










BAT机器学习面试1000题系列
整理:July、元超、立娜、德伟、贾茹、王剑、AntZ、孟莹等众人。本系列大部分题目来源于公开网络,取之分享,用之分享,且在撰写答案过程中若引用他人解析则必注明原作者及来源链接。另,不少答案得到寒小阳、管博士、张雨石、王赟、褚博士等七月在线名师审校。
说明:本系列作为国内首个AI题库,首发于七月在线实验室公众号上:julyedulab,并部分更新于本博客上,且已于17年双十二当天上线七月在线官网、七月在线Android APP、七月在线iPhone APP,后本文暂停更新和维护,另外的近3000道题都已更新到七月在线APP或七月在线官网题库板块上,欢迎天天刷题。另,可以转载,注明来源链接即可。
前言
July我又回来了。
之前本博客整理过数千道微软等公司的面试题,侧重数据结构、算法、海量数据处理,详见:微软面试100题系列,今17年,近期和团队整理BAT机器学习面试1000题系列,侧重机器学习、深度学习。我们将通过这个系列索引绝大部分机器学习和深度学习的笔试面试题、知识点,它将更是一个足够庞大的机器学习和深度学习面试库/知识库,通俗成体系且循序渐进。
此外,有四点得强调下:
- 虽然本系列主要是机器学习、深度学习相关的考题,其他类型的题不多,但不代表应聘机器学习或深度学习的岗位时,公司或面试官就只问这两项,虽说是做数据或AI相关,但基本的语言(比如Python)、编码coding能力(对于开发,编码coding能力怎么强调都不过分,比如最简单的手写快速排序、手写二分查找)、数据结构、算法、计算机体系结构、操作系统、概率统计等等也必须掌握。对于数据结构和算法,一者 重点推荐前面说的微软面试100题系列(后来这个系列整理成了新书《编程之法:面试和算法心得》),二者 多刷leetcode,看1000道题不如实际动手刷100道。
- 本系列会尽量让考察同一个部分(比如同是模型/算法相关的)、同一个方向(比如同是属于最优化的算法)的题整理到一块,为的是让大家做到举一反三、构建完整知识体系,在准备笔试面试的过程中,通过懂一题懂一片。
- 本系列每一道题的答案都会确保逻辑清晰、通俗易懂(当你学习某个知识点感觉学不懂时,十有八九不是你不够聪明,十有八九是你所看的资料不够通俗、不够易懂),如有更好意见,欢迎在评论下共同探讨。
- 关于如何学习机器学习,最推荐机器学习集训营系列。从Python基础、数据分析、爬虫,到数据可视化、spark大数据,最后实战机器学习、深度学习等一应俱全。
