






索引定义:
索引是为了快速检索和定位数据行而创建的一种数据结构。
索引在逻辑上和物理上都与相关的表的数据无关,作为无关的结构,索引需要存储空间。创建或删除一个索引,不会影响基本的表、数据库应用或其他索引。当插入、更改和删除相关的表的行时,DM8 会自动管理索引。如果删除索引,所有的应用仍继续工作,但访问以前被索引了的数据时速度可能会变慢。
索引分类
1、聚集索引和非聚集索引
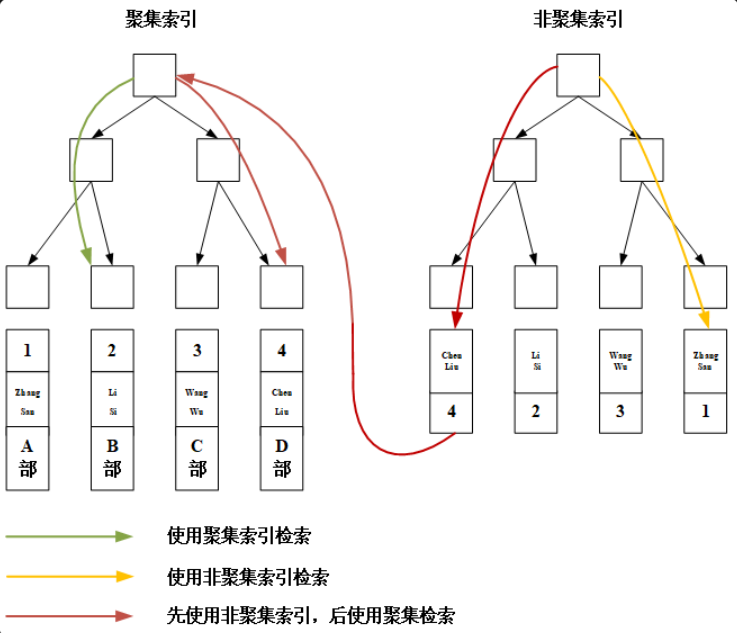
聚集索引(一级索引,主索引):聚集索引就是按照聚集索引键构造一棵 B+ 树,表数据存储在 B+ 树叶子节点上,通过定位索引可直接在 B+ 树中找到数据。每一个表有且只有一个聚集索引。
新建聚集索引会重建这个表以及其所有索引,包括二级索引、函数索引,是一个代价非常大的操作。因此,最好在建表时就确定聚集索引键,或在表中数据比较少时新建聚集索引,而尽量不要对数据量非常大的表建立聚集索引。
非聚集索引(又称为二级索引、辅助索引):将二级索引列和聚集索引列共同存储在 B+ 树叶子节点上。如果查找非聚集索引键值或聚集索引键值可直接在 B+ 树中找到;如果查找索引键值以外的数据,则需要回到一级索引中进行查找。每一个表可以有多个非聚集索引。
创建聚集索引sql:
CREATE CLUSTER INDEX idxname ON tablename (columname);
CREATE CLUSTER INDEX idxid ON test (id);
创建非聚集索引:
CREATE INDEX idxname ON tablename(columname);
CREATE INDEX idxuser ON teest(user);
2、功能索引
从索引功能区分,可分为唯一索引、函数索引、位图索引、位图连接索引、全文索引、空间索引、数组索引、普通索引。
● 唯一索引:索引数据根据索引键唯一;
● 函数索引:包含函数/表达式的预先计算的值;
● 位图索引:对低基数的列创建位图索引;
● 位图连接索引:针对两个或者多个表连接的位图索引,主要用于数据仓库中;
● 全文索引:在表的文本列上而建的索引。具体内容请参考第 18 章;
● 空间索引:在空间数据上创建的索引,专用于 DMGEO 包中;
● 数组索引:在一个只包含单个数组成员的对象列上创建的索引;
● 普通索引:除了唯一索引、函数索引、位图索引、位图连接索引、全文索引、空间索引、数组索引以外的索引,均为普通索引。
3、虚实索引
● 虚索引:创建 PRIMARY KEY 主键约束或 UNIQUE 唯一约束时,系统会自动创建一个相关的唯一索引。因为不需要用户创建,因此称为虚索引。系统创建即虚索引
● 实索引:虚索引以外的索引均为实索引。
4、单索引和复合索引
● 单列索引:只有一个索引键的索引。
● 复合索引:含有多个索引键的索引。
5、全局索引和局部索引
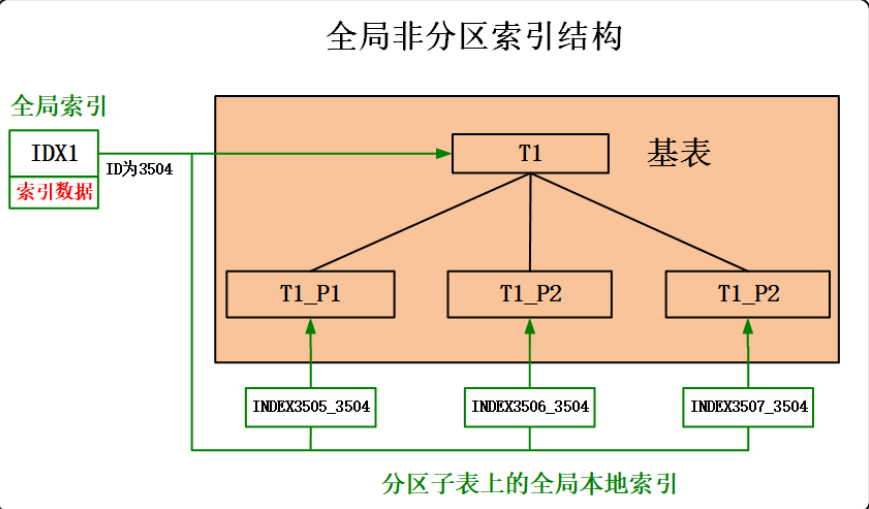
● 全局索引:全局索引是以整张表的数据为对象而建立的索引。
指定 GLOBAL 关键字创建的索引即为全局索引。
全局本地索引的命名规则为:INDEX+ 全局本地索引 ID_全局索引 ID。例如:全局索引 IDX1 的 ID 为 3504,全局本地索引的 ID 为 3506,那么全局本地索引的名称为 INDEX3506_3504。
全局索引具体分为两种:全局非分区索引和全局分区索引。指定了 <PARTITION 子句 > 的索引即为分区索引。只有 DMDPC 功能支持分区索引。
创建表 :
create table t1(c1 int, c2 int, c3 int) partition by range(c1)
(
