2 on 表关系 where 查询条件;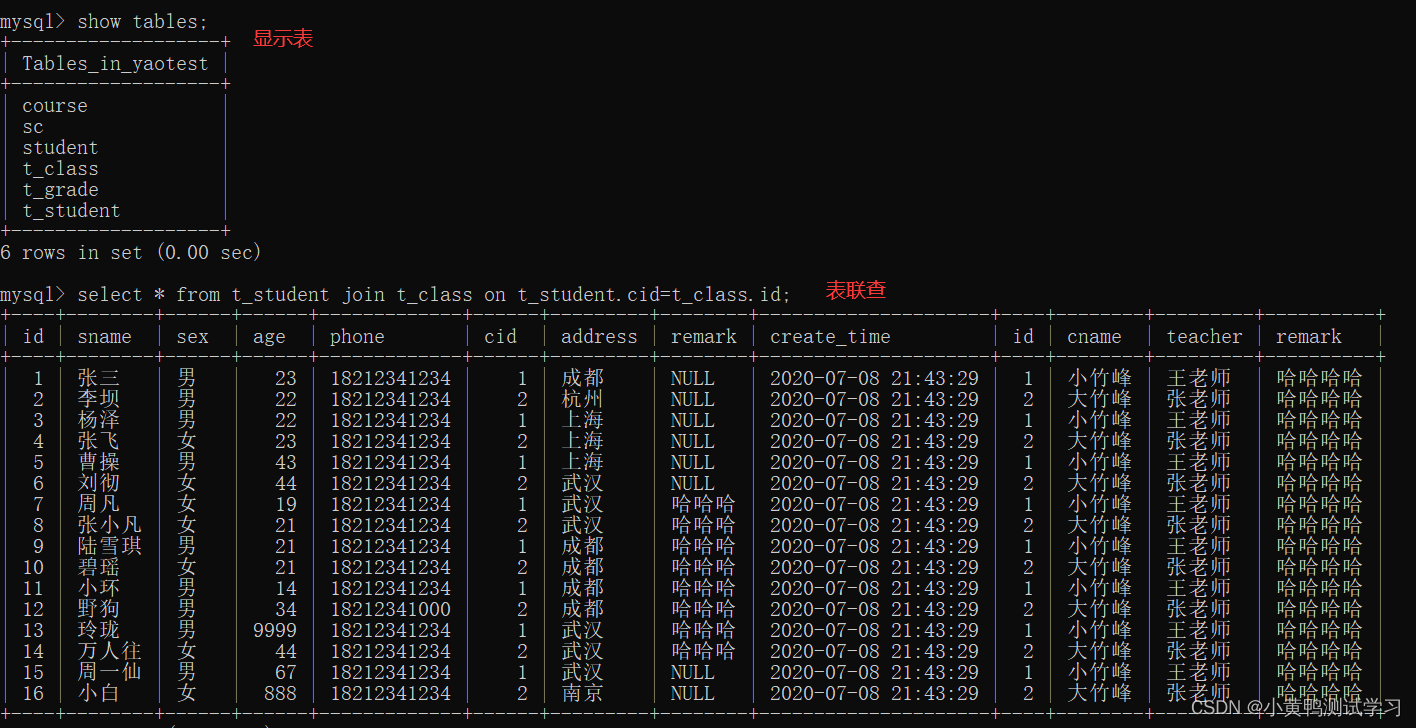

- 外关联
左关联:left join
右关联:right join
select * from t_class left join t_student on t_class.id=t_student.cid;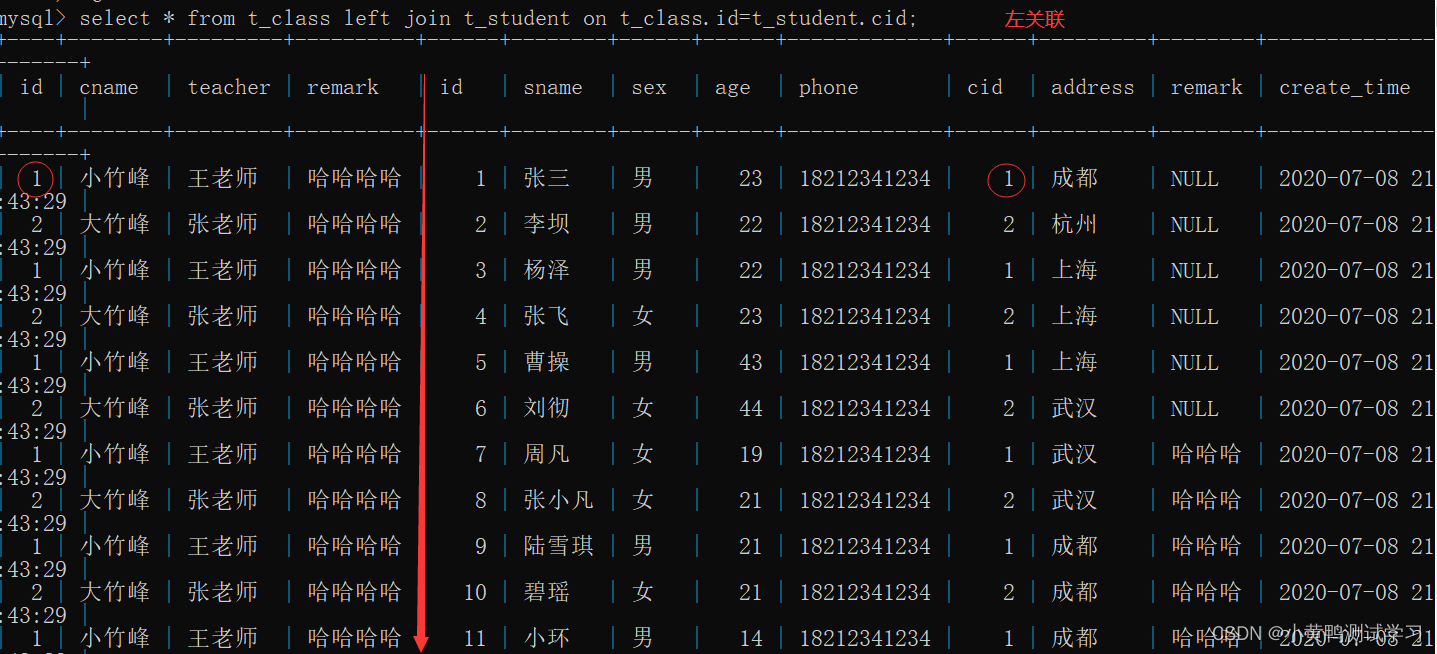
select * from t_class left join t_student on t_class.id=t_student.cid where t_class.teacher=‘王老师’ and t_student.age=14;
- 内关联
-
嵌套查询
-
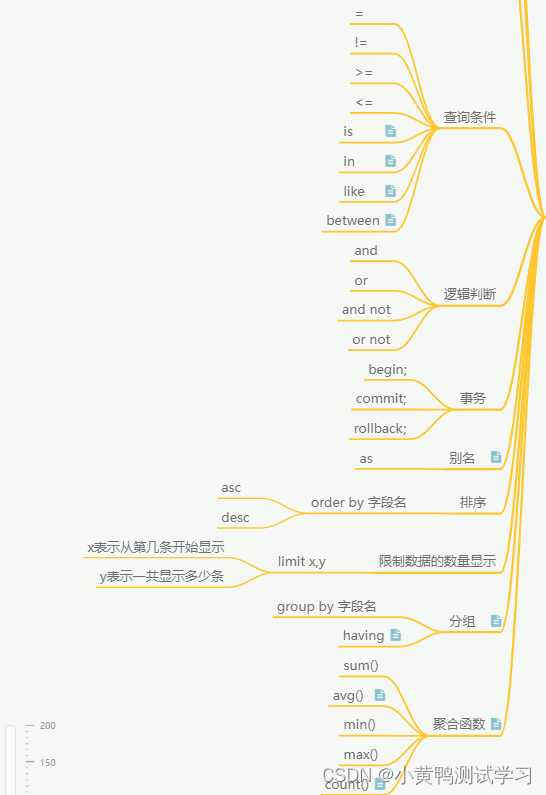
查询条件
= != >= <=
is in like between
is: 判断某个字段的值是否为空。 字段 is null / is not null
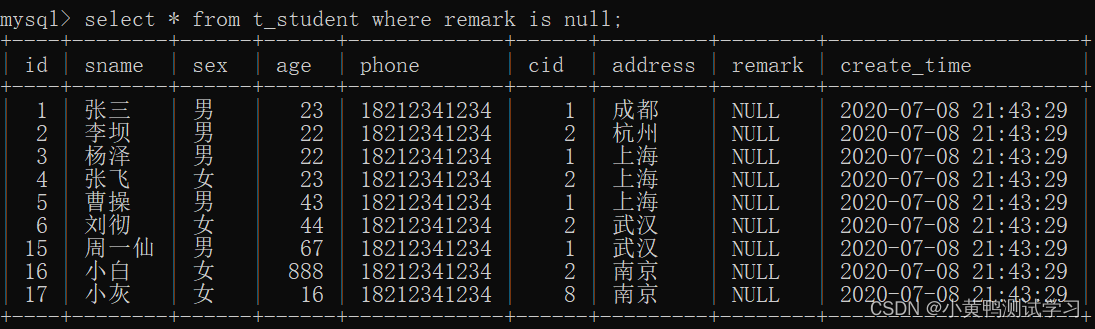