另,本系列会长久更新,直到上千道、甚至数千道题,欢迎各位于评论下留言分享你在自己笔试面试中遇到的题,或你在网上看到或收藏的题,共同分享帮助全球更多人,thanks。
限于篇幅,完整版可以扫码领取,添加时备注:领取面经100篇

BAT机器学习面试1000题系列
111 请对比下Sigmoid、Tanh、ReLu这三个激活函数。深度学习 DL基础 中
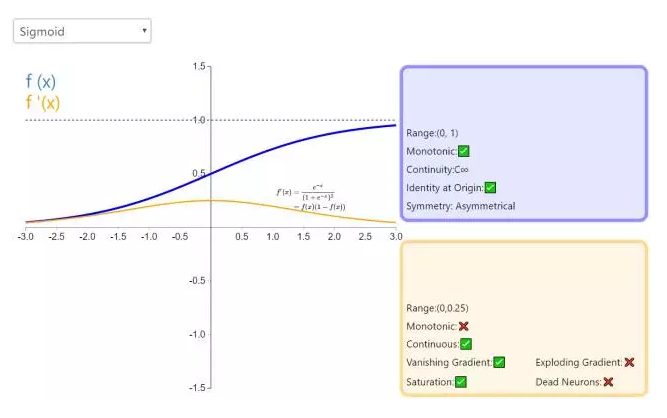
sigmoid函数又称logistic函数,应用在Logistic回归中。logistic回归的目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
假设函数
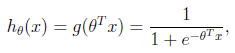
其中x是n维特征向量,函数g就是logistic函数。
而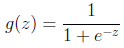 的图像是
的图像是
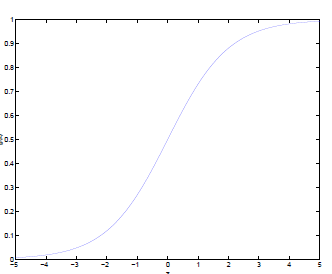
可以看到,将无穷映射到了(0,1)。
而假设函数就是特征属于y=1的概率。
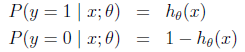
从而,当我们要判别一个新来的特征属于哪个类时,只需求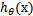 即可,若大于0.5就是y=1的类,反之属于y=0类。
即可,若大于0.5就是y=1的类,反之属于y=0类。
更多详见:https://mp.weixin.qq.com/s/7DgiXCNBS5vb07WIKTFYRQ
所以,sigmoid函数将输出映射到0-1范围之间,可以被看做是概率,因而,sigmoid函数是Logstic回归模型的激活函数。
但sigmoid函数有如下几个缺点:
正向计算包含指数,反向传播的导数也包含指数计算和除法运算,因而计算复杂度很高。
输出的均值非0。这样使得网络容易发生梯度消失或梯度爆炸。这也是batch normalization要解决的问题。
假如sigmoid函数为f(x),那么f'(x)=f(x)(1-f(x)),因为f(x)输出在0-1之间,那么f'(x)恒大于0。 这就导致全部的梯度的正负号都取决于损失函数上的梯度。这样容易导致训练不稳定,参数一荣俱荣一损俱损。
同样的,f'(x)=f(x)(1-f(x)),因为f(x)输出在0-1之间,那么f'(x)输出也在0-1之间,当层次比较深时,底层的导数就是很多在0-1之间的数相乘,从而导致了梯度消失问题。
