






截图来自李沐老师课件
一、线性回归
线性回归是对n维输入的加权,外加偏差

线性回归可以看作是单层神经网络
使用平方损失来衡量预测值和真实值的差异
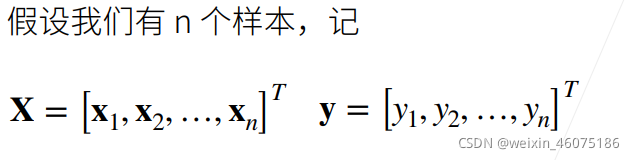
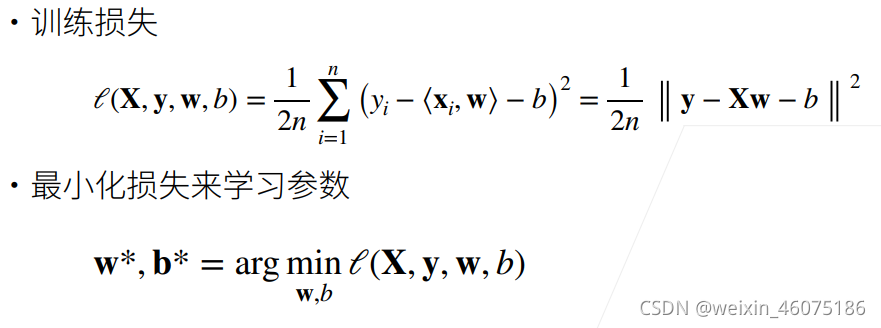

线性回归有显式解
二、基础优化算法
梯度下降通过不断沿着反梯度方向更新参数求解
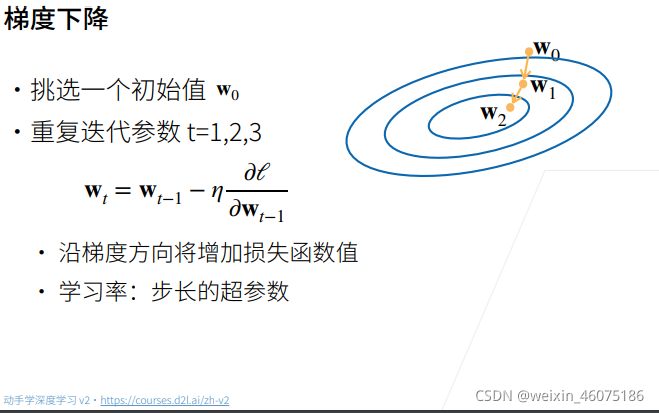
![]() 是学习率,如图圈是等值线,W2处是小值,w0处是大值 ,从w0处沿反梯度方向走
是学习率,如图圈是等值线,W2处是小值,w0处是大值 ,从w0处沿反梯度方向走![]() 大小。
大小。
小批量随机梯度下降是深度学习默认的求解算法

两个重要的超参数是批量大小和学习率
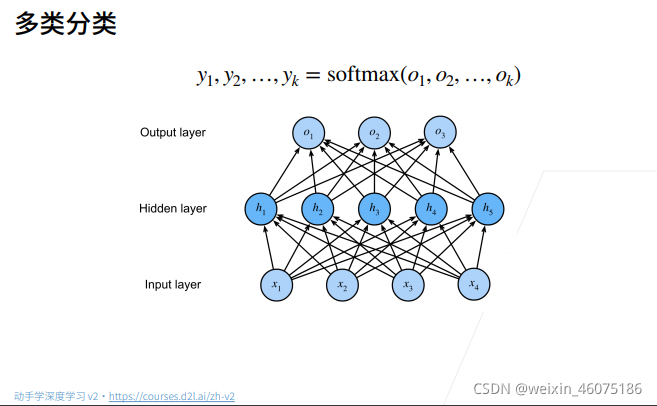
三、softmax
softmax回归是一个多分类模型
假设有一个数组V,V i 表示V中的第i个元素,那么这个元素的softmax值为:

该元素的softmax值,就是该元素的指数与所有元素指数和的比值。
回归vs分类
回归估计一个连续值(例如预测房价)
分类预测一个离散类别(预测是猫还是狗,两类)