partition p1 values less than(100),
partition p2 values less than(200),
partition p3 values less than(maxvalue)
);
创建全局分区索引 :
create index idx1 on t1(c2) global;
全局分区索引专门用于 DMDPC 环境中
分区子索引的命名规则为:全局索引名_索引分区名。例如:全局索引名称为 IDX1,索引分区名为 P1、P2,那么分区子索引名称为 IDX1_P1 和 IDX1_P2。
分区子索引是全局分区索引的组成部分,使用全局索引即可使用到分区子索引。不支持单独使用分区子索引进行查询。

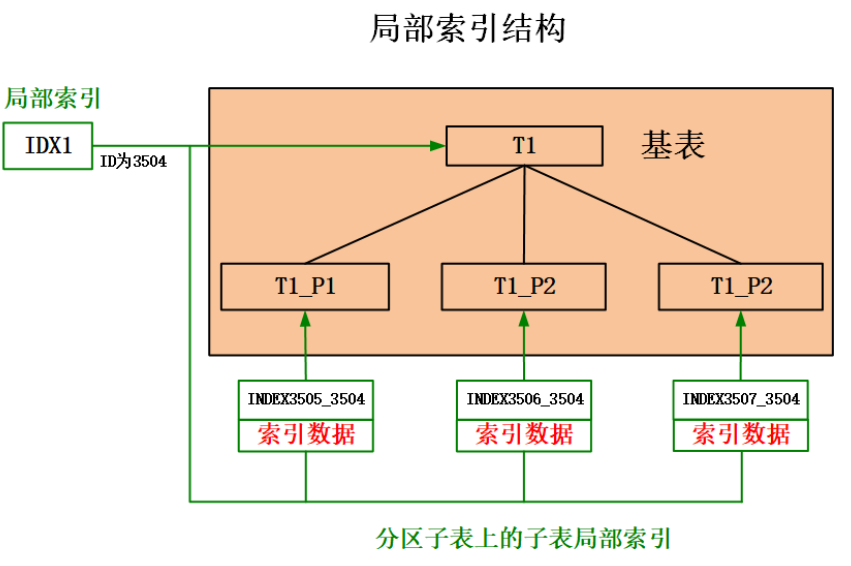
局部索引:局部索引是在分区表的每个分区上创建的索引。
未指定 GLOBAL 关键字创建的索引即为局部索引,创建局部索引时,会在水平分区表的主表上创建局部索引和在每个子表上创建子表局部索引。索引数据存储在子表局部索引上。
子表局部索引的命名规则为:INDEX+ 子表局部索引 ID_局部索引 ID。例如:局部索引 IDX1 的 ID 为 3504,子表局部索引的 ID 为 3506,那么子表局部索引的名称为 INDEX3506_3504。
创建表:
create table t1(c1 int, c2 int, c3 int) partition by range(c1)
(
partition p1 values less than(100),
partition p2 values less than(200),
partition p3 values less than(maxvalue)
);、
创建局部索引(必须省GLOBAL关键字):
create index idx1 on t1(c2);
创建索引准则
1、在插入或装载了数据后,为表创建索引。
2、连接查询中,连接字段列创建索引。
3、经常查询的列,高区分度的列建立索引。
4、时间范围等范围查询适合创建索引。
5、CLOB 和 TEXT 只能建立全文索引、BLOB 不能建立任何索引。
6、多字段组合查询,创建组合索引,而非为每个字段创建索引。
7、限制每张表索引数量,避免修改数据时开销过大和占用高存储缺点。
8、索引创建之初,估算索引大小,设置存储参数,提前规划磁盘空间。
9、为每个索引指定表空间。如果表及其索引使用相同的表空间 能更方便地对数据库进行管理。将表及其索引放在不同的表空间(在不同磁盘上)产生的性能比放在相同的表空间更好,因为这样做减少了磁盘竞争。
唯一索引创建和索引删除
例 可以对 emp 表以 ename 列新建唯一索引
CREATE UNIQUE INDEX dept_unique_index ON dept (dname);
索引删除
DROP INDEX indexname ON tablename;
查看索引信息
查看单表
SELECT * FROM SYS.USER_IND_COLUMNS WHERE TABLE_NAME = '表名';
查看详细信息
SELECT * FROM ALL_INDEXES WHERE TABLE_NAME = '表名';
INDEXNAMEl列包含了index_id,后面数字为id
重建索引
一张表经历大量增删改查后,会产生碎片,降低索引效率,重构索引,可以释放碎片空间,重组索引。
例 需要重建索引 emp_name,假设其索引 ID 为 1547892,重建索引语句:
SP_REBUILD_INDEX(SCHEMA_NAME varchar(256), INDEX_ID int);
SP_REBUILD_INDEX('SYSDBA', 1547892);