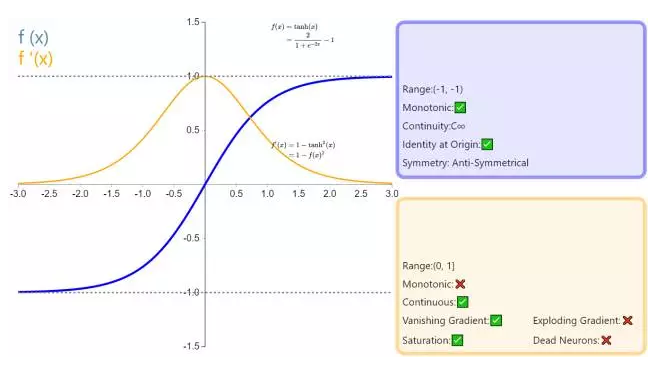
对于tanh来说,同sigmoid类似,但是输出值在-1到1之间,均值为0,是其相对于sigmoid的提升。但是因为输出在-1,1之间,因而输出不能被看做是概率。
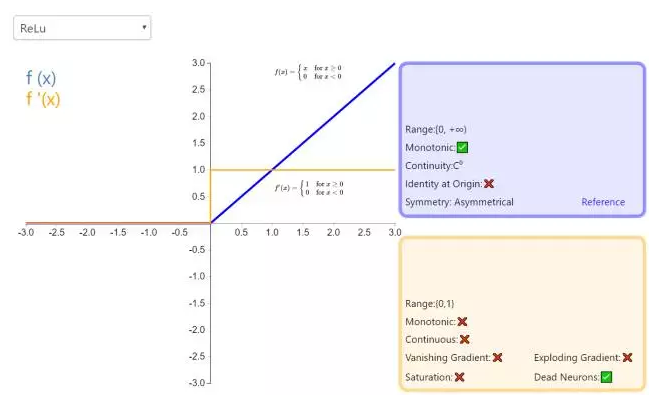
对于ReLU来说,相对于sigmoid和tanh来说,有如下优点:
计算量下,没有指数和除法运算。
不会饱和,因为在x>0的情况下,导数恒等于1
收敛速度快,在实践中可以得知,它的收敛速度是sigmoid的6倍。
Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
但是Relu也有缺点,缺点在于,
如果有一个特别大的导数经过神经单元使得输入变得小于0,这样会使得这个单元永远得不到参数更新,因为输入小于0时导数也是0. 这就形成了很多dead cell。
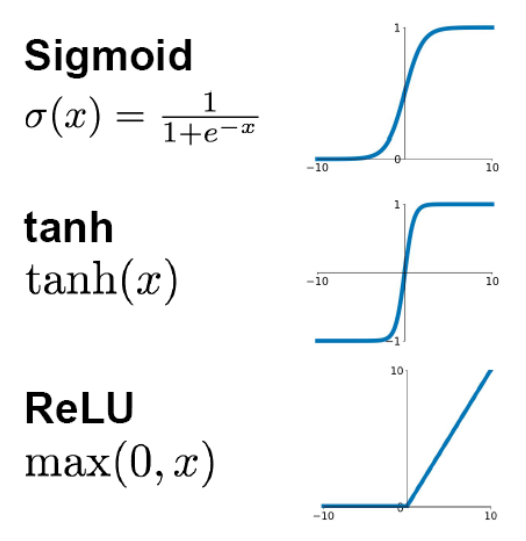
112 Sigmoid、Tanh、ReLu这三个激活函数有什么缺点或不足,有没改进的激活函数。深度学习 DL基础 中
@张雨石:sigmoid、Tanh、ReLU的缺点在121问题中已有说明,为了解决ReLU的dead cell的情况,发明了Leaky Relu, 即在输入小于0时不让输出为0,而是乘以一个较小的系数,从而保证有导数存在。同样的目的,还有一个ELU,函数示意图如下。
还有一个激活函数是Maxout,即使用两套w,b参数,输出较大值。本质上Maxout可以看做Relu的泛化版本,因为如果一套w,b全都是0的话,那么就是普通的ReLU。Maxout可以克服Relu的缺点,但是参数数目翻倍。
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
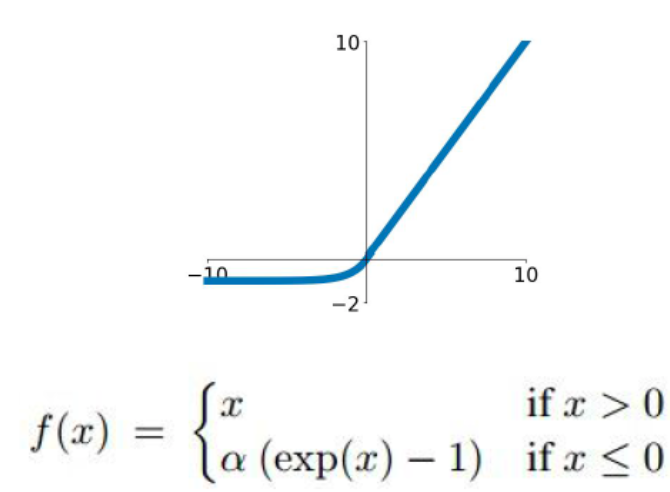
113 怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感。机器学习 ML模型 中
https://www.zhihu.com/question/58230411
114 为什么引入非线性激励函数?深度学习 DL基础 中
@张雨石:第一,对于神经网络来说,网络的每一层相当于f(wx+b)=f(w'x),对于线性函数,其实相当于f(x)=x,那么在线性激活函数下,每一层相当于用一个矩阵去乘以x,那么多层就是反复的用矩阵去乘以输入。根据矩阵的乘法法则,多个矩阵相乘得到一个大矩阵。所以线性激励函数下,多层网络与一层网络相当。比如,两层的网络f(W1*f(W2x))=W1W2x=Wx。