in:判断某个字段的值是否在列表中。字段 in (列表) / not in (列表)
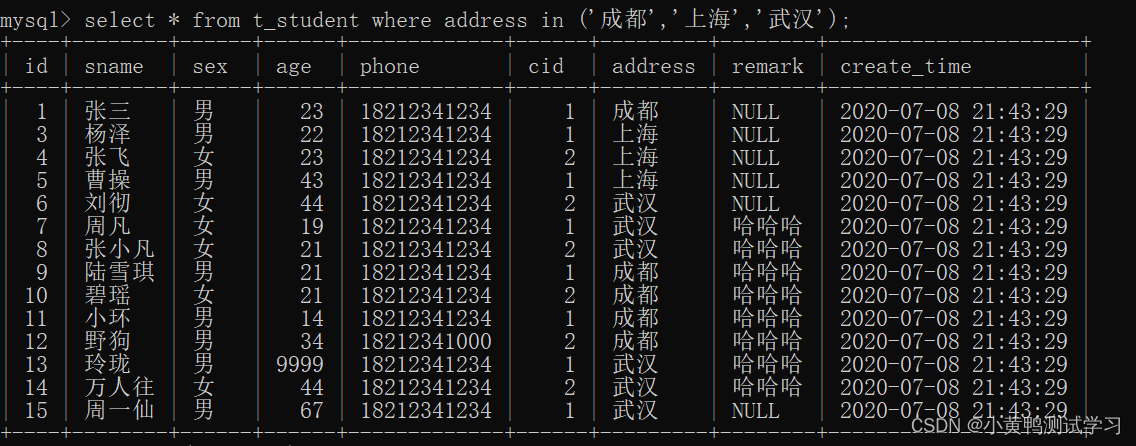 like:用于字符串的模糊查询
like:用于字符串的模糊查询
字段 like ‘张%’; 张开头
字段 like ‘%张’; 张结尾
字段 like ‘%张%’; 姓名中包含张 / not like ’ % ';
between: 判断某个字段的值是否在某个区间内
between …and…/not between …and…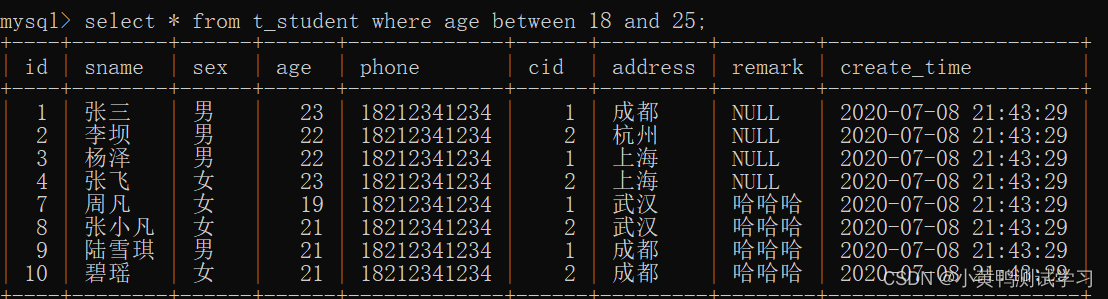
-
逻辑判断
and 、 or 、 and not 、 or not
-
-
数据的操作-增
insert into 表名(字段1,字段2) values (值1,值2);
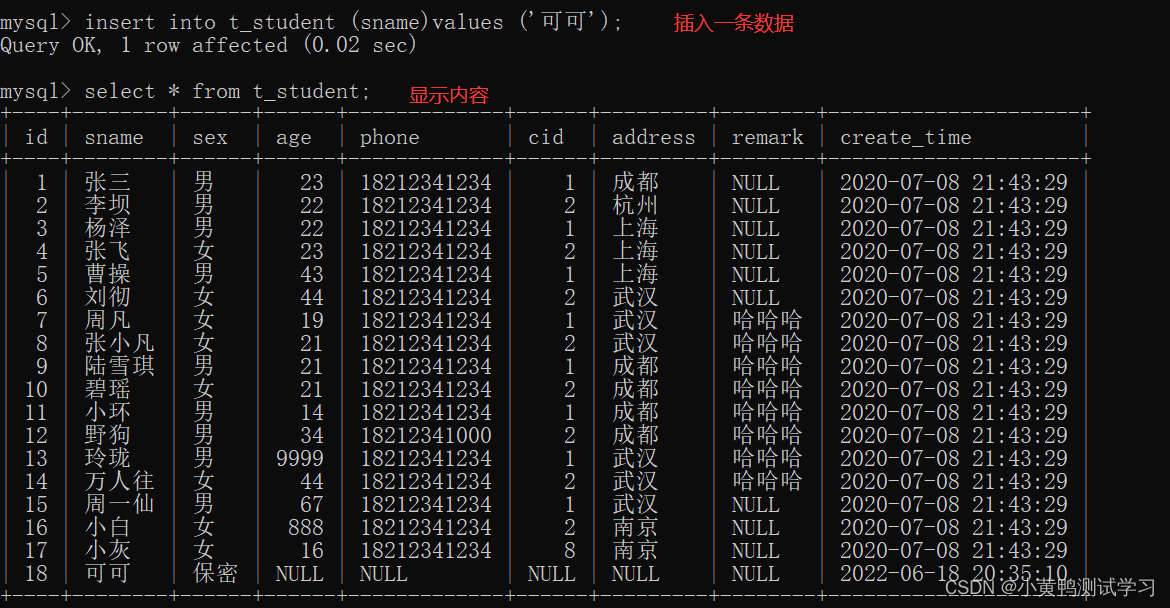
-
数据的操作-改
update 表名 set 字段名1=值, 字段名2=值; 修改所有
update 表名 set 字段名1=值, 字段名2=值 where 查询条件; 修改满足条件的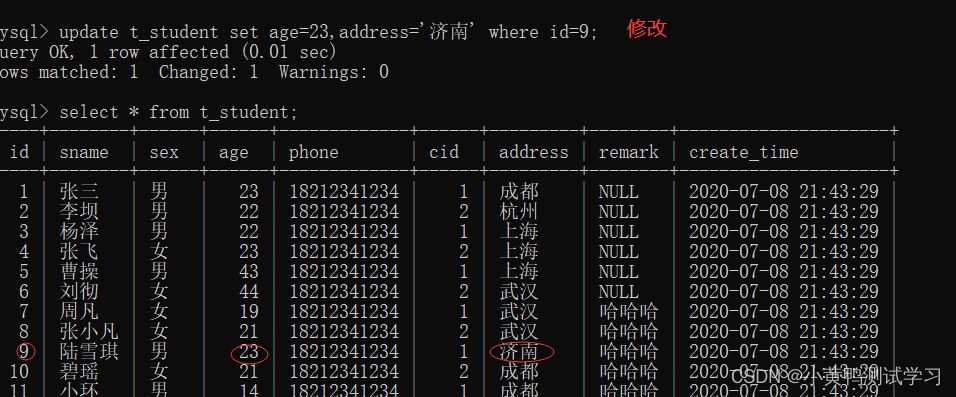
