







Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式。
Zookeeper=文件系统+通知机制
1.集群规划,我准备在hrbu30、hrbu31和hrbu32三个节点上部署Zookeeper。
2.解压安装,基于前面我配过本地模式zookeeper,可以参考本地模式的安装与配置,所以我直接在前面的基础上配置分布式模式
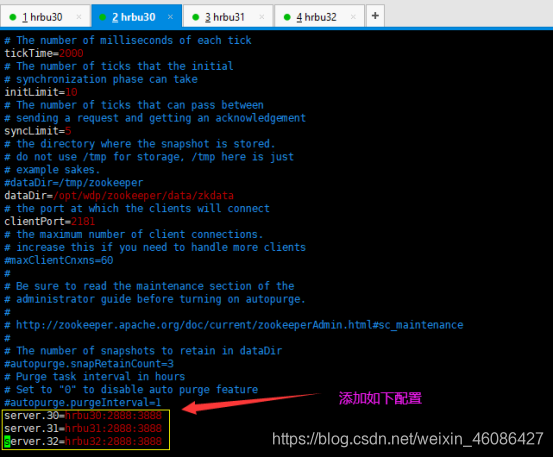
3.配置zoo.cfg文件,增加如下配置
server.30=hrbu30:2888:3888
server.31=hrbu31:2888:3888
server.32=hrbu32:2888:3888
对于上面参数的解释如下
Server.A=B:C:D
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
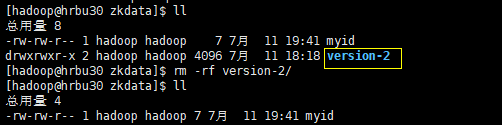
4.集群操作,在/opt/wdp/zookeeper/data/zkdata目录下创建一个myid文件,编辑该文件,在文件中添加与server对应的编号(特别注意如果之前运行过本地模式的zookeeper,会在该目录下产生version-2该文件夹,必须把该文件删除,要不然会报错)
[hadoop@hrbu30 zkdata]$ touch myid
[hadoop@hrbu30 zkdata]$ vi myid
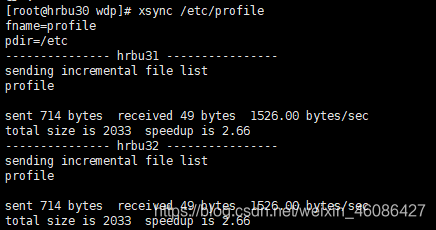
5.把配置好的zookeeper拷贝到其他机器上,另外也可以把环境变量也拷贝到其他机器上(xsync是我之前编辑过的一个shell同步脚本)
[hadoop@hrbu30 wdp]$ xsync zookeeper/
6.修改对应服务器的myid
[hadoop@hrbu31 zkdata]$ vi myid
[hadoop@hrbu32 zkdata]$ vi myid
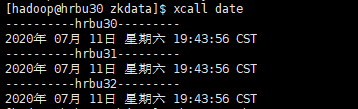
7.zookeeper对时间的同步性要求很高,因此启动zookeeper启动之前建议查看集群内服务器的时间是否同步,如果不同,修改一下
8.之前把环境变量配置过了,因此我们可以在任意目录下启动zookeeper
[hadoop@hrbu30 zkdata]$ zkServer.sh start
[hadoop@hrbu31 zkdata]$ zkServer.sh start
[hadoop@hrbu32 zkdata]$ zkServer.sh start
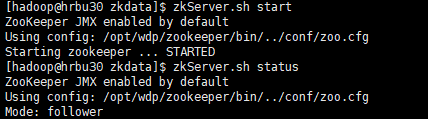
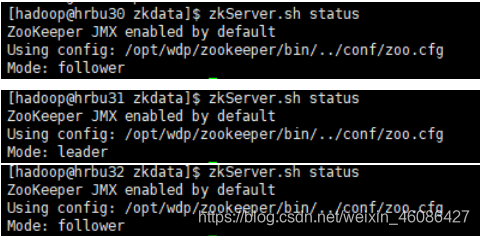
9.查看各个节点的状态(有两个节点状态为follwer,有一个节点为leader,第二个启动的节点的状态为leader)
[hadoop@hrbu30 zkdata]$ zkServer.sh status
[hadoop@hrbu31 zkdata]$ zkServer.sh status
[hadoop@hrbu32 zkdata]$ zkServer.sh status















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