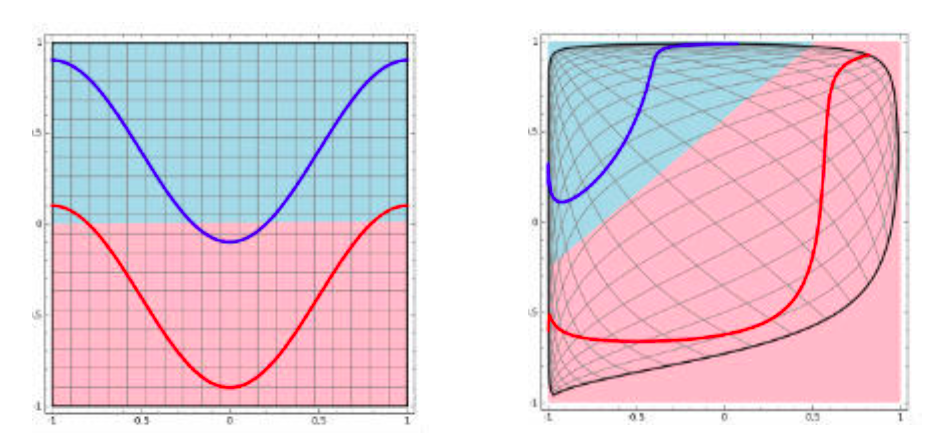
第二,非线性变换是深度学习有效的原因之一。原因在于非线性相当于对空间进行变换,变换完成后相当于对问题空间进行简化,原来线性不可解的问题现在变得可以解了。
下图可以很形象的解释这个问题,左图用一根线是无法划分的。经过一系列变换后,就变成线性可解的问题了。
@Begin Again,来源:https://www.zhihu.com/question/29021768
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。
正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释)。
115 请问人工神经网络中为什么ReLu要好过于tanh和sigmoid function?深度学习 DL基础 中
先看sigmoid、tanh和RelU的函数图:
@Begin Again,来源:https://www.zhihu.com/question/29021768
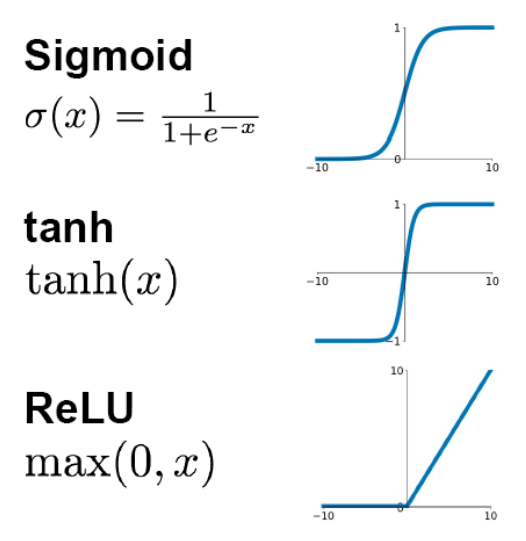
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),这种现象称为饱和,从而无法完成深层网络的训练。而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
多加一句,现在主流的做法,会多做一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。
[1] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
[2] He, Kaiming, et al. "Identity Mappings in Deep Residual Networks." arXiv preprint arXiv:1603.05027 (2016).
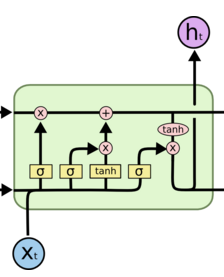
116 为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数?深度学习 DL模型 难
为什么不是选择统一一种sigmoid或者tanh,而是混合使用呢?这样的目的是什么?