- 数据的操作-删
delete from 表名; 删除该表所有数据
delete from 表名 where 查询条件; 删除满足条件的数据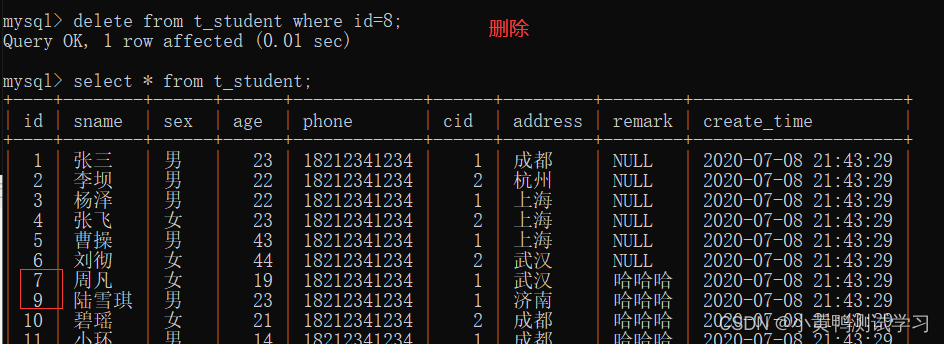
- 数据的操作-删
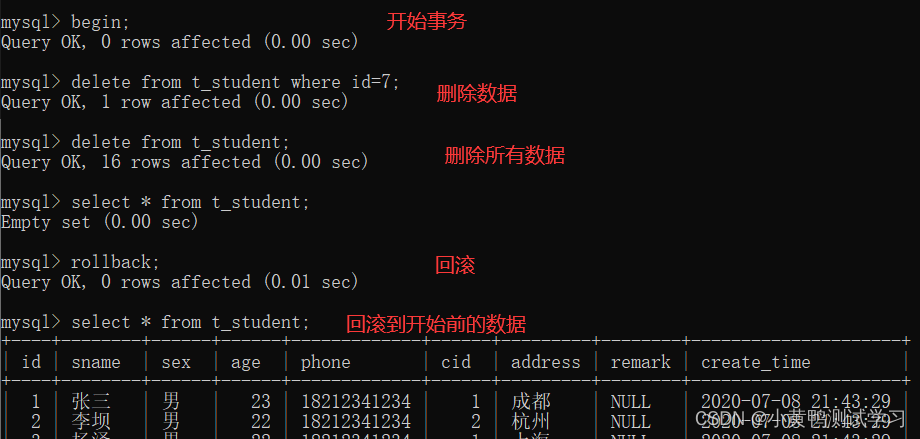
数据库sql语句事务
- begin; 开始事务
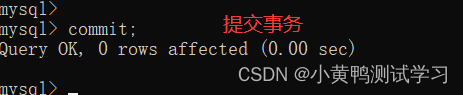
- commit; 提交事务
- rollback; 回滚事务
别名
select t_student.id,t_student.sname,t_class.cname from t_student join t_class on t_student.cid=t_class.id where t_student.sex='女’and t_class.cname=‘大竹峰’;
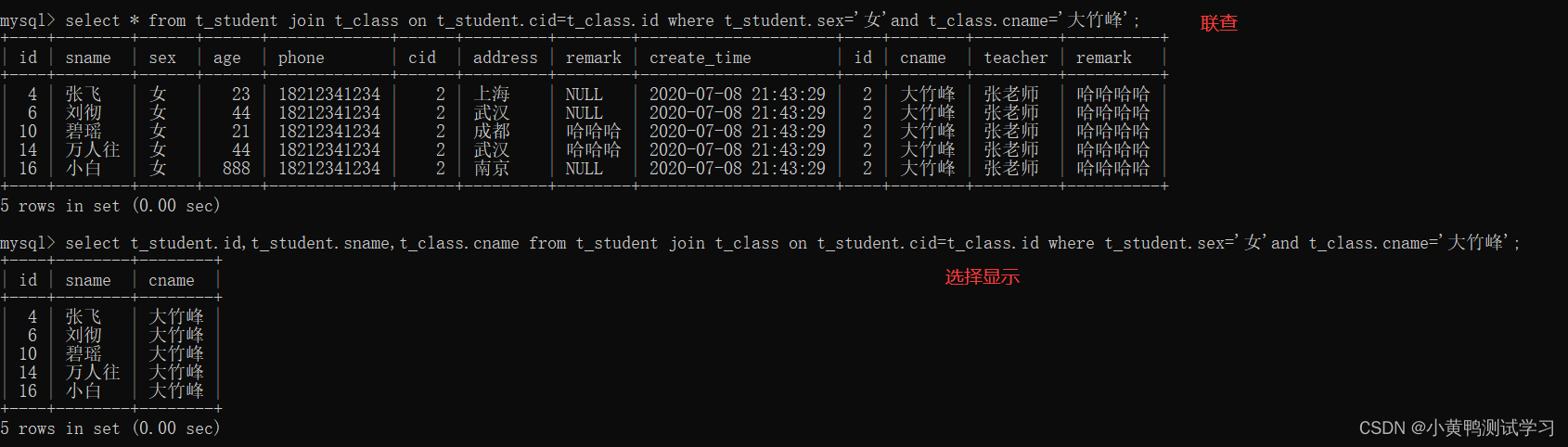
如上图所示,语句太长,可使用别名。