将输出值oi当作预测类别是i的置信度,并将值最大的输出所对应的类作为预测输出,即输出 argmaxi oi
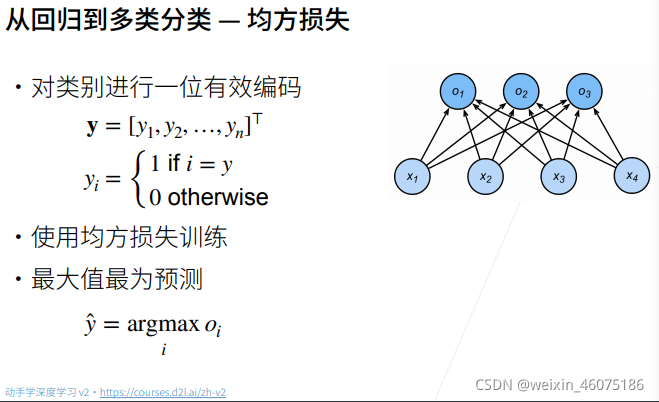
因为更关心正确类的置信度oy远远大于其他非正确类的置信度oi

![]() 是一个阈值
是一个阈值
从回归到多类分类 ----校验比例
输出匹配概率(非负,和为一), 使用softmax操作得到每个类的预测置信度
![]()
o是一个向量
![]()
exp是指数函数,exp(x)只e的x次幂
![]()

因为只有正确类yi为1,其他为0
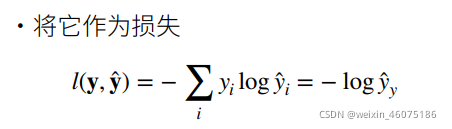

四、损失函数
损失函数衡量预测值与真实值之间的区别
以下的图中y=0
蓝色为损失函数
绿色是损失函数的似然分布
橙色是损失函数的梯度函数
均方损失
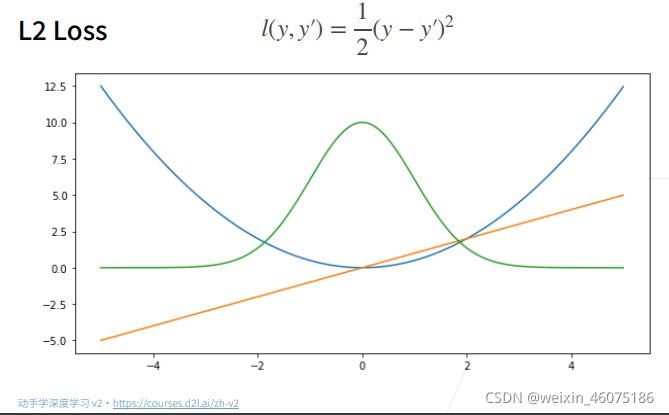
