






1 大模型介绍
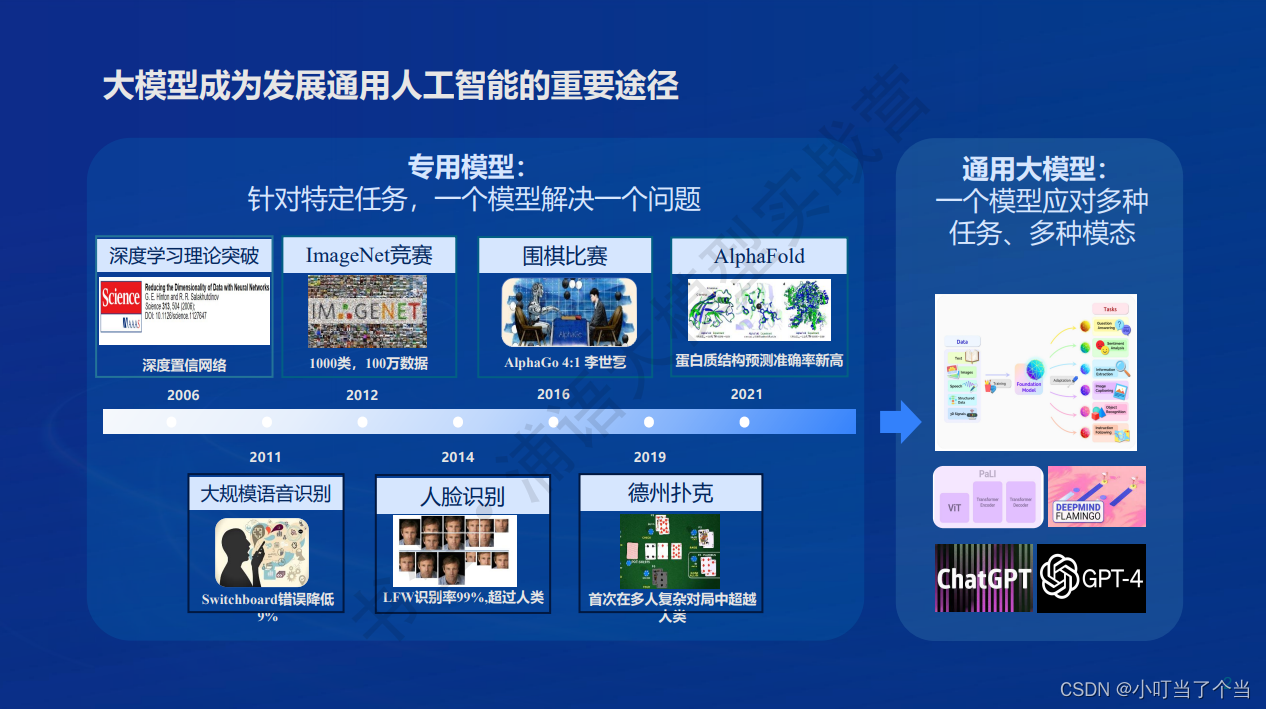
大模型主要分为:专用模型和通用模型
专用模型:针对特定任务,一个模型解决一个问题
通用模型(目前的发展方向):一个模型应对多种任务和多种模态
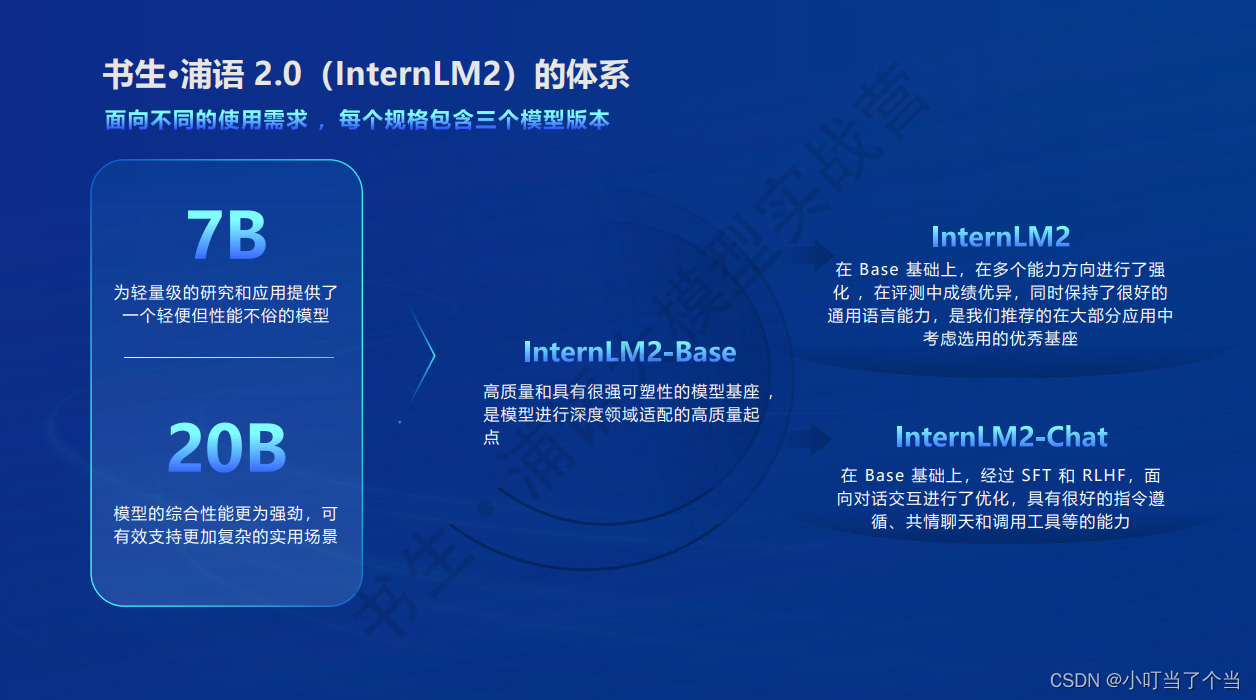
1.1 InternLM2体系
InterLM2包括了7B和20B两个不同的规格,每一个规格都包含了三个模型版本,分别是InternLM-Base、InternLM2、InternLM2-Chat
LLM的本质是在**完成语言建模**这一任务,因此需要高质量的语料库
如何获取? 通过新一代数据清洗过滤技术:
1、多维度数据价值评估
2、高质量语料驱动的数据富集