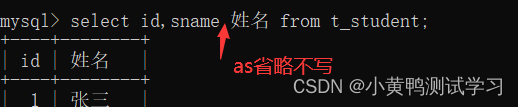
别名:给字段或者表名取一次性的外号。
as 、 可省略不写


排序
order by 排序名;
asc 正序,可省略 从小到大
desc 倒序, 从大到小

limit x,y;
x 表示从第几条开始显示,y 表示一共显示多少条。
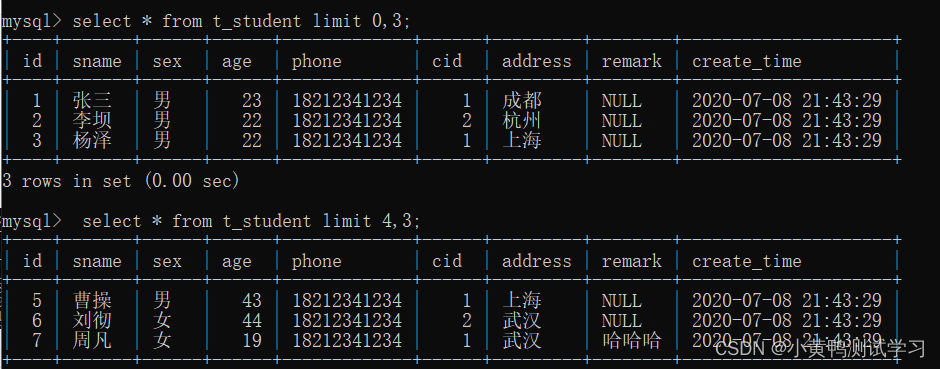
混合使用
查询年龄30以内的女生并且按年龄从大到小进行排序,且只看前三个人的编号、姓名、性别、年龄
select id,sname,sex,age from t_student where sex=‘女’ and age<30 order by age desc limit 0,3;

select a.id,a.sname,a.sex,a.age,b.cname from t_student a join t_class b on a.cid=b.id where a.sex=‘女’ and a.age<30 order by a.age desc limit 0,3;
聚合函数、分组
- 聚合函数