当梯度下降时,我们根据梯度反方向调整参数
由图中看到当真实值与预测值相差较大时(损失函数值大)梯度绝对值也大,当两者相差减小时,梯度绝对值也变小了。
但有时我们并不想要太大的梯度,所以提出了L1 Loss。
绝对值损失
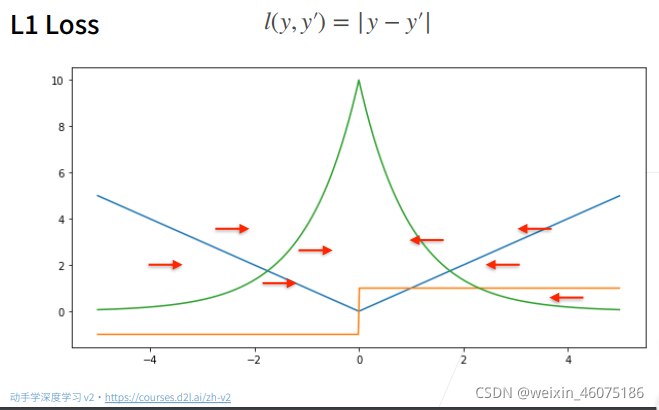
在绝对值损失中,不管预测值与真实值差距有多大,梯度都是一个常数,,但是因为在零点不可导,存在梯度从-1到1的变化,不稳定,在后期预测值与真实值接近的时候会变得不稳定。
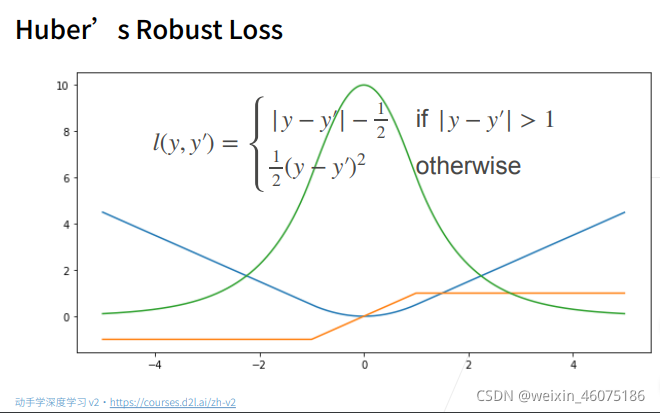
结合了均方损失函数与绝对值损失函数 ,这样在预测值与真实值相差较大时梯度是一个常数,当预测值与真实值相差较小时梯度绝对值也越来越小,保证优化的稳定性。
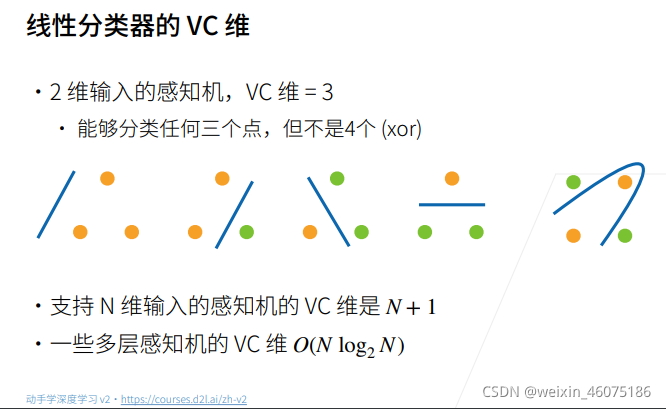
五、感知机
感知机是一个二分类模型,是最早的AI模型之一