3、有针对性地数据补齐
1.2 从模型到应用
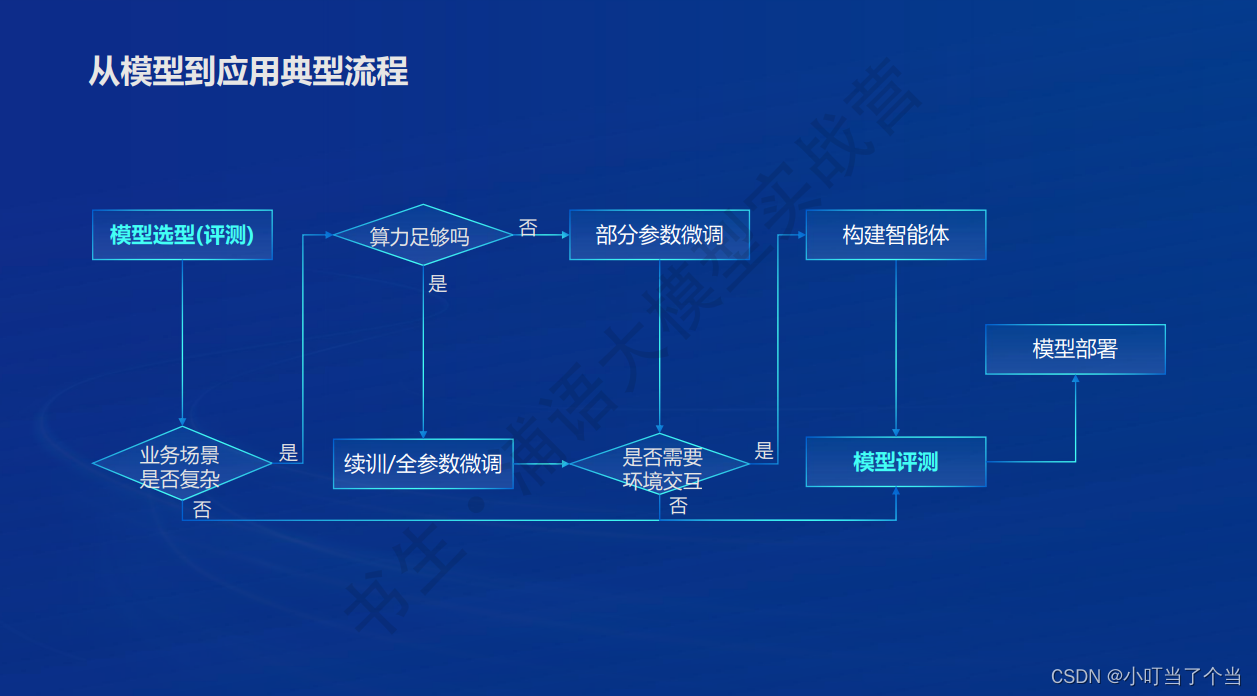
根据业务场景、算力需求、环境交互等不同要求,对选取的模型进行微调,并完成模型的评测和部署
2 书生蒲语全链条开源开放体系

2.1 数据
数据集获取 https://opendatalab.org.cn
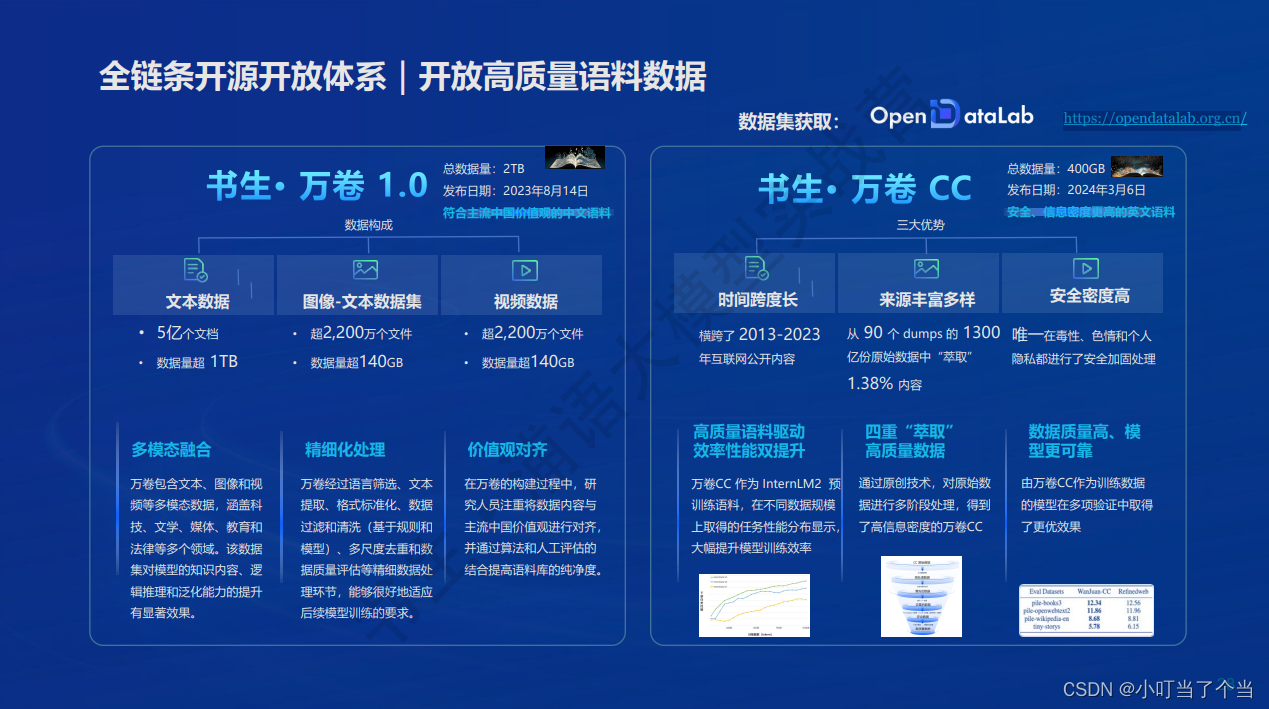
作为训练LLM的训练集必须满足 1.数据量足够大 2.数据分布足够均匀 3. 融合多种模态的数据 并且语料库需要满足主流价值观和法律规定
2.2 预训练
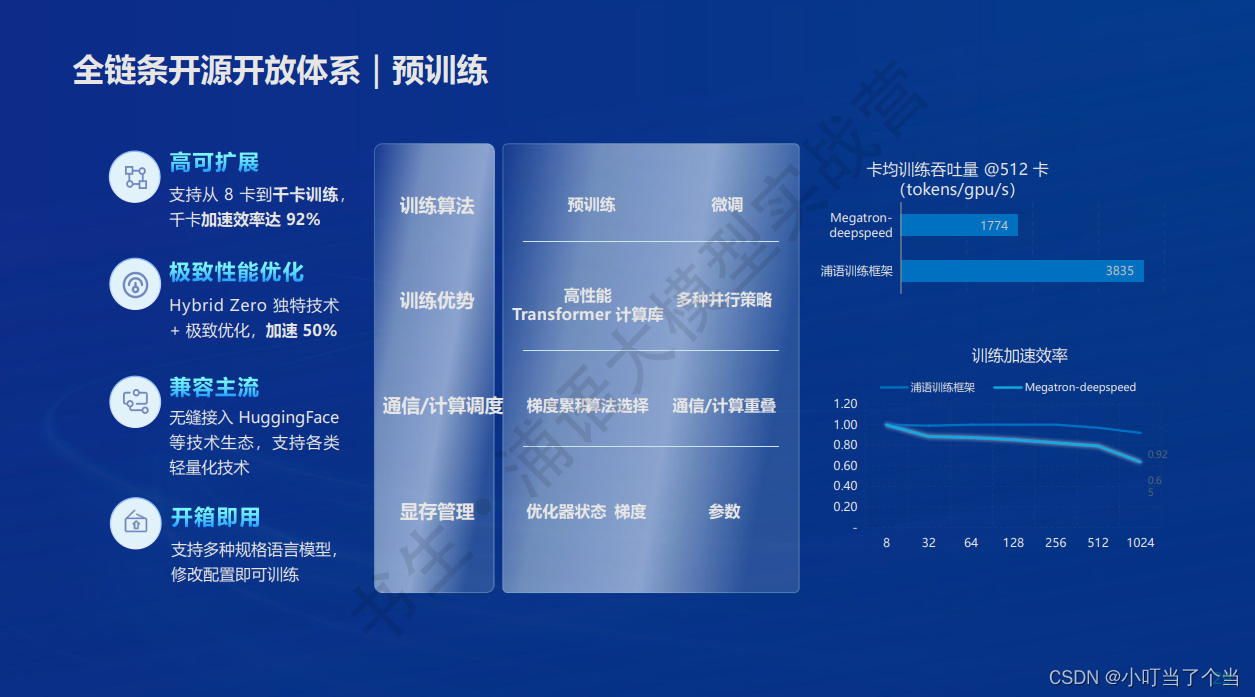
2.3 微调