explain表字段进行说明
名称:计划节点的操作符
附加信息:每个操作符执行的操作
代价:每个操作符花费的时间,这里以数字表示
结果集:每个操作符返回的结果条数
行数据处理长度:执行节点的字节数
描述:对每个操作符的简单描述
explain中操作符说明
1. NSET:结果集收集
NSET 是用于结果集收集的操作符,一般是查询计划的顶层节点,优化工作中无需对该操作符过多关注,一般没有优化空间。
2. PRJT:投影
PRJT 是关系的【投影】 (project) 运算,用于选择表达式项的计算。广泛用于查询,排序,函数索引创建等。优化工作中无需对该操作符过多关注,一般没有优化空间。
3. SLCT:选择
SLCT 是关系的【选择】运算,用于查询条件的过滤。可比较返回结果集与代价估算中是否接近,如相差较大可考虑收集统计信息。若该过滤条件过滤性较好,可考虑在条件列增加索引。
4. AAGR:简单聚集
AAGR 用于没有 GROUP BY 的 COUNT、SUM、AGE、MAX、MIN 等聚集函数的计算。
5. FAGR:快速聚集
FAGR 用于没有过滤条件时,从表或索引快速获取 MAX、MIN、COUNT 值。
6. HAGR:HASH 分组聚集
HAGR 用于分组列没有索引只能走全表扫描的分组聚集,该示例中 C2 列没有创建索引。
7. SAGR:流分组聚集
SAGR 用于分组列是有序的情况下,可以使用流分组聚集,C1 列上已经创建了索引,SAGR2 性能优于 HAGR2。(EXPLAIN SELECTCOUNT(*) FROM T1 GROUPBY C1;)
8. BLKUP:二次扫描 (回表)
BLKUP 先使用二级索引索引定位 rowid,再根据表的主键、聚集索引、rowid 等信息获取数据行中其它列。
9. CSCN:全表扫描
CSCN2 是 CLUSTER INDEX SCAN 的缩写即通过聚集索引扫描全表,全表扫描是最简单的查询,如果没有选择谓词,或者没有索引可以利用,则系统一般只能做全表扫描。全表扫描 I/O 开销较大,在一个高并发的系统中应尽量避免全表扫描。
10. SSEK、CSEK、SSCN:索引扫描
(1)SSEK
SSEK2 是二级索引扫描即先扫描索引,再通过主键、聚集索引、rowid 等信息去扫描表。
(2)CSEK
CSEK2 是聚集索引扫描只需要扫描索引,不需要扫描表,即无需 BLKUP 操作,如果 BLKUP 开销较大时,可考虑创建聚集索引。
(3)SSCN
SSCN 是索引全扫描,不需要扫描表。
11. NEST LOOP:嵌套循环连接
嵌套循环连接是最基础的连接方式,将一张表(驱动表)的每一个值与另一张表(被驱动表)的所有值拼接,形成一个大结果集,再从大结果集中过滤出满足条件的行。驱动表的行数就是循环的次数,将在很大程度上影响执行效率。
连接列是否有索引,都可以走 NEST LOOP,但没有索引,执行效率会很差
适用场景:
- 驱动表有很好的过滤条件
- 表连接条件能使用索引
- 结果集比较小
12. HASH JOIN:哈希连接
哈希连接是在没有索引或索引无法使用情况下大多数连接的处理方式。哈希连接使用关联列去重后结果集较小的表做成 HASH 表,另一张表的连接列在 HASH 后向 HASH 表进行匹配,这种情况下匹配速度极快,主要开销在于对连接表的全表扫描以及 HASH 运算。
13. MERGE JOIN:归并排序连接
归并排序连接需要两张表的连接列都有索引,对两张表扫描索引后按照索引顺序进行归并。















 2430
2430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