一个一个样本进行训练
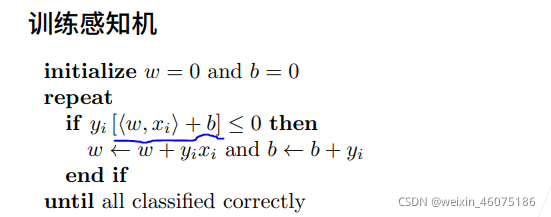
图中蓝色划线部分是预测值 ,yi是标号,-1或0和1,在上一张图中可以看到我们选择的是0,所以,如果感知机预测正确,n那么蓝色部分和yi同号训练下一个样本,否则进入循环。
因为一个样本一个样本的进行训练,所以等价于使用批量为1的梯度下降,使用如下的损失函数
![]()
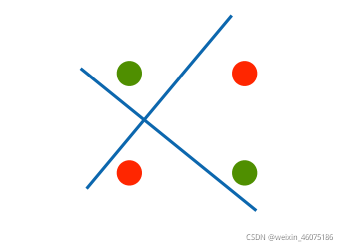
XOR问题
感知机不能拟合XOR函数,只能产生线性分割面。
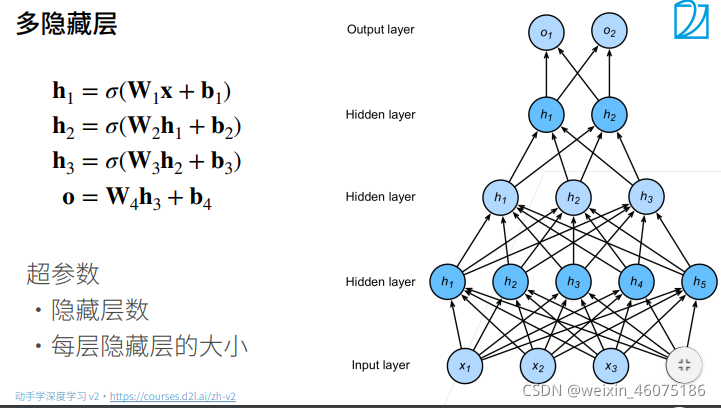
六、多层感知机
多层感知机使用隐藏层和激活函数来得到非线性模型
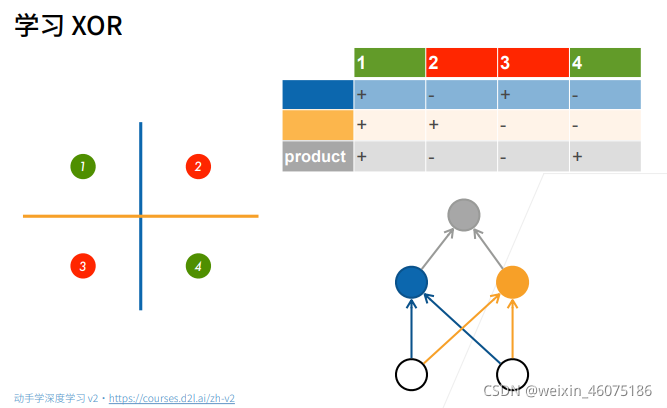
先进性蓝色线,再进行橙色线,对于两者结果相同为正,不同为负解决XOR问题
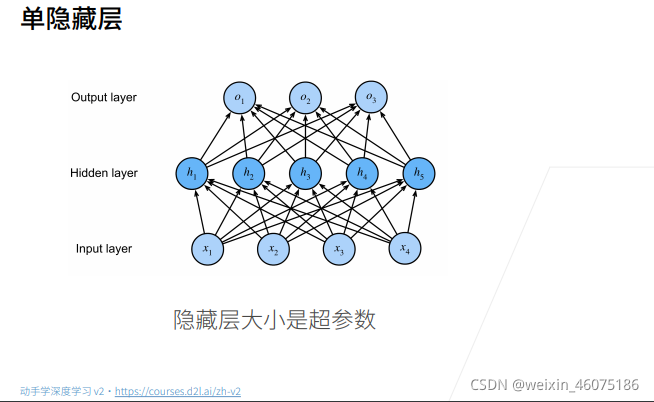
单分类最终输出结果是一个标量
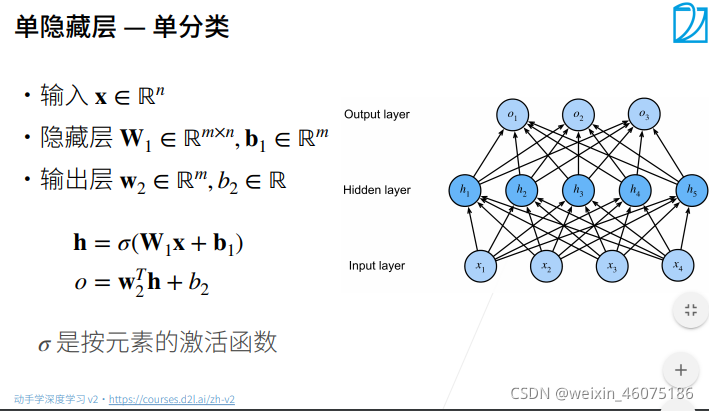
σ是一个非线性函数,因为是线性函数的话,计算如下:

结果仍然是线性的,与单层感知机没有区别。
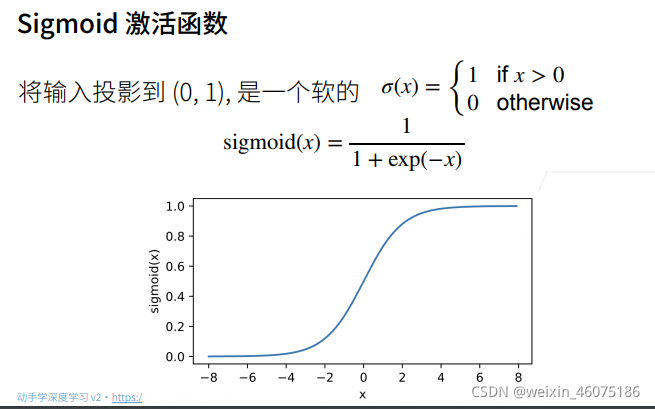

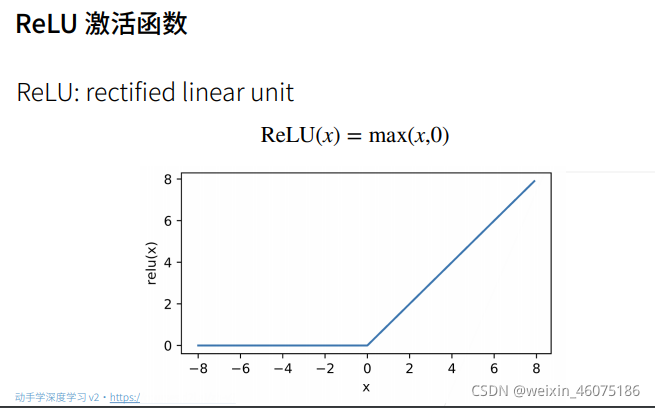
使用softmax来处理多分类
多分类最后输出结果是一个k维向量

七、模型选择
训练误差和泛化误差
训练误差:模型在训练数据上的误差
泛化误差:模型在新数据上的误差

训练数据集:训练模型参数
验证数据集:选择模型超参数

八、欠拟合和过拟合
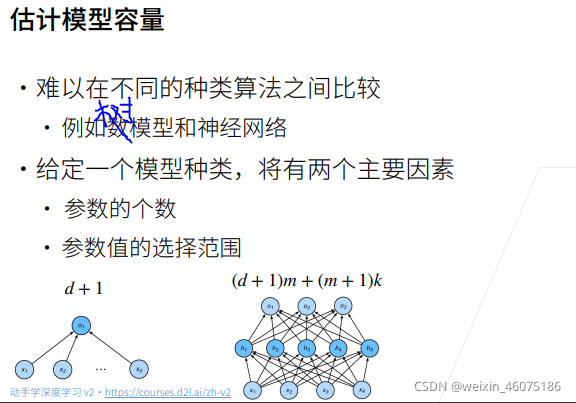
模型容量(模型复杂度)需要匹配数据复杂度,否则可能导致欠拟合和过拟合。

模型容量
模型容量拟合各种函数的能力
低容量的模型难以拟合训练数据
高容量的模型可以记住所有的训练数据

在图中可以看到,在模型容量低的时候,误差大,是欠拟合;随着模型容量变大,误差减少,直到达到最优,之后泛化误差增大(因为拟合能力变强,关注过多不必要的细节),训练误差仍在减小。我们的目的就是在最优点将泛化误差减小并减小泛化误差和训练误差之间的差距。



九、权重衰减
权重衰减是一种降低过拟合的方法
控制模型容量的两个方法:参数个数、参数值选择范围。


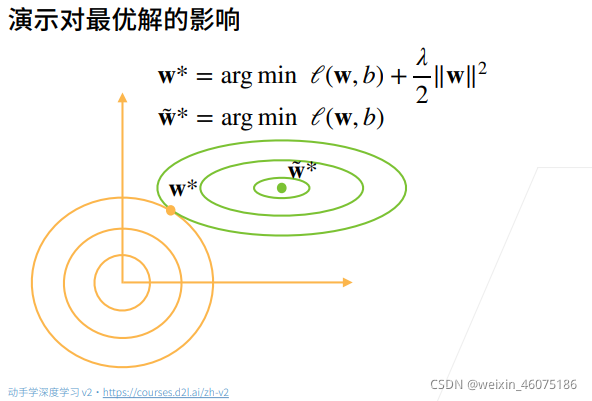
如上所示,w˜ *是原本的取得最小损失的最优解,加入阀之后,在图上阀的表示是最优解在原点的等值线图,为得到w*(使用均方范数为柔性限制后的目标函数的最优解),调整w的取值。在绿色圈范围内,阀对函数结果影响大(因为在越接近原目标函数最优解,梯度越小),在橙色范围内原函数对结果影响大,所以会有一个点正正好。
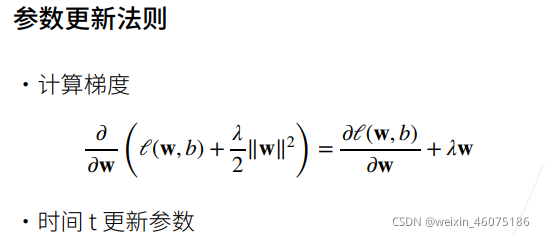
wt+1 = wt-η![]() 将上式带入得
将上式带入得
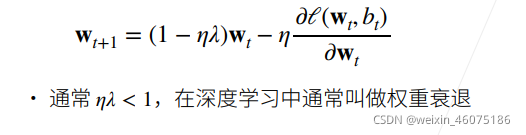
因为比之前多了ηλ所以减小了权重,所以叫权重衰退。
十、Dropout
降低过拟合的一种方法