sum() : 求和 ,计算和
min()
max()
avg():求平均值时,会忽略空,比如一共有20行,其中两行数据是空,那么平均值就是 总和➗18
count():在计数时,不会计算空数据。
count(*):在计数时,会计算空数据。计算所有数据。 - 分组
- 分组
- group by: 根据不同的字段为条件,分别进行统计
数据展示必须使用聚合函数,除非它是分组条件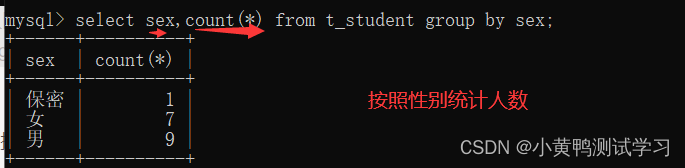

- having:作用和where是一样的,where是分组前,having是对分组后数据进行查询。
select sex,count() from t_student group by sex having count()>3;
- group by: 根据不同的字段为条件,分别进行统计
总结
练习
- 第一题
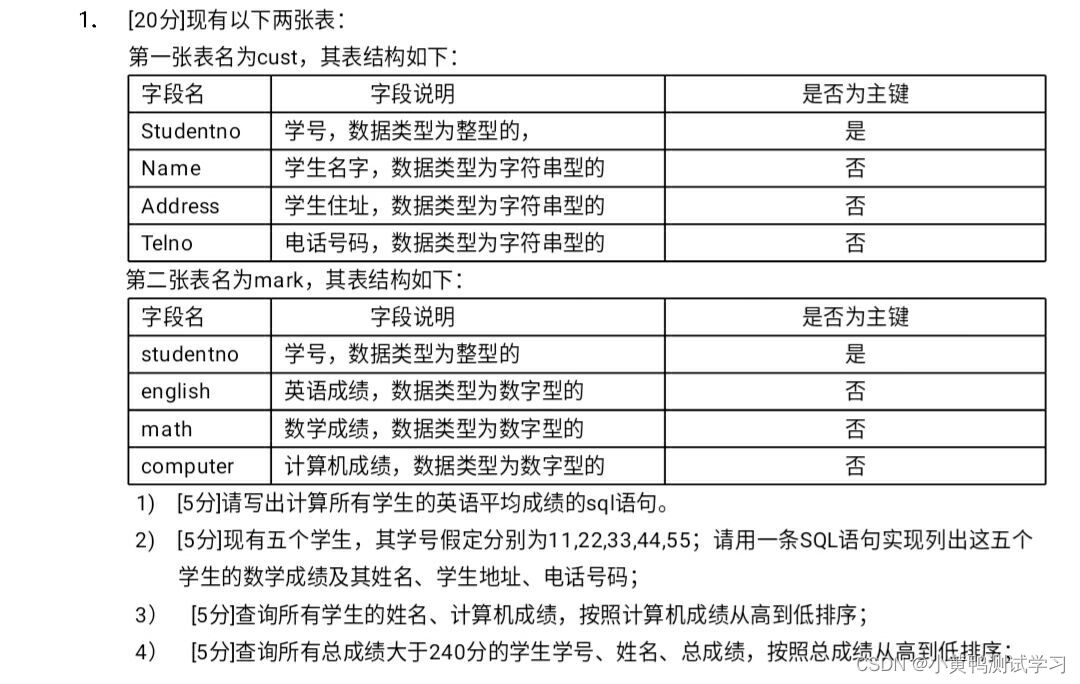
select avg(english) from mark;
select avg(b.english) from cust a join mark b on a.Studentno=b.studentno;