本题解析来源:https://www.zhihu.com/question/46197687
@beanfrog:二者目的不一样
sigmoid 用在了各种gate上,产生0~1之间的值,这个一般只有sigmoid最直接了。
tanh 用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以。
@hhhh:另可参见A Critical Review of Recurrent Neural Networks for Sequence Learning的section4.1,说了那两个tanh都可以替换成别的。
117 衡量分类器的好坏?机器学习 ML基础 中
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
这里首先要知道TP、FN(真的判成假的)、FP(假的判成真)、TN四种(可以画一个表格)。
几种常用的指标:
- 精度precision = TP/(TP+FP) = TP/~P (~p为预测为真的数量)
- 召回率 recall = TP/(TP+FN) = TP/ P
- F1值: 2/F1 = 1/recall + 1/precision
- ROC曲线:ROC空间是一个以伪阳性率(FPR,false positive rate)为X轴,真阳性率(TPR, true positive rate)为Y轴的二维坐标系所代表的平面。其中真阳率TPR = TP / P = recall, 伪阳率FPR = FP / N
更详细请点击:https://siyaozhang.github.io/2017/04/04/%E5%87%86%E7%A1%AE%E7%8E%87%E3%80%81%E5%8F%AC%E5%9B%9E%E7%8E%87%E3%80%81F1%E3%80%81ROC%E3%80%81AUC/
118 机器学习和统计里面的auc的物理意义是啥?机器学习 ML基础 中
https://www.zhihu.com/question/39840928
119 观察增益gain, alpha和gamma越大,增益越小?机器学习 ML基础 中
@AntZ:xgboost寻找分割点的标准是最大化gain. 考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中计算Gain按最大值找出最佳的分割点。它的计算公式分为四项, 可以由正则化项参数调整(lamda为叶子权重平方和的系数, gama为叶子数量):
第一项是假设分割的左孩子的权重分数, 第二项为右孩子, 第三项为不分割总体分数, 最后一项为引入一个节点的复杂度损失
由公式可知, gama越大gain越小, lamda越大, gain可能小也可能大.
原问题是alpha而不是lambda, 这里paper上没有提到, xgboost实现上有这个参数. 上面是我从paper上理解的答案,下面是搜索到的:
https://zhidao.baidu.com/question/2121727290086699747.html?fr=iks&word=xgboost+lamda&ie=gbk
lambda[默认1]权重的L2正则化项。(和Ridge regression类似)。 这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。11、alpha[默认1]权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
gamma[默认0]在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。
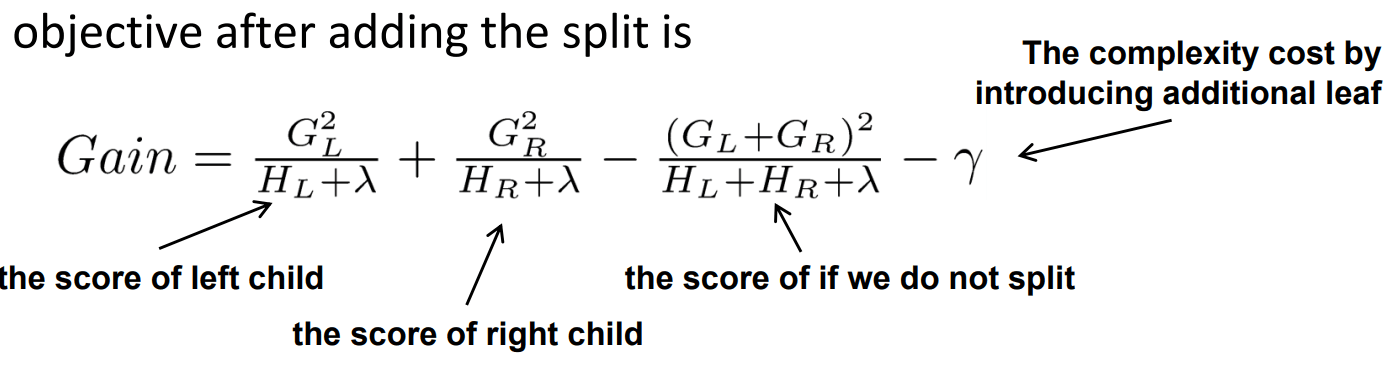
120 什麽造成梯度消失问题? 推导一下。深度学习 DL基础 中
@许韩,来源:https://www.zhihu.com/question/41233373/answer/145404190
- Yes you should understand backdrop-Andrej Karpathy
- How does the ReLu solve the vanishing gradient problem?