微调的目的是为了让模型更适合于不同领域的知识需求
针对LLM不同的下游任务,主要有增量续训和有监督微调两种方式:
增量续训:让基座模型学到一些新的知识,比如垂类领域知识(训练数据来源:文章、书籍、代码等)
有监督微调:让模型学会理解各种指令并学会交互式对话,或者注入少量领域知识(训练数据来源:高质量的对话问答数据)
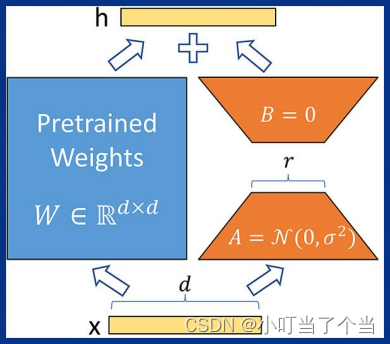
LoRA是一种轻量级微调方法(部分参数微调),通过矩阵的低秩分解来学习到真正重要的参数权重,降低计算开销
InternLM2使用的微调方法是Xtuner,可以适配多种生态(多种微调方法)以及多种硬件
2.4 评测

OpenCompass2.0是一个评测体系,包括了:
Compassrank:中立全面的性能榜单
CompassKit:大模型评测全栈工具链
CompassHub:高质量评测基准社区
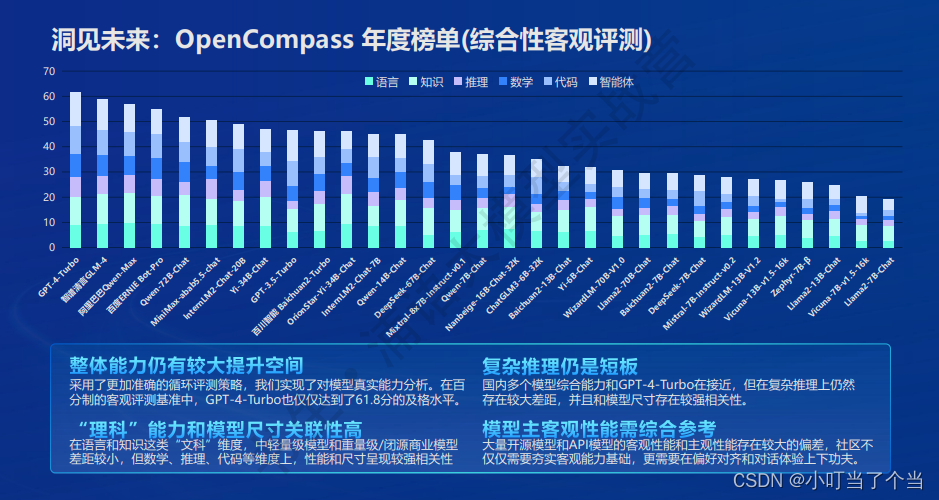
通过对不同LLM的评测,目前还存在一些待提高的方面:
1、整体能力仍有较大提升空间(循环评测策略:随机更换选项顺序,避免猜答案)
2、复杂推理仍然是短板,并且很依赖于模型大小
3、在“理科”推理能力(数学、推理、代码)方面,很依赖于模型大小
4、模型需要提高偏好对齐、对话体验等主观性能
2.5 部署


2.6 智能体(交互应用)
轻量级智能体框架:Lagent



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