//若english为空
select sum(b.english)/count(*) from cust a join mark b on a.Studentno=b.studentno;
select b.math,a.Name,a.Address,a.Telno from cust a
join mark b on a.Studentno=b.studentno
where a.Studentno in (11,22,33,44,55);
select a.Name,b.computer from cust a
join mark b on a.Studentno=b.studentno
order by b.computer desc;
select a.Studentno,a.Name,(b.english+b.math+b.computer) s from cust a
join mark b on a.Studentno =b.studentno
where s>240
order by s desc;
- 第二题
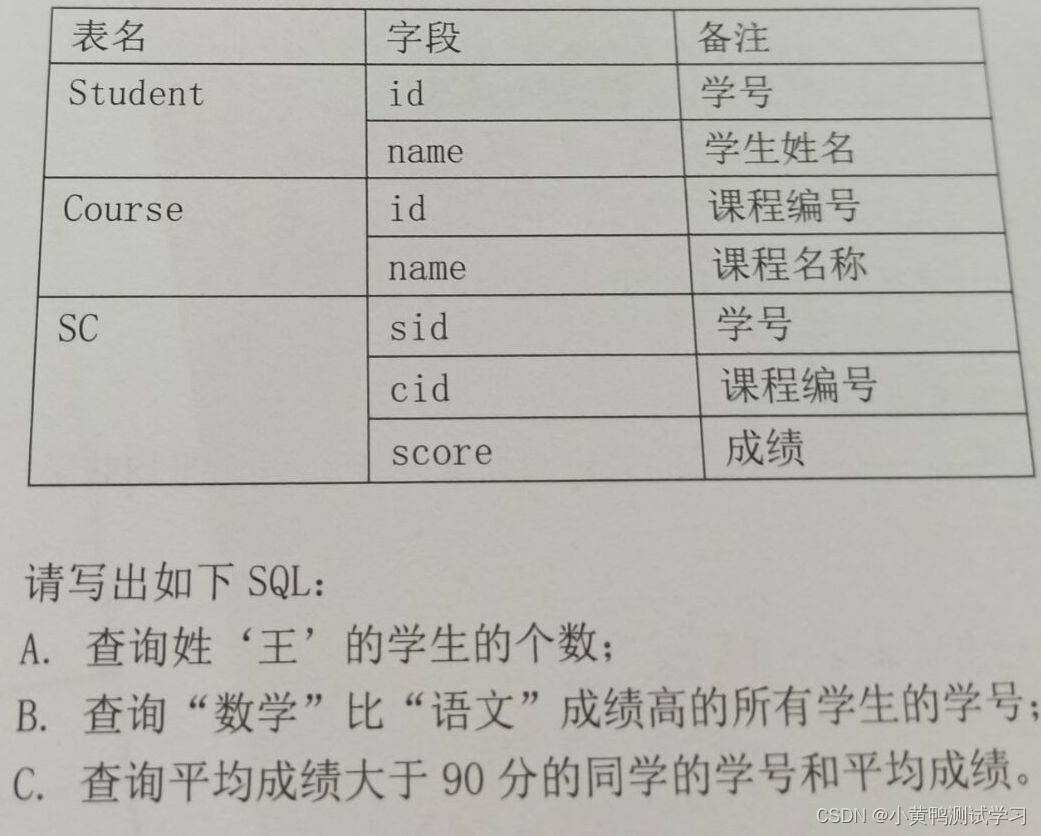
