







1 前期准备
1 获取爬取页面的URL地址
打开谷歌浏览器,打开手机版豆瓣电视剧,在分类中找到美剧豆瓣美剧,打开开发者模式。
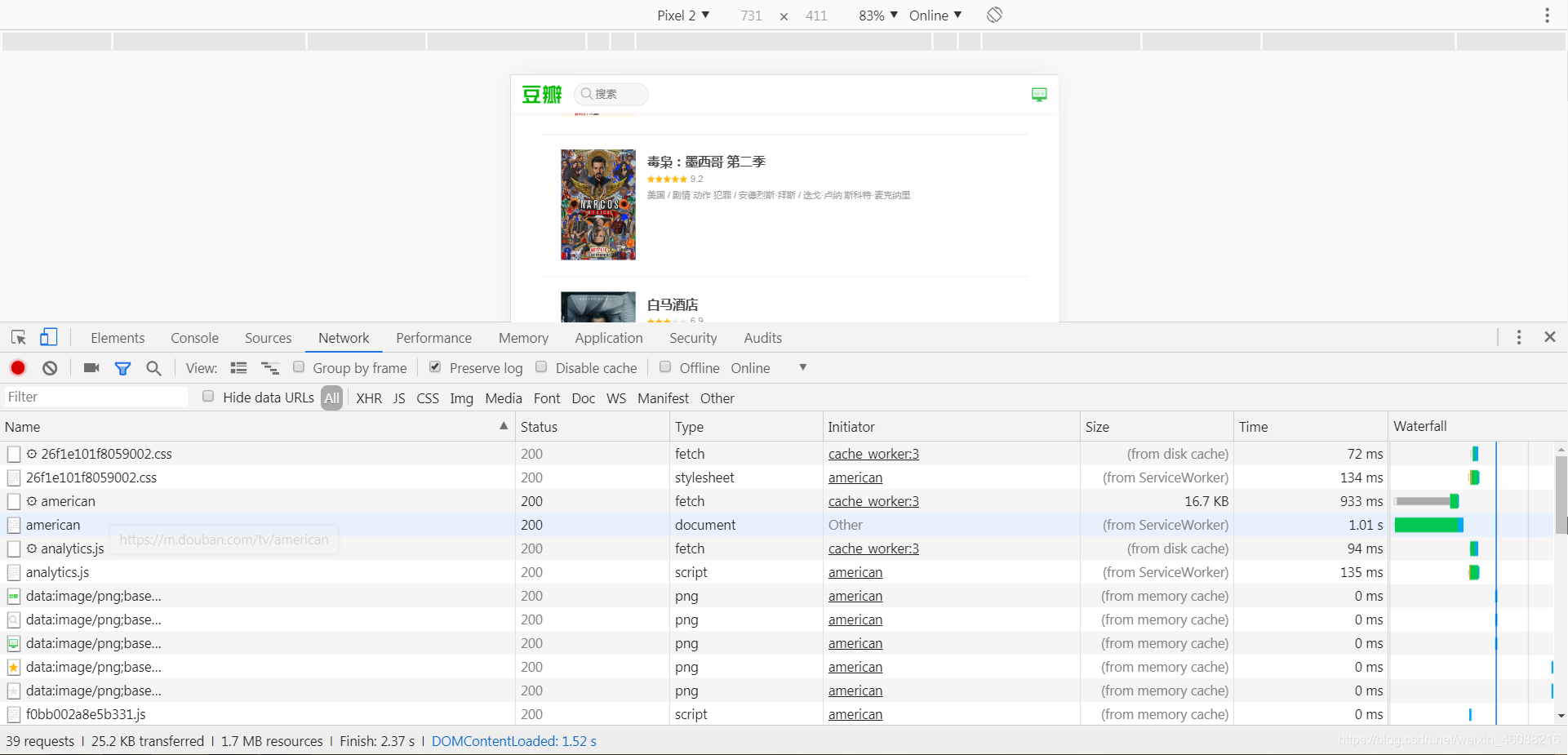
为了找到页面响应真正的url地址,我们需要在Network这里查找。可以看到Network下面有很多条目,这里对于里面的css、js和图片等文件,我们可以不用管。从上往下查找,找到如图所示的item开头的一行。
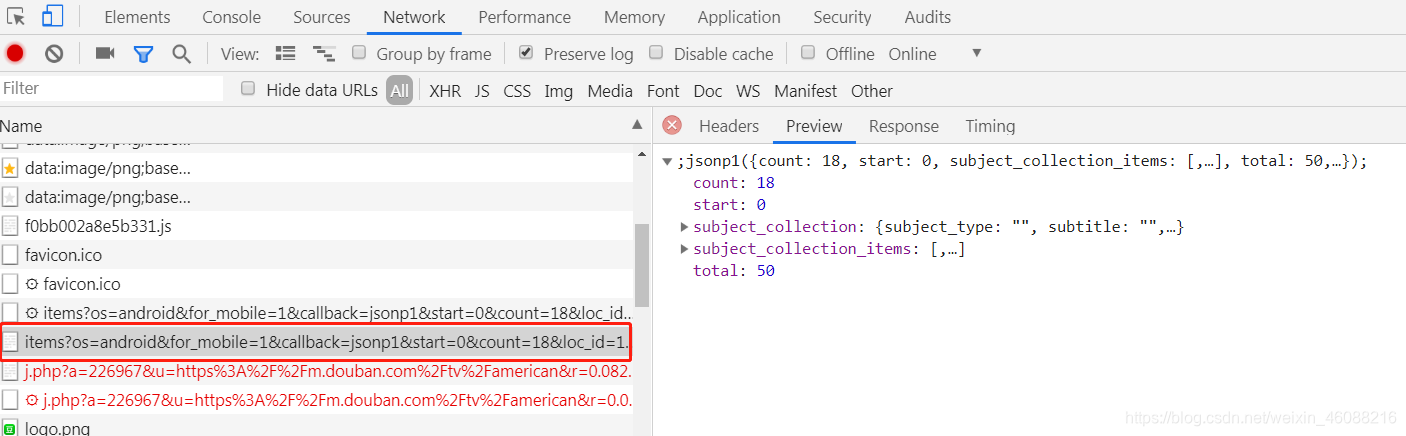
为了确定我们找到的这个条目是我们所需要的,我们可以根据网页上的内容在preview和response等处进行查找,若成功查找到,则证明我们找到了正确的相应地址。
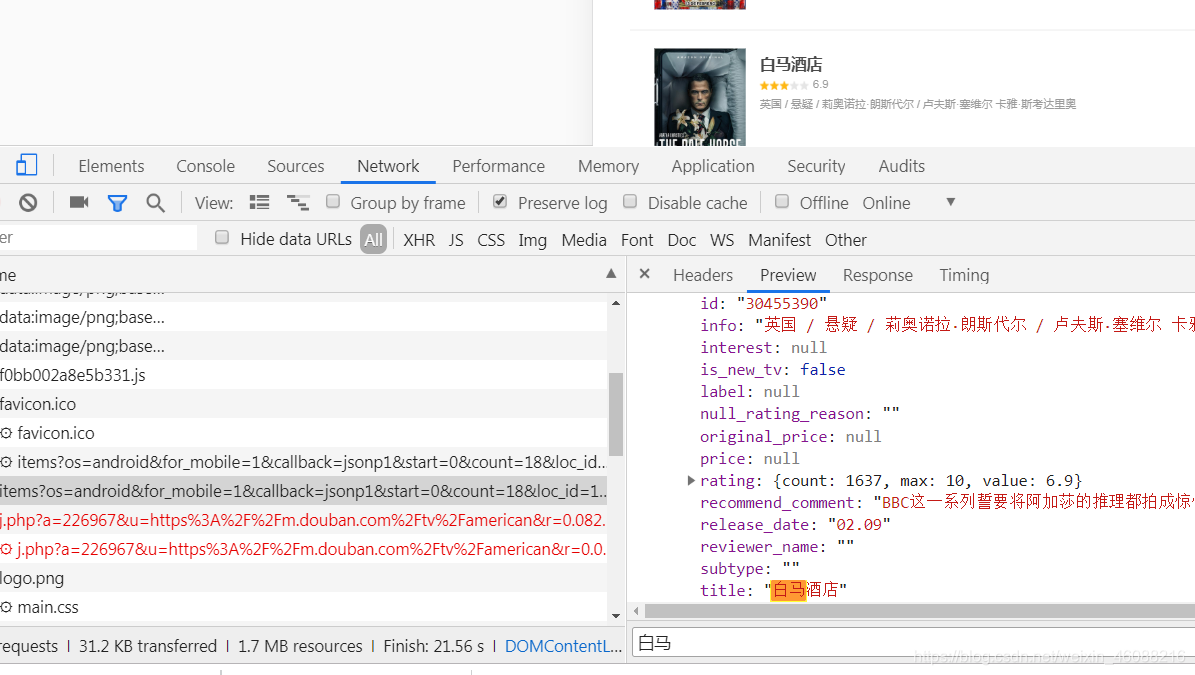
接着我们打开Headers标签:
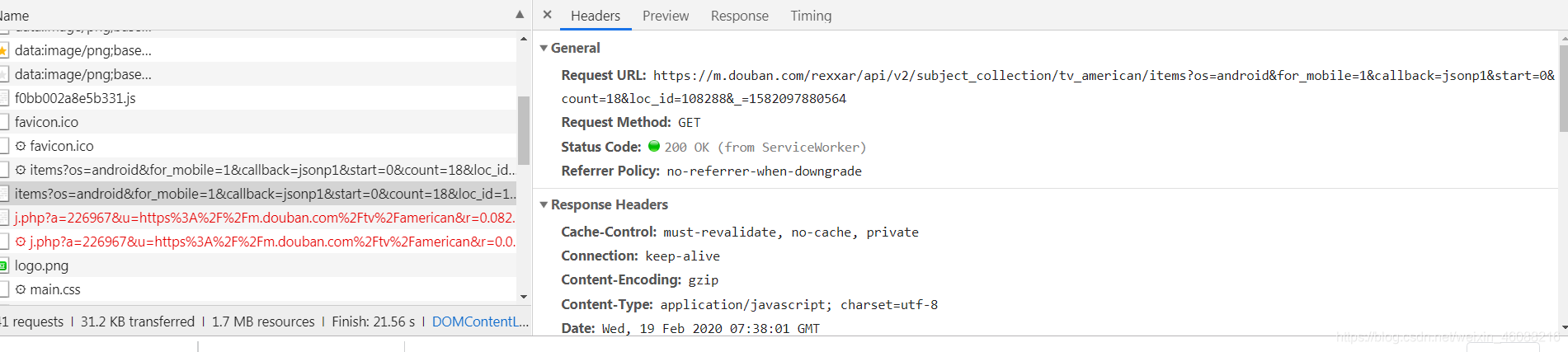

可以看到这里有我们需要的url地址和相关的Requests Headers。
这里URL= https://m.douban.com/rexxar/api/v2/subject_collection/tv_american/items?os=android&for_mobile=1&callback=jsonp1&start=0&count=18&loc_id=108288&_=1582097880564
此处的url进行化简,删去部分不影响的部分(此次测试,删去后程序才能正常运行):
URL= https://m.douban.com/rexxar/api/v2/subject_collection/tv_american/items?start=0&count=18&loc_id=108288