- 神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差值,训练普遍使用BP算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相对于每个神经元的梯度,进行权值的迭代。
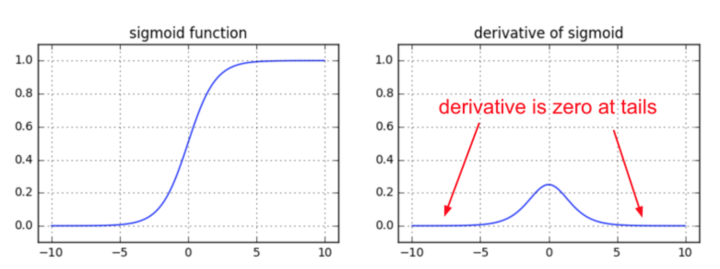
- 梯度消失会造成权值更新缓慢,模型训练难度增加。造成梯度消失的一个原因是,许多激活函数将输出值挤压在很小的区间内,在激活函数两端较大范围的定义域内梯度为0,造成学习停止。
@张雨石:简而言之,就是sigmoid函数f(x)的导数为f(x)*(1-f(x)), 因为f(x)的输出在0-1之间,所以随着深度的增加,从顶端传过来的导数每次都乘以两个小于1的数,很快就变得特别特别小。
后记
熟悉我的朋友可能已经知道,我个人从 2010 年开始在CSDN写博客,写了十年,如今接近1700万PV,创业做「七月在线」则已五年,五年已30多万学员。这五年经历且看过很多的人和事,比如我们的机器学习集训营帮助了超过1000人就业、转型、提升,他们就业后有的同学会分享面经,当看到那一篇篇透露着面经作者本人的那股努力、那股不服输的劲的面经的时候,则让我倍感励志。比如“双非渣本三年 100 次面试经历精选:从最初 iOS 前端到转型面机器学习” 这篇面经,便让我印象非常深刻。在佩服主人公毅力和意志的同时,也对他愿意分享对众多人有着非常重要参考价值和借鉴意义的成功经验倍感欣慰。
当然,类似的面经远远不止于此,后来我们整理出了100篇面经,汇总成册为《名企AI面经100 篇:揭开三个月薪资翻倍的秘诀》,这 100 篇面经分为机器学习、深度学习、 CV、NLP、推荐系统、金融风控、计算广告、数据挖掘/数据分析八大方向。分享面经的作者各种背景都有,比如
- 科班,或非科班;
- 985、211,或双非院校;
- 研究生或本科,甚至大专;
- 学生,或在职;
- 至于传统IT转型 AI 的就更多了,有从 Java、PHP、C、C++等偏后端服务转型的,也有从 Android、iOS、前端等偏客户端开发转型的,当然也有数据分析、大数据方向等转型的。
但令人振奋的是,他们都转型成功了,而且他们中的很多人都通过集训营/就业班三个月到半年的学习,成功实现薪资翻倍——这些成功的经验就更值得借鉴了。
就业部的同事特地将这些宝贵的经验整理出来,希望可以帮到更多人。
限于篇幅,完整版可以扫码领取,添加时备注:领取面经100篇















 2182
2182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