select count(*) from student
where name like '王';
//竖表变为横表
select a.id,a.name,b.score chinese,b1.score math from student a
join sc b on a.id=b.sid
join course c on c,id=b.cid
join sc b1 on a.id=b1.sid
join course c1 on c1.id=b1.cid
where c.name='语文' and c1.name='数学' and b.score <b1.score;
//
select a.id,a.name,a.chinese,b.math from
(select a.id,a.name,b.score chinese from student a
join sc b on a.id =b.sid
join course c on c.id = b.cid
where c.name = '语文') a
join
(select a.id,a.name,b.score math from student a
join sc b on a.id =b.sid
join course c on c.id = b.cid
where c.name = '数学') b
on a.id = b.id
where a.chinese < b.math;
//根据表结构判断是否分组,分组用于按不同条件进行统计
select a.id,a.name,avg(b.score) v from student a join sc b on a.id=b.sid
group by a.id
having v>90;
数据库的优化
随着时间变长,数据库数据越来越多,查询速度越慢;
1.对经常查询的字段添加索引的属性;
索引可以提前把数据存放到内存中,在查询的时候就直接去内存查询,速度快;
2.分表分库
查询慢的一个原因是:一个表里面的数据太多了;
方法:将一个表的数据放到两个表中;将一个数据库中数据放到多个数据库中;















 5924
5924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