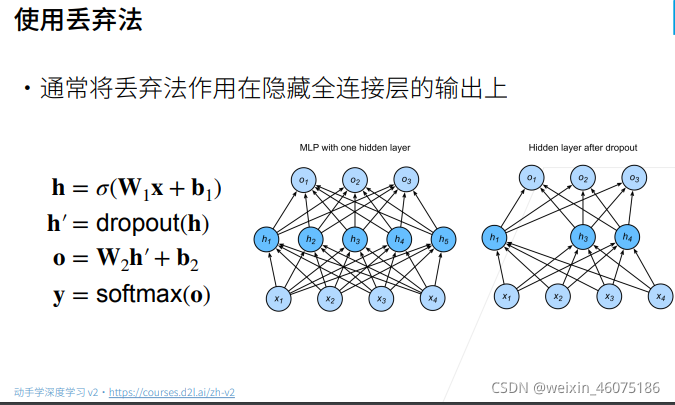
丢弃法不是在输入加入噪音,二十在层间加入噪音。上图隐含丢弃法是一种正则。
丢弃法通过将一些输出项随机置0来控制模型复杂度。

期望不变是因为E[x′] =0*p+[x/(1-p)]*(1-p)=x
丢弃法对元素的扰动是对p概率的元素换为0,对剩下元素增大。丢弃概率p是控制模型复杂度的超参数。
丢弃法常作用于多层感知机的隐藏层输出上。

十一、数值稳定性

数值稳定性常见的两种问题:梯度爆炸和梯度消失



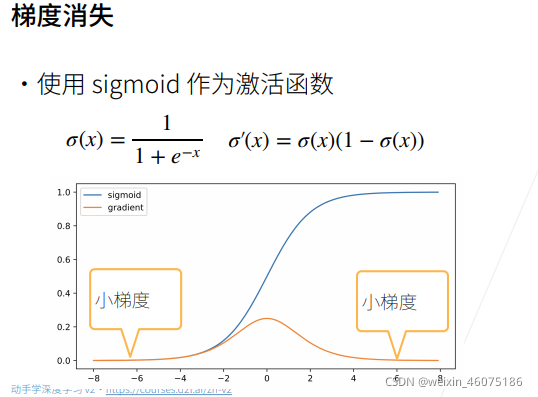
上图中橙色线是梯度函数线,蓝色是函数线,由图中可以看到数值稍大就会导致梯度接近于0.
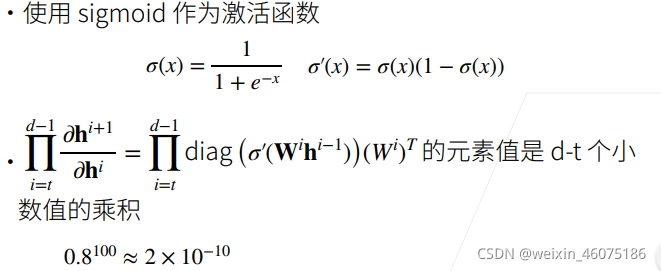

十二、模型初始化和激活函数




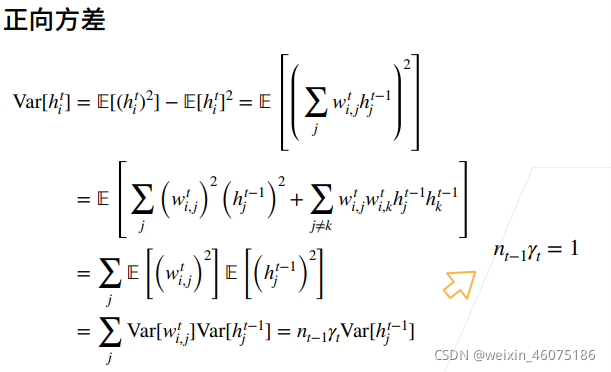




我的问题:
数学不太好,对于很多求导和数学计算会不明白
不明白红色划线部分什么意思,什么约束















 1225
1225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