接着我们拿到User-Agent和Reference
Referer: https://m.douban.com/tv/american
User-Agent: Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36
注意此处的Reference,爬取此处数据的时候缺失这个将会报错。
2 编写代码
import requests
import json
class DoubanSpider():
def __init__(self):
self.url = {
"url_temp": "https://m.douban.com/rexxar/api/v2/subject_collection/tv_american/items?start={}&count=18&loc_id=108288",
"country": "us"}
self.headers = {"Referer": "https://m.douban.com/tv/american",
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Mobile Safari/537.36"
}
def parse_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode()
def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str) # 转化为python字典对象
content_list = dict_ret["subject_collection_items"] # 通过字典的键得到相应的值,从而获取页面数据列表
return content_list
def save_content_list(self, content_list, country): # 保存数据
for content in content_list:
with open('douban_my.txt', 'a', encoding='UTF-8') as f:
content["country"] = country
f.write(json.dumps(content, ensure_ascii=False))
f.write('\n')
print('保存成功')
def run(self): # 实现主要逻辑
num = 0
while True:
# 1、获取第一页url
start_url = self.url["url_temp"].format(num)
# 2、发送请求,获取响应
json_str = self.parse_url(start_url)
# 3、提取数据
content_list = self.get_content_list(json_str)
# # 4、保存
self.save_content_list(content_list, self.url["country"])
# 5、获取第二页url
if len(content_list) < 18: # 判断是否到了最后一页
break
num += 18
if __name__ == '__main__':
doubanspider = DoubanSpider()
doubanspider.run()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









