






drop_duplicates函数是对数据进行去重处理,单列进行处理比较好理解,如果多列如何处理呢?
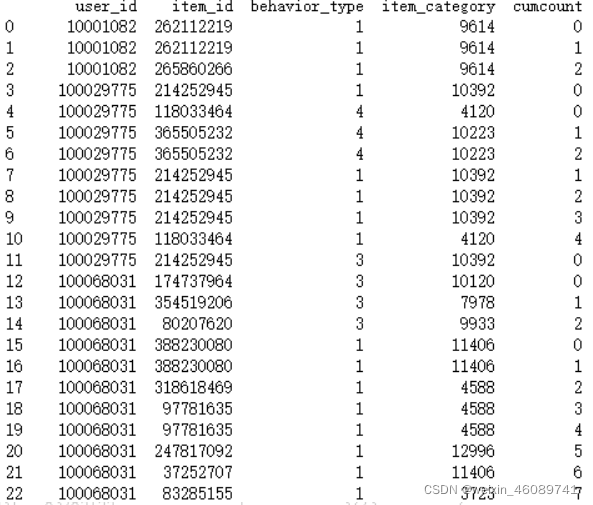
用上述数据表示:简单理解 如果df_part_1.drop_duplicates(['user_id','behavior_type'], 'last')
这句话的意思就是 这两列元素一样的话 就相当于重复(只看这两类 其他列重复不重复没有一点关系) (上图 0 1 2 行就是重复项) 重复了我们就要去重,对吧。那么既然重复这么多 我们最后还是得留下来一个吧 所以最后参数 last 胡总和first就是说 重复这么多项 我只保留最后一项(所以我们把0 1都去重了 只保留了2 这一行) 或者只保留第一项
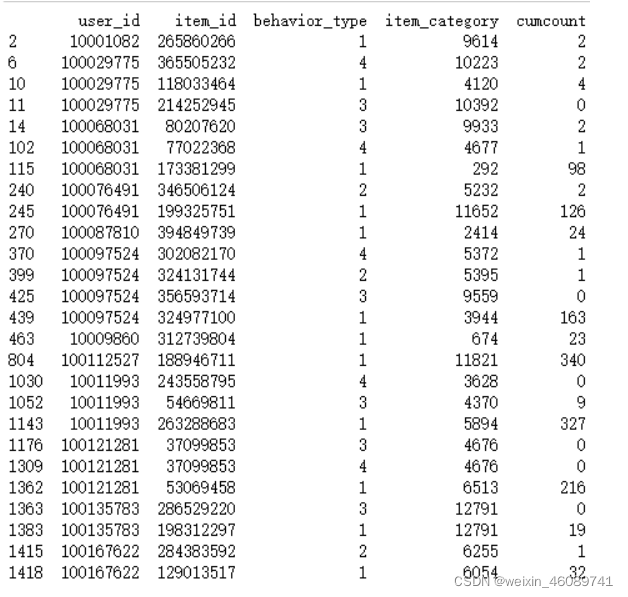
处理后的结果如下图所示 (注意看行的标号)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









